
采集北京市政百姓信件内容的具体步骤
1、新建一个能够存储数据的文件夹
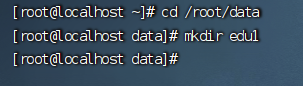

2、进入到edu1文件夹里面,将webmagic所需要的jar包上传上去
(压缩包网址在这里:https://github.com/code4craft/webmagic/releases/tag/WebMagic-0.7.3)
如图所示:

之后将jar包解压:
tar -zxvf webmagic-0.7.3-all.tar.gz
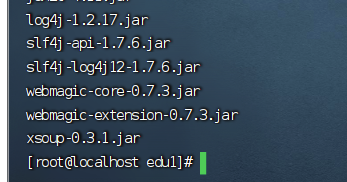
它压缩好之后,是出来了一堆jar包;
3、在Eclipse新建项目
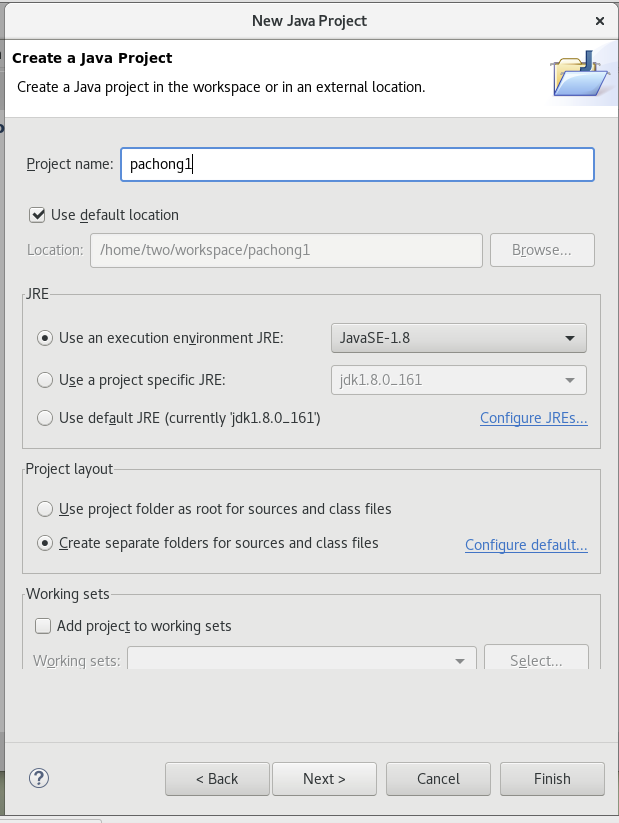
然后next-->finish;
之后,右键pachong1的项目名,新建一个名为libs的文件夹:

4、将解压出来的jar包放置到libs文件夹目录下
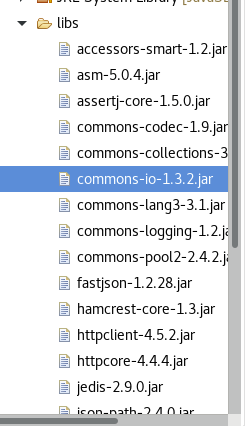
之后选中所有的jar包,进行如下操作:
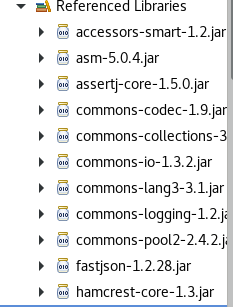
Add Path;
5、新建一个名为my.webmagic的包
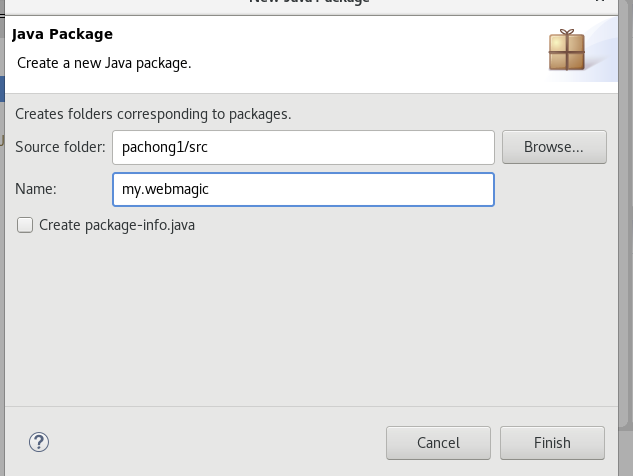
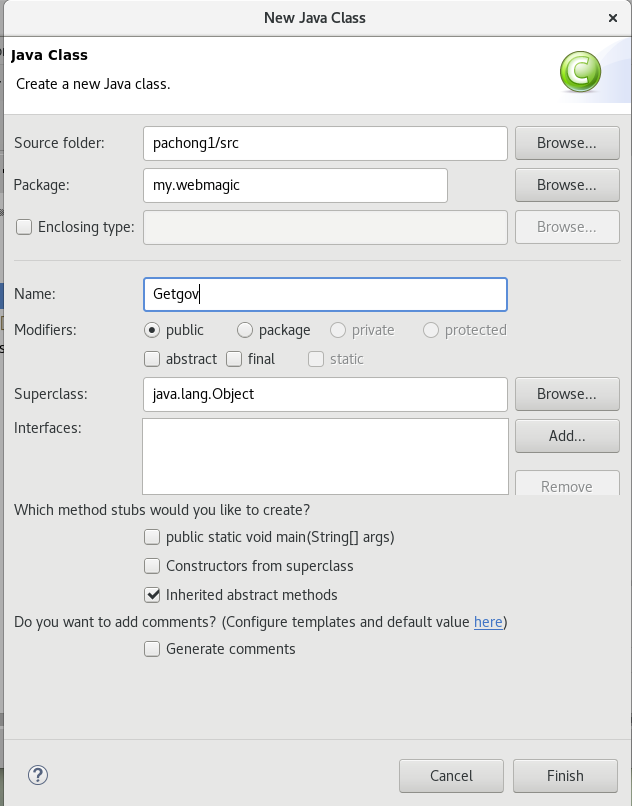
6、在这个新建的包下面,新建一个名为Getgov的class的类
7、代码的编写
package my.webmagic;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.FilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.scheduler.FileCacheQueueScheduler;
public class Getgov implements PageProcessor{
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
@Override
public Site getSite() {
// TODO Auto-generated method stub
return site;
}
@Override
public void process(Page page) {
// TODO Auto-generated method stub
page.putField("allhtml", page.getHtml().toString());
String urlstr = null;
for (int i = 1; i < 2702; i++) {
urlstr = "http://rexian.beijing.gov.cn/default/com.web.index.moreNewLetterQuery.flow?PageCond/currentPage="
+ i + "&type=nextPage";
page.addTargetRequest(urlstr);
page.addTargetRequests(page.getHtml().links()
.regex("(com.web.\\w+.\\w+.flow\\?originalId=\\w+)").all());}
}
public static void main(String[] args) {
Spider.create(new Getgov())
.addUrl("http://rexian.beijing.gov.cn/default/com.web.index.moreNewLetterQuery.flow?type=firstPage")
.addPipeline(new FilePipeline("/root/data/edu1"))
.setScheduler(new FileCacheQueueScheduler("/root/data/edu1"))
.thread(5)
.run();}
}
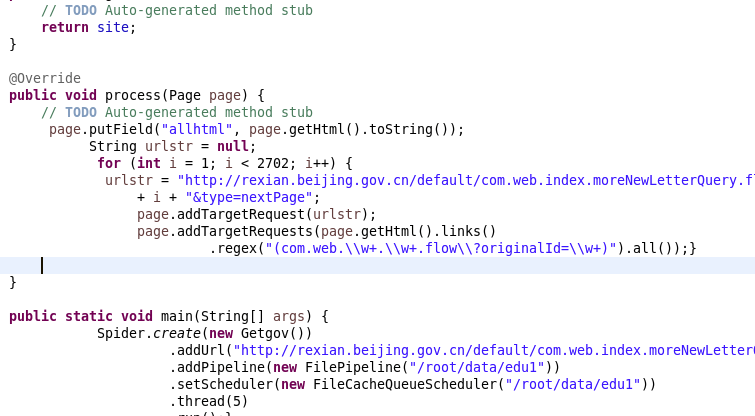
将上面这段代码放入到新建的Getgov的类文件中:
然后运行这个文件:
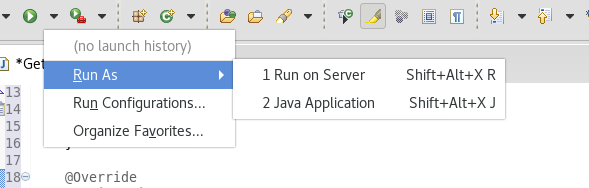
Run As--->Java Application即启动;
