
使用hadoop进行单词统计
1、启动hadoop
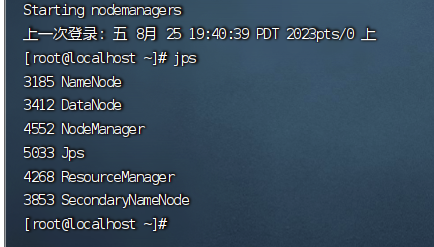
启动成功!
2、将result.txt文件放到/root/software/hadoop-3.0.0下面(txt文件为已经分好词的文件)
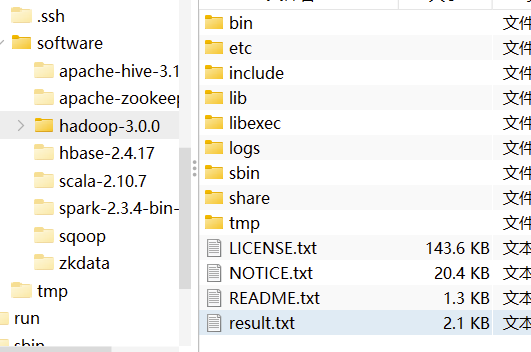
3、利用hadoop自带的jar包wordcount计算词频
1、创建一个文件夹存放需要计算词频的文件
bin/hdfs dfs -mkdir -p /input

2、把需要计算词频的文件放到刚刚创建的文件夹下面
bin/hdfs dfs -put result.txt /input

3、查看txt文件是否存放进去
bin/hdfs dfs -ls /input

已经放进去啦!
4、使用jar包中的wordcount计算词频
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /input/result.txt /out/hlmcount
需要注意的是,jar包的版本可能会有所不同,根据自身实际更改即可
等待计算完成:
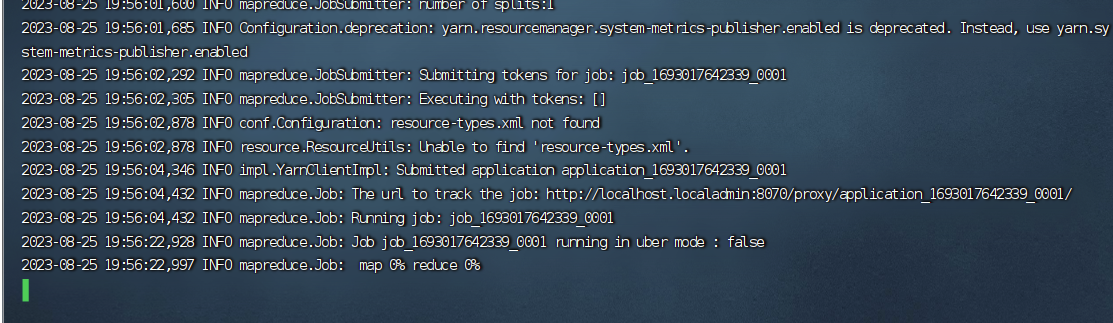
计算完成:
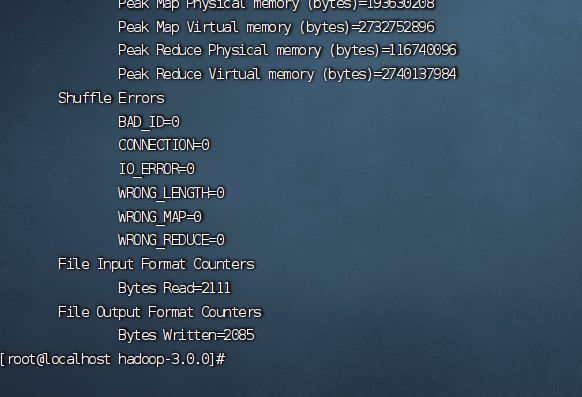
5、查看输出结果
bin/hdfs dfs -cat /out/hlmcount/part-r-00000
计算结果如下:
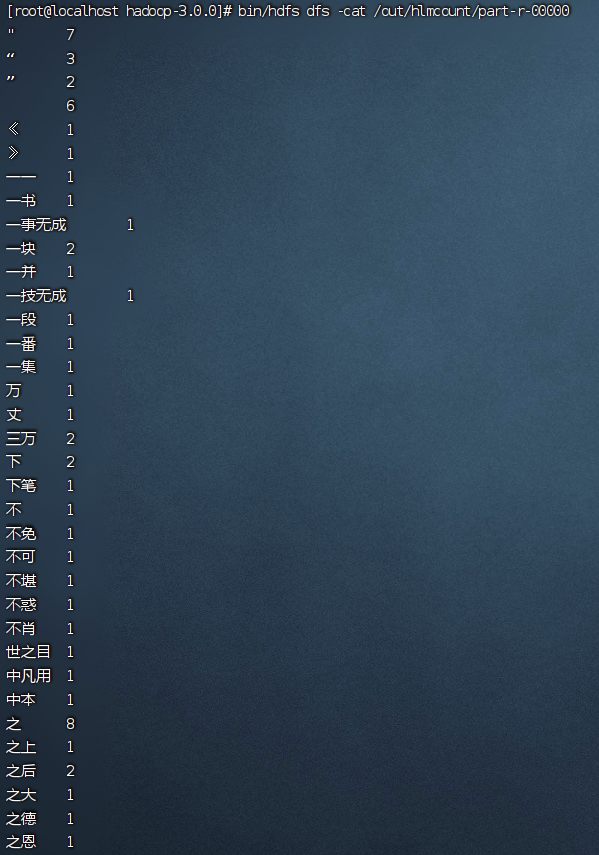
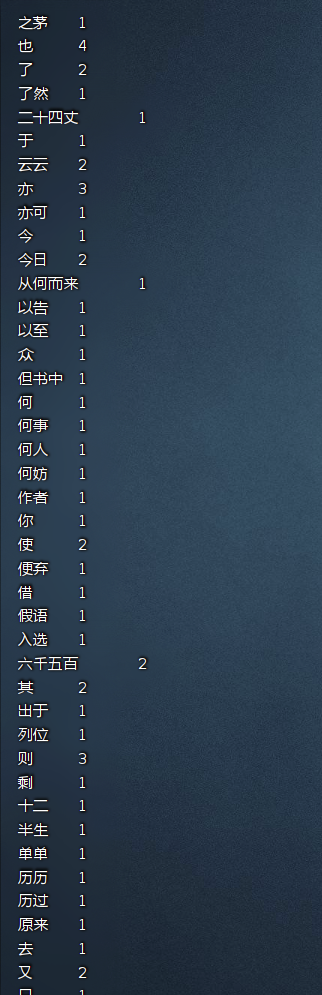
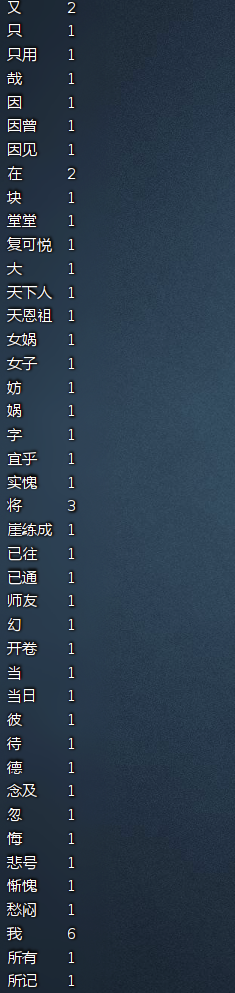

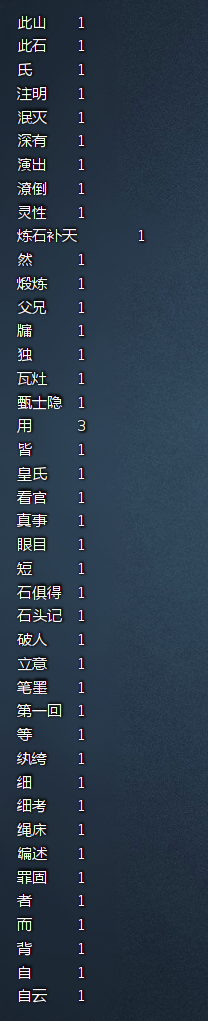
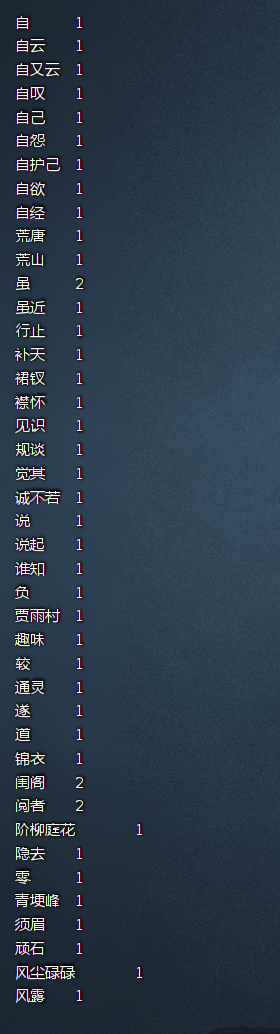
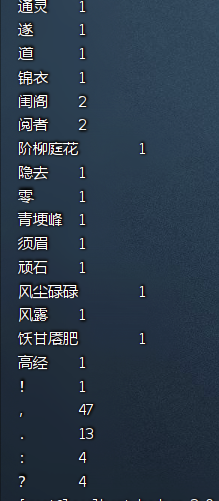
完成!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号