如何使用Python爬取数据
步骤
1、安装相关库
requests和bs4这两个包需要我们去把他们下载下来:


2、获取爬虫所需的header和cookie
可以随便打开一个网页,然后按下F12,进入js的语言设计部分,然后点击里面的网络(也就是NetWork部分),之后按下Ctrl+C,进行刷新;
若是刷新之后,出现文件信息,就停止刷新,否则就继续刷新吧!
然后右键出现的文件的名称(也就是name部分),选中复制(Copy),然后选择其中的复制为cURL(Bash)(不是all所有);
之后,带着我们复制的东西前往这个网站:https://curlconverter.com/
将东西复制到第一个文本框里面,第二个文本框里面会自动显示出相对应的Cookie和Header内容,将其复制就行。
(被称作--请求头)
3、获取网页
将我们获取到的请求头复制到我们的程序中
获取网页:

4、解析网页
回到我们像要爬取的网页界面,同样按下F12,选中其中的元素部分(也就是Elements部分),会出现当前页面的相应代码;
之后,选中这个图标: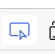
这个图标可以使得我们在原网页上点击某一部分,就会获取到该部分对应的代码;
我们用鼠标点击我们想要获取的改网页的相关内容后,然后,鼠标放在框框的代码上,右键,复制,到selector里面;
5、分析信息,简化地址
如下所示,这是我获取到的三条数据:
scroller > div.vue-recycle-scroller__item-wrapper > div:nth-child(1) > div > div > div > div > div > div.woo-box-flex.woo-box-alignCenter.HotTopic_titout_1CFlj > a
scroller > div.vue-recycle-scroller__item-wrapper > div:nth-child(2) > div > div > div > div > div > div.woo-box-flex.woo-box-alignCenter.HotTopic_titout_1CFlj > a
scroller > div.vue-recycle-scroller__item-wrapper > div:nth-child(3) > div > div > div > div > div > div.woo-box-flex.woo-box-alignCenter.HotTopic_titout_1CFlj > a
取其相同的部分后,就可以另外得到这样一条数据(也就相当于提炼地址吧):
scroller > div.vue-recycle-scroller__item-wrapper > div > div > div > div > div > div > div.woo-box-flex.woo-box-alignCenter.HotTopic_titout_1CFlj > a
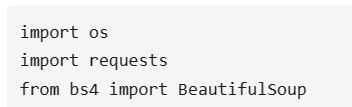
6、爬取内容,清洗数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号