Python学习笔记--PySpark的相关基础学习(一)
PySpark包的下载

下载PySpark第三方包:

构建PySpark的执行环境入口对象

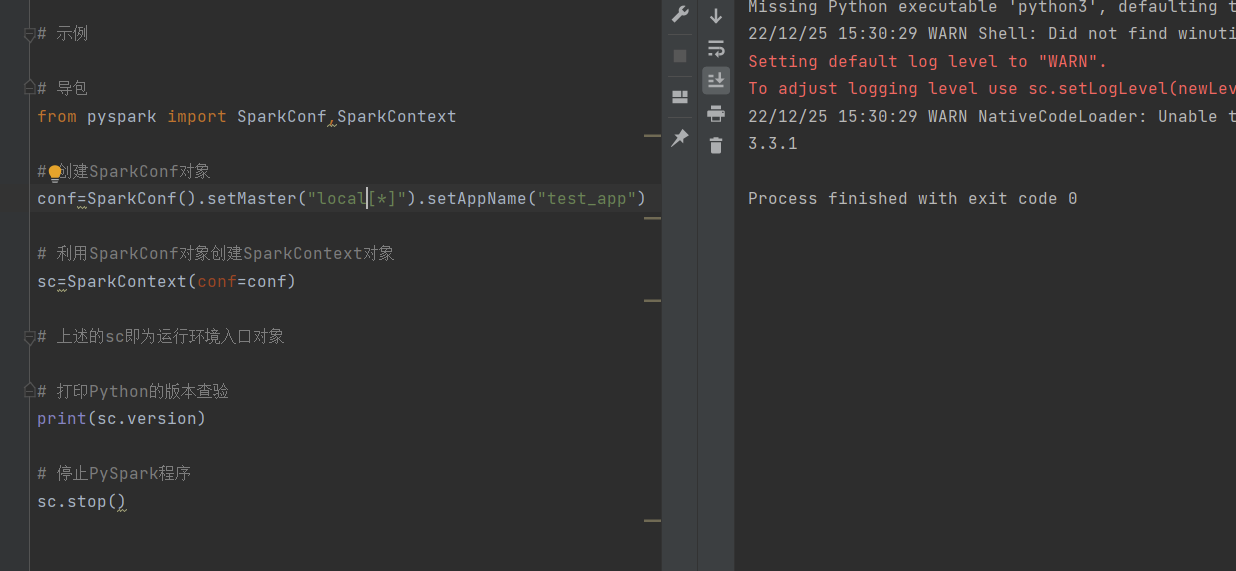
PySpark的编程模型

数据输入

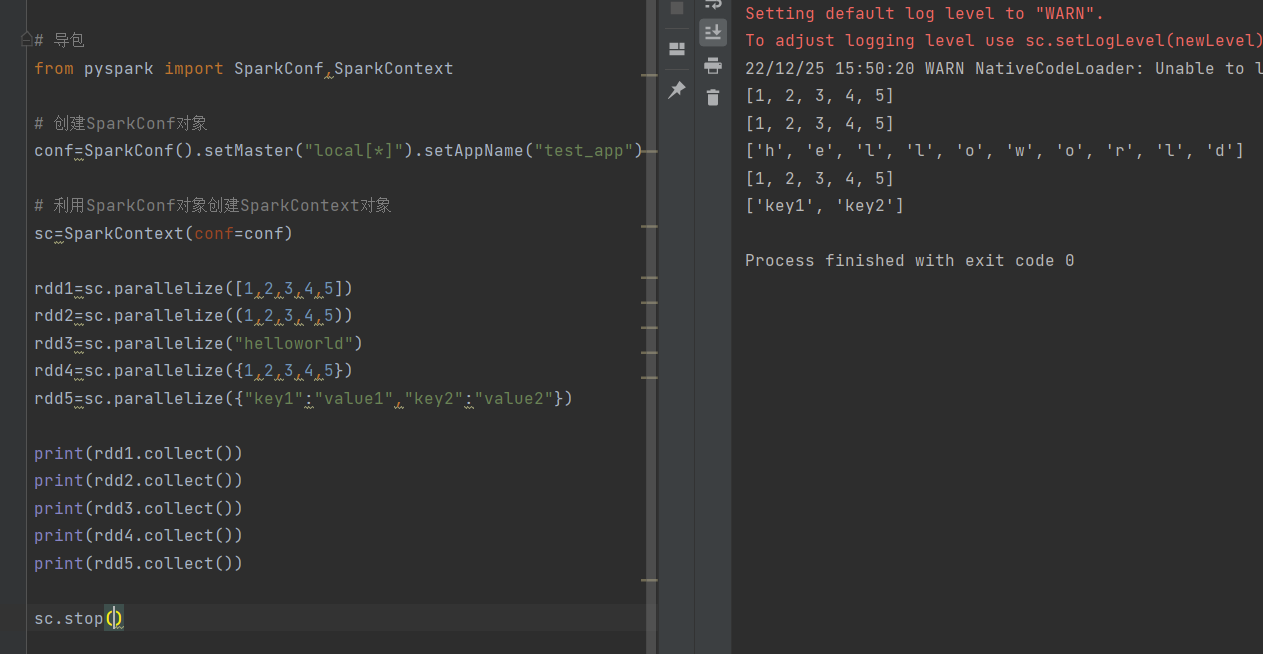
对于SparkContext对象里面的成员方法parallelize,支持:


示例:
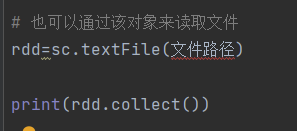
读取文件内容
数据计算
map方法(要求将每个元素都能够传递给map方法调用的方法里面,方法要求有参数,且有返回值)
起初会报错:
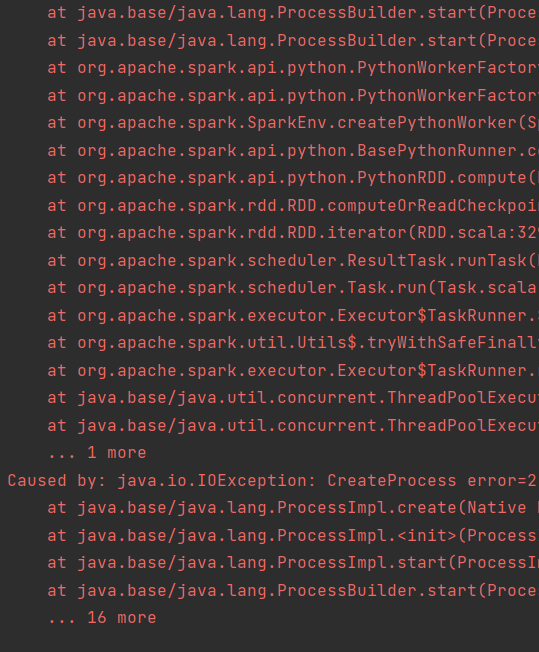
是因为缺少了这样一个import:

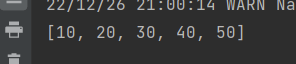
结果出来是这样的:
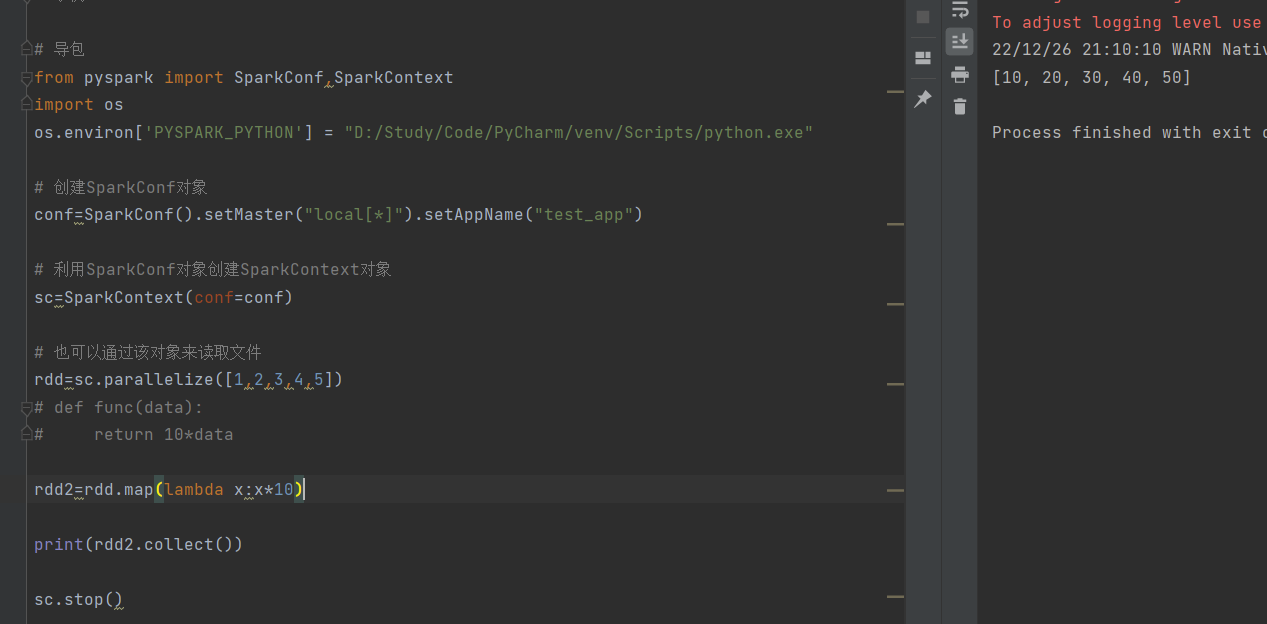
简化后的代码如下:
使用的是Lambda表达式:
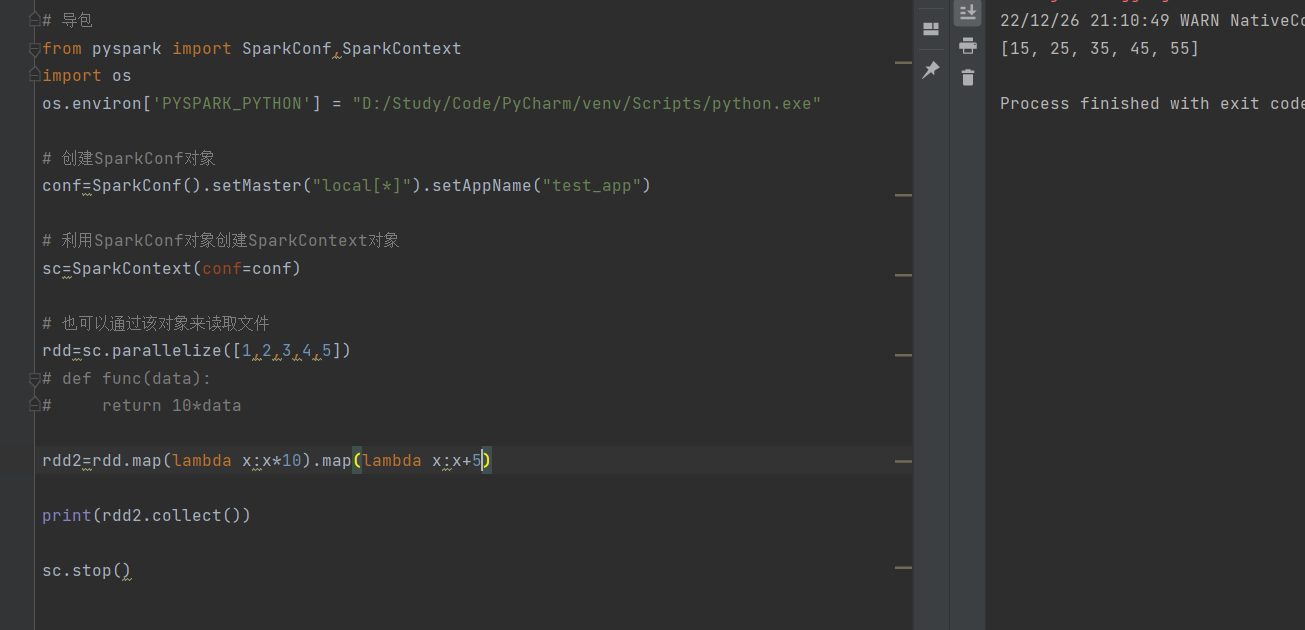
要求,在*10之后,又+5:(链式调用的实现)

flatMap方法(对rdd执行map操作,并进行解除嵌套的操作)
所谓“解除嵌套”:

具体实现:
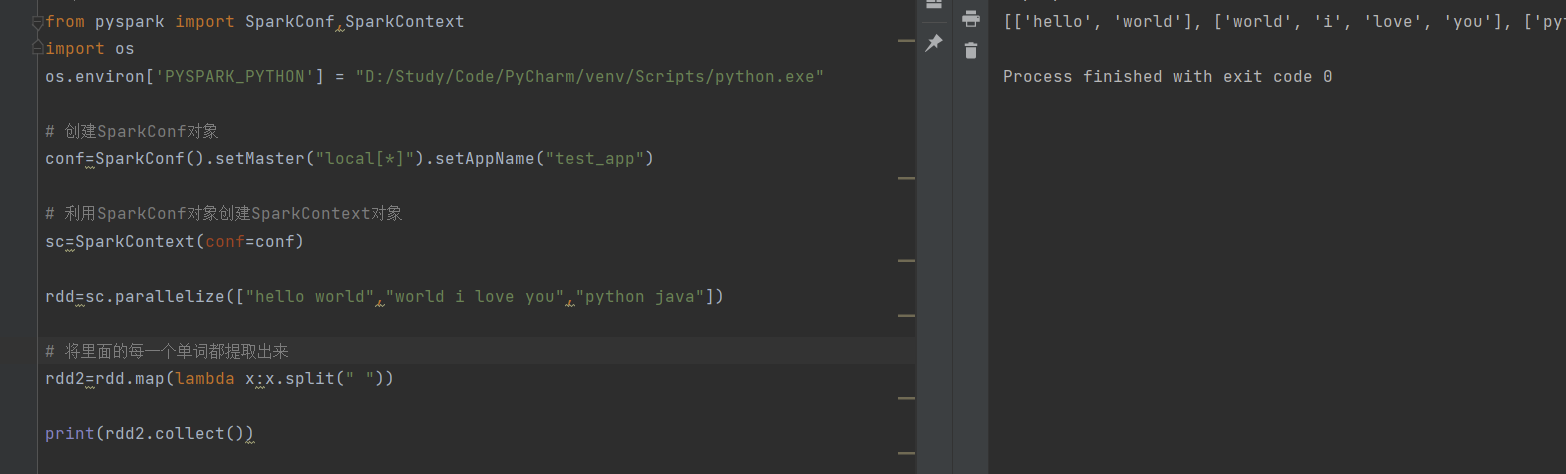
单词分离,但是在list里面嵌套有list,需要利用flatMap解除嵌套:

只需要将map修改成这种形式就可以啦:

reduceByKey方法(针对KV型RDD,自动按照key分组,然后根据提供的聚合逻辑,完成组内数据(value)的聚合操作)
要求有两个传入参数,并且传入参数的类型和返回参数类型是一样的
具体实现:
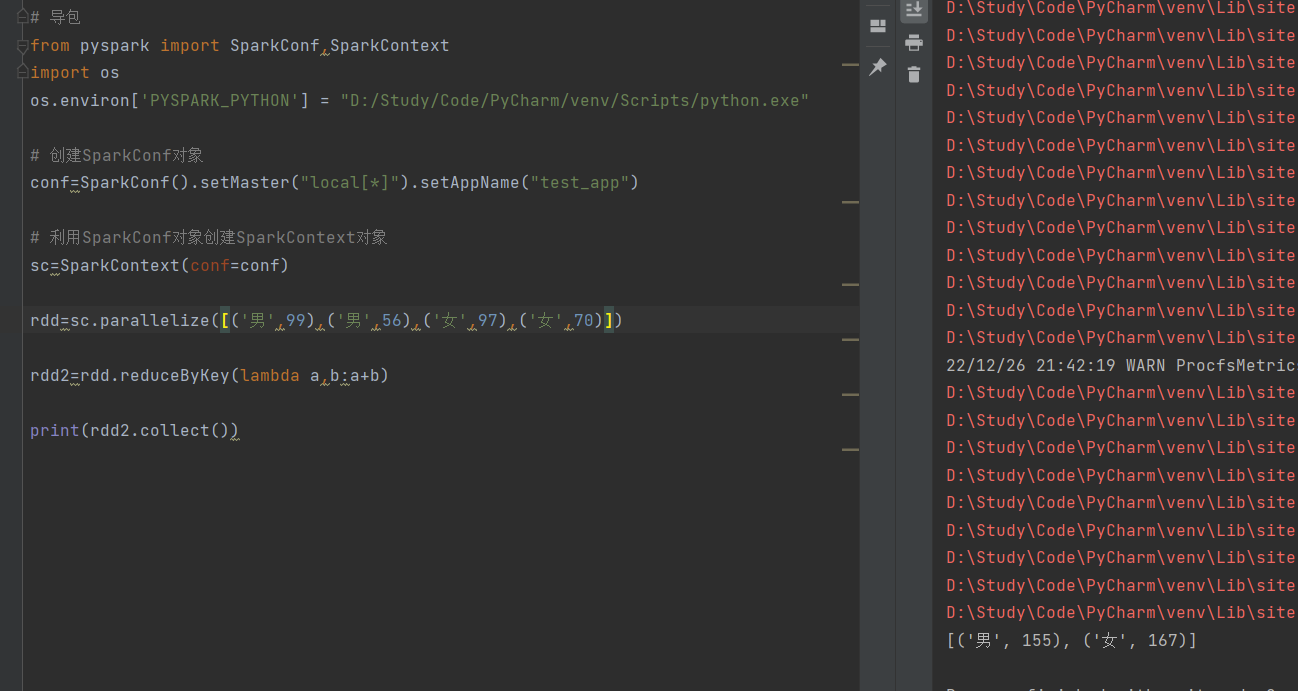
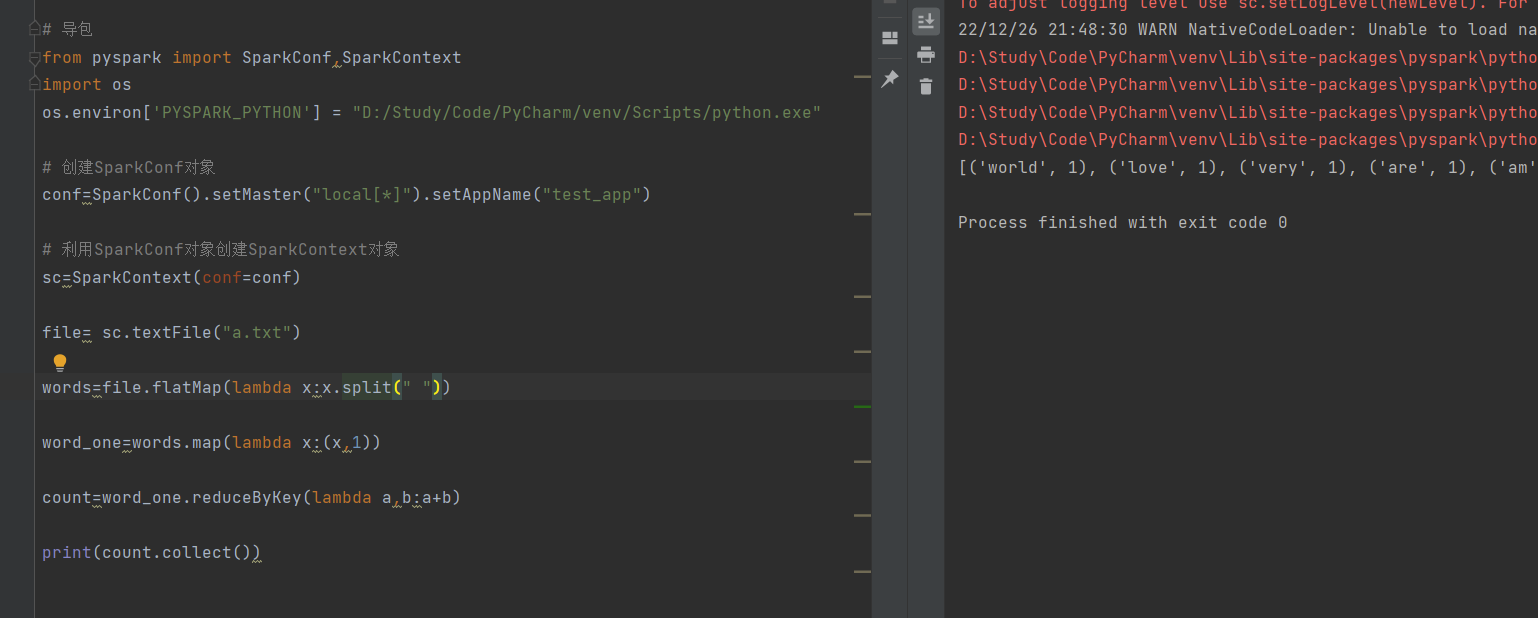
案例:打印某个文件中出现的每个单词各自的数量