Python中OpenCV库(一)
OpenCV库(一)
一、 简介
1、 简介
Opencv(Open Source Computer Vision Library)是一个基于开源发行的跨平台计算机视觉库,它实现了图像处理和计算机视觉方面的很多通用算法,已成为计算机视觉领域最有力的研究工具。在这里我们要区分两个概念:图像处理和计算机视觉的区别:图像处理侧重于“处理”图像–如增强,还原,去噪,分割等等;而计算机视觉重点在于使用计算机来模拟人的视觉,因此模拟才是计算机视觉领域的最终目标
图是物体反射或透射光的分布,像是人的视觉系统所接受的图在人脑中所形成的印象或认识
OpenCV用C++语言编写,它具有C ++,Python,Java和MATLAB接口,并支持Windows,Linux,Android和Mac OS, 如今也提供对于C#、Ch、Ruby,GO的支持
2、 环境配置
2.1 第一种
下载OpenCV:【https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv】
找到对应版本的OpenCV,下载下来
复制文件的地址:【"D:\Documents\opencv_python-4.5.5-cp39-cp39-win_amd64.whl"】
然后打开终端输入:【pip install "D:\Documents\opencv_python-4.5.5-cp39-cp39-win_amd64.whl"】
安装完成后
创建一个python文件,在文件中输入
import cv2 print(cv2.__version__)
成功运行代表安装成功
2.2 第二种
直接在终端输入:pip install opencv-python
这种方式安装较慢哦!
注意:运行OpenCV还要有依赖库 numpy
安装 numpy
pip install numpy
3、 运行原理
一般的图像(模拟图像)不能直接用计算机来处理,必须先将图像转化为数字图像。把模拟图像分割成一个个像素,每个像素的亮度或灰度值用一个整数表示——图像的数字化

3.1 灰度图像数字化
所谓的数字化,其实就是化成同行同列的二维数组,而每个坐标存的就是相关的灰度值(0-255)(为什么是0-255?一个字节存放8bit,而图的储存一般都是以uint8类型存放,同时计算机时按照二进制存放数值,也就是2的8次方,也就是256)

3.2 色彩深度和色阶
| 色彩深度 | 灰阶 |
|---|---|
| 色彩深度(Depth of Color),色彩深度又叫色彩位数。视频画面中红、绿、蓝三个颜色通道中每种颜色为N位,总的色彩位数则为3N,色彩深度也就是视频设备所能辨析的色彩范围。目前有18bit、24bit、30bit、36bit、42bit和48bit位等多种。24位色被称为真彩色,R、G、B各8bit,常说的8bit,色彩总数为1670万,如手机参数,多少万色素就这个概念 | 通常来说,液晶屏幕上人们肉眼所见的一个点,即一个像素,它是由红、绿、蓝(RGB)三原色组成的。每一个基色,其背后的光源都可以显现出不同的亮度级别。而灰阶代表了由最暗到最亮之间不同亮度的层次级别。把三基色每一个颜色从纯色(如纯红)不断变暗到黑的过程中的变化级别划分成为色彩的灰阶,并用数字表示,就是最常见的色彩存储原理。这中间层级越多,所能够呈现的画面效果也就越细腻。以8bit 为例,我们就称之为256灰阶 |
3.3 彩色图像数字化
彩色像数字化原理同灰度图像数字化,只不过彩色图像为三通道图像且可以拆分成三张同等像素的灰度图,由下图可知,每三个BGR就组成了一张图片的一列

数字图像处理的实质就是通过对数字图像中像素数据的判断,依据处理或识别要求,最后逐个像素修改像素的灰度值
二、 基本操作
学习目标:
- 掌握图像的读取和保存方法
- 能够使用OpenCV在图像上绘制几何图像
- 能够访问图像的像素
- 能够获取图像的属性,并进行通道的分离和合并
- 能够实现颜色空间的变换
1、 图像IO操作
1.1 读取图像
语法:cv2.imread(path, mode)
参数:
path:要读取的图像mode:读取方式的标志-
cv2.IMREAD_COLOR\1:以彩色模式加载图像,任何图像的透明度都将忽略,这个默认参数 -
cv2.IMREAD_GRAYSCALE\0:以灰度模式加载图像 -
cv2.IMREAD_UNCHANGED\-1:包括alpha通道的加载图像模式注意:
- 可以使用数字代替这些标志,数字在源码中可以查看
-
实例:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo01.py" __time__ = "2022/7/15 19:30" import cv2.cv2 as cv2 img = cv2.imread("./img/1.jpg", 0) # 以灰度模式读取图像 cv2.imshow("image", img) cv2.waitKey(0)
如果图像读取错误,其不会报错,而是会使图像为空值
1.2 显示图像
语法:cv2.imshow(winname, mat)
参数:
winname:显示图像窗口名称,以字符串类型显示mat:要加载的图像
要注意:在调用显示图像API后,要调用
cv2.waitKey()给绘制图像留下时间,否则窗口会出现无响应的情况,并且图像无法显示出来
另外,我们也可以使用matplotlib对图像进行展示
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo01.py" __time__ = "2022/7/15 19:30" import cv2.cv2 as cv2 from matplotlib import pyplot as plt img = cv2.imread("./img/1.jpg") cv2.imshow("image", img) cv2.waitKey(0) # 0代表等待足够的时间 cv2.destroyAllWindows() # 摧毁窗口 # 使用matplotlib显示图片 plt.imshow(img[:, :, ::-1]) # 将rgb转换为bgr,数组逆置 # 灰度图的读取模式:plt.imshow(img, cmap=plt.cm.gray) plt.show()
1.3 保存图像
语法:cv2.imwrite(fielname, img)
参数:
filename:文件名,路径img:要保存的图像
代码:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo01.py" __time__ = "2022/7/15 19:30" import cv2.cv2 as cv2 import numpy as np img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 声明图像数据为numpy的数组 cv2.imwrite("test.jpg", img)
2、 绘制几何图形
2.1 绘制直线
语法:cv2.line(img, start, end, color, thickness)
参数:
img:要绘制直线的图像Start, End:起始点、终点color:直线的颜色thickness:线条的宽度,为-1时生成闭合图案,并填充颜色
2.2 绘制圆形
语法:cv2.circle(img, centerpoint, r, color, thickness)
参数:
centerpiont:圆形的坐标r:圆的半径- 其它参数和绘制直线的参数意义相同
2.3 绘制矩形
语法:cv2.rectangle(img, leftupper, rightdown, color, thickness)
参数:
leftupper:矩形左上角坐标rightdown:矩形右下角坐标
2.4 添加文字
语法:cv2.putText(img, text, station, font, fontsize, color, thickness, cv.Line_AA)
参数:
station:文本放置位置text:要写入的文本数据font:字体fontsize:字体大小
2.5 效果展示
我们生成一个全黑的图像,然后再里面绘制图像并添加文字
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo02.py" __time__ = "2022/7/15 21:36" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt # 创建一个空白的图像 1920x1080 img = np.zeros([1080, 1920, 3], np.uint8) # 并且设置数据类型为uint8 # 绘制图形 cv2.line(img, (0, 0), (502, 502), (255, 255, 255), 4) cv2.rectangle(img, (502, 502), (900, 900), (255, 0, 0), 4) cv2.circle(img, (800, 700), 100, (0, 255, 0), 4) # 写入文字 cv2.putText(img, "hello world", (10, 500), cv2.FONT_HERSHEY_COMPLEX_SMALL, 4, (255, 255, 0), 4) # 使用cv2内置的字体 plt.imshow(img[:, :, ::-1]) # 逆置图像 plt.title("test") plt.show()
3、 操作图片
3.1 修改像素点
我们可以通过行和列的坐标值获取像素值,对于RGB图像,它返回一个rgb的数组,对于灰度图像,仅返回相应的强度值,使用相同的方法对像素值进行修改
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo02.py" __time__ = "2022/7/15 21:36" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt img = cv2.imread("./img/1.jpg") # 声明img的类型 assert isinstance(img, np.ndarray) # 获取对应点的像素强度值 print(img[100, 200]) # 修改某个点的像素值 img[100, 100] = [255, 255, 255] plt.imshow(img[:, :, ::-1]) plt.show()
3.2 获取图像属性
图像属性包括行数、列数和通道,图像数据类型,像素值等
| 属性 | API |
|---|---|
| 形状 | img.shape |
| 图像大小 | img.size |
| 数据类型 | img.dtype |
3.3 拆分合并
有时需要在B、G、R通道图像上单独工作。在这种情况下,需要将BGR图像分割为单个通道,或者在其他情况下,可能需要将这些单独的通道合并到BGR图像,你可以通过以下方式完成:
# 通道分离 b, g, r = cv2.split(img) # 通道合并 img = cv2.merge(b, g, r)
实例:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo02.py" __time__ = "2022/7/15 21:36" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) plt.imshow(img[:, :, ::-1]) # 进行色道的逆置,转换为bgr b, g, r = cv2.split(img) # 分离 plt.imshow(b, cmap=plt.cm.gray) plt.show() img2 = cv2.merge((b, g, r)) # 返回rgb图像 plt.imshow(img2[:, :, ::-1]) plt.show()
3.4 色道改变
OpenCV中有150多种颜色空间转换方法,最广泛的转换方法有两种,BGR->Gray和BGR->HSV
语法:cv2.cvtColor(input_image, flag)
参数:
input_image:进行颜色空间转换的图像flag:转换类型cv2.COLOR_BGR2GRAY:BGR->GRAYcv2.COLOR_BGR2HSV:BGR->HSV
4、 算术操作
学习目标:
- 了解图像的加法,混合操作
4.1 图像加法
你可以使用OpenCV的cv2.add()函数把两幅图像相加,或者可以简单通过numpy操作添加两个图像,如:res = img1 + img2,两个图像应该具有相同大小和类型,或者第二个图像可以是标量值
注意:OpenCV加法和Numpy加法之间存在差异,OpenCV的加法的饱和操作,而Numpy添加时模运算操作
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "logic.py" __time__ = "2022/7/16 10:52" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt x = np.uint8([250]) y = np.uint8([10]) # unsigned int-8 print(cv2.add(x, y)) # 250 + 10 = 260 -> 255 print(x + y) # 250 + 10 = 260 % 256 = 4 # 实例 # 导入图像 img1 = cv2.imread("./img/1.jpg") assert isinstance(img1, np.ndarray) img2 = cv2.imread("./img/2.jpg") assert isinstance(img2, np.ndarray) # 对图像进行相加 img3 = cv2.add(img1, img2) plt.imshow(img3[:, :, ::-1]) plt.show() img4 = img1 + img2 plt.imshow(img4[:, :, ::-1]) plt.show()
推荐使用OpenCV里面的加法
cv2.add()和减法cv2.subtract()
4.2 图像混合
图像混合其实也是加法,但是不同的是两幅图像的权重不同,这就会给人一种混合或者透明的感觉,图像混合的计算公式如下:
通过修改阿尔法的值,可以实现非常酷的操作
现在我们把两幅图混合在一起,第一幅图的权重是0.7,第二幅图的权重是0.3,函数cv2.addWeight(img1, alpha, img2, beta, gamma)可以按下面公式对图片进行混合操作
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "logic.py" __time__ = "2022/7/16 10:52" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt img1 = cv2.imread("./img/1.jpg") assert isinstance(img1, np.ndarray) img2 = cv2.imread("./img/2.jpg") assert isinstance(img2, np.ndarray) img3 = cv2.addWeighted(img1, 0.7, img2, 0.3, 0) # 根据权重混合 plt.imshow(img3[:, :, ::-1]) plt.show()
4.3 图像位运算
OpenCV的逻辑运算——与、或、非、异或
OpenCV中的非:0 反过来是 255
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo9.py" __time__ = "2022/7/18 18:09" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg") # 读取黑白效果 assert isinstance(img, np.ndarray) img_ = np.zeros(img.shape, np.uint8) # 非操作 img_not = cv2.bitwise_not(img) # 或操作 img_or = cv2.bitwise_or(img, img_) # 与操作 img_and = cv2.bitwise_and(img, img_) # 展示图片 cv2.namedWindow("not", cv2.WINDOW_NORMAL) cv2.resizeWindow("not", 640, 480) cv2.imshow("not", np.hstack((img[:640, :480], img_not[:640, :480]))) cv2.namedWindow("and", cv2.WINDOW_NORMAL) cv2.resizeWindow("and", 640, 480) cv2.imshow("and", np.hstack((img[:640, :480], img_and[:640, :480]))) cv2.namedWindow("or", cv2.WINDOW_NORMAL) cv2.resizeWindow("or", 640, 480) cv2.imshow("or", np.hstack((img[:640, :480], img_or[:640, :480]))) cv2.waitKey(0) cv2.destroyAllWindows()
三、 滤波器
1、 卷积
1.1 什么是图片卷积
图像卷积就是卷积核在图像上按行滑动遍历像素时不断在相乘求和的过程
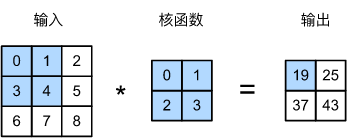
基本概念
-
步长
步长就是卷积核在图像上移动的步幅,卷积核可以每次移动一个像素步长或者两个像素步长等
步长一般为1
-
padding
从上面图片中,我们可以看出,卷积之后图片的长宽会变小,如果要保持图片大小不变。我们需要在原始图片周围填充0。padding指的就是填充0的圈数。
1.2 padding
我们如何判断需要补0的圈数呢?
我们可以通过公式计算出需要填充的0的圈数:
-
输入体积大小:
-
四个超参数:
- Filter数量K
- Filter大小F
- 步长S
- 零填充大小P
-
输出体积大小:
3 x 3 的卷积核 结果 -2 5 x 5 的卷积核 结果 -4 7 x 7 的卷积核 结果 -6 -
求圈数:
通过这个式子可以求出补0的圈数
如果步长为1,则可以推导出
1.3 卷积核大小
图片卷积中,卷积核一般为奇数,比如 3 x 3,5 x 5,7 x 7。为什么一般是奇数呢?
- 根据上面padding的计算 公式,如果要保持图片大小不变,采用偶数卷积核的话,将会出现奇数圈0的情况
- 奇数维度的过滤有中心,便于指出过滤器的位置,即OpenCV卷积中的锚点
1.4 卷积语法
语法:cv2.filter2D(src, ddepth, kernel, [, dest[, anchor[, delta[, borderType]]]])
参数:
ddpeth:其为卷积之后图像的位深,即卷积之后图片的数据类型,一般为-1,表示和原图类型一致kernel:卷积和大小,用元组或者ndarray表示,要求数据类型必须是float32类型anchor:锚点,即卷积核的中心点,是可选参数,默认是(-1, -1)delta:可选参数,表示卷积之后额外加一个值,相当于线性方程中的偏差,默认是0borderType:边界类型,一般不设
案例:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo04.py" __time__ = "2022/7/17 9:52" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt # 读取图像 img = cv2.imread("./img/1.jpg", cv2.IMREAD_GRAYSCALE) # 读取灰度图 assert isinstance(img, np.ndarray) # 创建核结构,kernel必须是float32类型 kernel = np.array([ [-1, -1, -1], [-1, 8, -1], [-1, -1, -1] ], np.float32) # 轮廓效果 # 进行卷积 img_ = cv2.filter2D(img, -1, kernel) # 图片展示 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 1920, 1080) cv2.imshow("img", img_) cv2.waitKey(0) cv2.destroyAllWindows()
卷积核可以在网上查找
2、 滤波器
2.1 方盒滤波和均值滤波
方盒滤波
语法:cv2.boxFilter(src, ddepth, ksize[, dist[, anchor[, normalize[, borderType]]]])
方盒滤波的卷积核形式如下:
参数:
nomalize:- 其为True时,
- 其为False时,a = 1
- 一般情况下,我们都使用
nomalize=True的情况,这时,方盒滤波等价于均值滤波 ksize:卷积核大小
均值滤波
语法:cv2.blur(src, ksize[, dest[, anchor[, borderType]]])
代码演示:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo04.py" __time__ = "2022/7/17 9:52" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 使用滤波器 img_ = cv2.boxFilter(img, -1, (5, 5), normalize=True) # 模糊处理 img_1 = cv2.blur(img, (5, 5)) # 模糊处理 # 图片展示 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 1920, 1080) cv2.imshow("img", img_) cv2.waitKey(0) cv2.destroyAllWindows()
2.2 高斯滤波
要理解高斯滤波,首先要知道什么是高斯函数,高斯函数是在符合高斯分布(也叫正态分布)的数据的概率密度函数
高斯函数的特点:以x轴某一点(这一点称为均值)为对称轴,越靠近中心数据发生的概率越高,最终形成一个两边平缓,中间陡峭的钟型图形
高斯函数的一般形式为:
一维高斯分布:
二维高斯分布:
高斯滤波就是使用符合高斯分布的卷积核对图片进行卷积操作,所以高斯滤波的重点就是如何计算符合高斯分布的卷积核,即高斯模板
通过高斯函数计算出来的是概率密度函数,所以我们还要确保这九个点加起来为1,我们需要将这九个点求和,再分别求权重,得到最终的高斯模板
语法:cv2.GaussianBlur(src, ksize, sigmaX[, dist[, sigmaY[, borderType]]])
参数:
ksize:高斯核的大小sigmaX:X轴的标准差sigmaY:Y轴的标准差,默认为0,这时:sigmaX = sigmaY- 如果指定sigma值为0,会分别从ksize的宽度和高度中计算sigma
选择不同的sigma值会得到不同的平滑效果,sigma越大,平滑效果越明显
高斯滤波可以去除噪点
2.3 中值滤波
中值滤波原理非常简单,假设有一个数组,取其中的中间值(即中位数)作为卷积后的结果值即可,中值滤波对胡椒噪点效果明显
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo04.py" __time__ = "2022/7/17 9:52" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 使用滤波器 img_ = cv2.medianBlur(img, 5) #注意,中值滤波这里的ksize就是一个数字 # 图片展示 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 1920, 1080) cv2.imshow("img", img_) cv2.waitKey(0) cv2.destroyAllWindows()
2.4 双边滤波
双边滤波对于图像的边缘信息能够更好的保存,其原理为一个与空间距离相关的高斯函数与一个灰度距离相关的高斯函数相乘
-
空间距离:指的是当前点与中心点的欧式距离。空间域高斯函数其数学形式为:
其中,(, )为当前位置,(, )为中心点的位置,sigma为空间域标准差
-
灰度距离:指的是当前点灰度与中心点灰度的差的绝对值,值域高斯函数其数学形式为:
双边滤波本质上是高斯滤波,双边滤波和高斯滤波不同的是:双边滤波既利用了位置信息,又利用了像素信息来定义滤波窗口的权重,而高斯滤波只利用了位置信息
双边滤波中加入了对灰度信息的权重,即在邻域内,灰度值越接近中心点灰度值权重更大,灰度值相差大的权重点权重越小,此权重大小,则有高斯函数确定
两者权重系数相乘,得到最终的卷积模板,由于双边滤波需要每个中心点邻域的灰度信息来确定其系数,所以其速度比一般滤波慢得多,而且计算量增长速度为核大小的平方
双边滤波可以保留边缘,同时可以对边缘内的区域进行平滑处理,相当于做了美颜
语法:bilateralFilter(src, ksize, sigmaColor, sigmaSpace[, dst[, borderType]])
参数:
ksize:卷积核大小,传入数字sigmaColor:计算像素信息使用的sigmasigmaSpace:计算空间信息使用的sigma
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo04.py" __time__ = "2022/7/17 9:52" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt # 读取图像 img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 使用滤波器 img_ = cv2.bilateralFilter(img, 7, 20, 50) # 图片展示 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", img_) cv2.waitKey(0) cv2.destroyAllWindows()
3、 算子
边缘是像素值发生跃迁的位置,是图像的显著特征之一,在图像特征提取,对象检测,模式识别等方面都有重要作用
人眼如何识别图像边缘?
比如有一副图,图里面有一条线,左边很亮,右边很暗,那人眼就很容易识别这条线作为边缘,也就是像素的灰度值快速变化的地方
3.1 索贝尔算子
索贝尔算子对图像求一阶导数,一阶导数越大,说明像素在该方向作为边缘,也就是像素灰度值快速变换的地方
因为图像的灰度值都是离散的数字,索贝尔算子采用离散差分算子计算图像像素点亮度值的近似梯度
图像是二维的,即沿着宽度/高度这两个方向
我们可以得到两个新的矩阵,分别反映了每一点像素在水平方向上的亮度变化情况和在垂直方向上的亮度变换情况
综合考虑这两个方向的拜年话,我们可以使用平方和相加的方式反映某个像素的梯度变化情况,有时候为了简单起见,也直接使用绝对值相加替代
语法:Sobel(src, ddepth, dx, dy, dst=None, ksize=None, scale=None, delta=None, borderType=None)
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo5.py" __time__ = "2022/7/18 11:20" import cv2.cv2 as cv2 import numpy as np img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 注意sobel算子要分开计算x,y的梯度女 # 计算X轴方向的梯度 dx = cv2.Sobel(img, -1, 1, 0, None, 3) # 计算Y轴方向的梯度 dy = cv2.Sobel(img, -1, 0, 1, None, 3) # 计算和梯度 img_ = cv2.add(dx, dy) cv2.namedWindow("img", cv2.WINDOW_AUTOSIZE) # cv2.imshow("img", dx) # cv2.imshow("img", dy) cv2.imshow("img", np.hstack((img_, dx, dy))) cv2.waitKey(0) cv2.destroyAllWindows()
3.2 沙尔算子
当内核大小为3时,以上的索贝尔内核可能产生比较明显的误差(其值求取了导数的近似值)
为了解决这一问题,OpenCV提供了Scharr函数,但该函数仅作用于大小为三的内核,该函数的运算与索贝尔函数一样快,但是结果更加精确
沙尔算子和索贝尔算子很类似,只不过使用不同的内核值,放大了像素变换的情况
语法:Scharr(src, ddepth, dx, dy, dst=None, scale=None, delta=None, borderType=None)
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo5.py" __time__ = "2022/7/18 11:20" import cv2.cv2 as cv2 import numpy as np img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 注意sobel算子要分开计算x,y的梯度女 # 计算X轴方向的梯度 dx = cv2.Scharr(img, -1, 1, 0) # 计算Y轴方向的梯度 dy = cv2.Scharr(img, -1, 0, 1) # 计算和梯度 img_ = cv2.add(dx, dy) cv2.namedWindow("img", cv2.WINDOW_AUTOSIZE) # cv2.imshow("img", dx) # cv2.imshow("img", dy) cv2.imshow("img", np.hstack((img_, dx, dy))) cv2.waitKey(0) cv2.destroyAllWindows()
3.3 拉普拉斯算子
索贝尔算子是模拟一阶求导,导数越大的地方说明变换越剧烈,越有可能是边缘,那么如果继续对导数求导呢?可以发现边缘处的二阶导数为0,我们可以利用这一特性去寻找图像的边缘(二阶导数为0的位置也可能是无意义的位置)
拉普拉斯算子推导过程:
以x方向求解为例:
语法:cv2.Laplacian(src, ddepth, dst=None, ksize=None, scale=None, delta=None, borderType=None)
可以同时求两个方向的边缘
对噪音敏感,需要先进行去噪,再调用拉普拉斯算子
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo5.py" __time__ = "2022/7/18 11:20" import cv2.cv2 as cv2 import numpy as np img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) img = cv2.medianBlur(img, 7) # 进行去噪 # 计算梯度 img_ = cv2.Laplacian(img, cv2.CV_64F) # 设置位深 cv2.namedWindow("img", cv2.WINDOW_AUTOSIZE) # cv2.imshow("img", dx) # cv2.imshow("img", dy) cv2.imshow("img", np.hstack((img_, dx, dy))) cv2.waitKey(0) cv2.destroyAllWindows()
3.4 Canny 边缘检测
Canny 边缘检测算法是用来进行多级边缘检测算法,也被很多人认为是边缘检测的最优算法,最优边缘检测的三个主要评价标准是:
- 低错误率:标识出尽可能多的实际边缘,同时尽可能的减少噪声产生的误报
- 高定位性:标识出的边缘要与图像中的实际边缘尽可能接近
- 最小响应:图像中的边缘只能标识一次
Canny边缘检测的一般步骤:
- 去噪,边缘检测容易受到噪声影响,在进行边缘检测前通常需要先进行去噪,一般用高斯滤波去除噪声
- 计算梯度:对平滑后的图像采用sobel算子计算梯度和方向
- ,为了方便一般可以改用绝对值相加
- 梯度的方向被归为四类,垂直、水平和两条对角线
- 非极大值抑制
- 在获取了梯度和方向后,遍历图像,去掉所有不是边界的点
- 实现方法:逐个遍历像素点,判断当前像素点周围像素点中是否具有相同方向梯度的最大值
- 滞后阈值
语法:Canny(img, minVal, maxVal, ...)
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo5.py" __time__ = "2022/7/18 11:20" import cv2.cv2 as cv2 import numpy as np img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 阈值越小,细节越丰富 lena1 = cv2.Canny(img, 100, 200) # 设置阈值范围 lena2 = cv2.Canny(img, 64, 128) cv2.imshow("img", np.hstack((lena1, lena2))) cv2.waitKey(0) cv2.destroyAllWindows()
四、 图像处理
1、 几何变换
学习目标
- 掌握图像的缩放、平移、旋转等
- 了解数字图像的仿射变换和透射变换
1.1 图像缩放
缩放是对图像大小进行调整,即使图像放大或缩小
语法:cv2.resize(src, dsize, fx=0, fy=0, interpolation=cv2.INTER_LINEAR)
参数:
-
src:输入图像 -
dsize:绝对尺寸,直接指定调整后图像的大小 -
fx, fy:相对尺寸,将dsize设置为None,然后将fx和fy设置为比例因子即可 -
interpolation:差值方法差值 含义 cv2.INTER_LINEAR双线性插值法 cv2.INTER_NEAREST最近邻插值 cv2.INTER_AREA像素区域重采样(默认) cv2.INTER_CUBIC双三次插值
1.2 图像平移
图像平移将图像按照指定方向和距离,移动到相应的位置
语法:cv2.warpAffine(img, M, dsize)
参数:
-
img:输入图像 -
M:2*3移动矩阵对于(x, y)处的像素点,要把它移动到(, ),M矩阵应如下设置:

注意:将M设置为np.float32类型的Numpy数组
-
dsize:输出图像的大小注意:输出图像的大小,它应该是(宽度/列,高度/行)的形式
实例:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo3.py" __time__ = "2022/7/16 11:32" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) img = cv2.warpAffine(img, np.float32([ [1, 0, 100], [0, 1, 50] ]), img.shape[1:: -1]) # 根据原图像大小进行平移,不进行缩放,img.shape(row, col, color) plt.imshow(img[:, :, ::-1]) plt.show()
1.3 图像旋转
图像旋转是指图像按照某个位置移动一定角度的过程,旋转中图像仍然保持这原始尺寸。图像旋转后图像的水平对称轴、垂直对称轴及中心坐标原点都可能发生变换,因此需要对图像旋转中的坐标进行相应转换
在OpenCV中,图像旋转首先根据旋转角度和旋转中心获取旋转矩阵,然后根据旋转矩阵进行变换,即可实现任意角度和任意中心的旋转效果
语法:cv2.getRotationMatrix2D(center, angle, scale)
参数:
center:旋转中心angle:旋转角度scale:缩放比例
返回:
-
M:旋转矩阵调用
img = cv2.warpAffine(img, M, img.shape[1:: -1])完成图像的旋转
实例:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo3.py" __time__ = "2022/7/16 11:32" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 规定逆时针旋转 M = cv2.getRotationMatrix2D((0, 0), 30, 1) # 获取旋转矩阵 img = cv2.warpAffine(img, M, img.shape[1:: -1]) # 进行图像旋转 plt.imshow(img[:, :, ::-1]) plt.show()
1.4 仿射变换
图像的仿射变换涉及到图像的形状位置角度的变化,是深度学习预处理中常用到的功能,仿射变换主要是对图像的缩放、旋转,翻转和平移等操作的组合那什么是仿射变换? 仿射变换,是指在几何中,对一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间。
在OpenCV中,仿射变换的矩阵是一个2*3的矩阵:

需要注意的是,对于图像而言,宽度方向是x,高度方向是y,坐标的顺序和图像像素对应下标一致,所以原点的位置不是左下角而是左上角,y的方向也不是向上,而是向下
在仿射变换中,原图中所有的平行线在结果图像中同样平行,为了创建这个矩阵,我们需要从原图像中找到三个点以及他们在输出图像中的位置,然后cv2.getAffineTransform()会创建一个2x3的矩阵,最后这个矩阵会被传给函数cv2.warpAffine(img, M, dsize)
实例:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo3.py" __time__ = "2022/7/16 11:32" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 创建变换矩阵 src = np.float32([ [50, 50], [200, 50], [50, 200] ]) # 原始位置的点 dest = np.float32([ [100, 100], [200, 50], [100, 250] ]) # 变换后的点 M = cv2.getAffineTransform(src, dest) # 完成仿射变换 img = cv2.warpAffine(img, M, img.shape[1:: -1]) # 根据原图像大小进行平移,不进行缩放,img.shape(row, col, color) plt.imshow(img[:, :, ::-1]) plt.show()
1.5 透射变换
透射变换是视角变换的结果,是指利用透视中心、像点、目标点散点共线的条件,按透视旋转定律使承影面(透视面)绕轨迹线(透视轴)旋转某一角度,破坏原有的投影光线束,仍能保持承影面上投影几何图形不变的变换, 透视变换是将图片投影到一个新的视平面,也称作投影映射.它是二维(x,y)到三维(X,Y,Z),再到另一个二维(x’,y’)空间的映射
变换公式:

透射变换矩阵为:

其中,T1代表对图像进行线性变换,T2对图像进行平移,T3表示对图像进行投射变换,a33一般设为1
在OpenCV中,我们要找到四个点,其中任意三个不共线,然后获取变换矩阵T,再进行透射变换,通过函数cv2.getPerspectiveTransform()找到变换矩阵,将cv2.warpPerspective()应用于此3x3变换矩阵
示例:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo3.py" __time__ = "2022/7/16 11:32" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 创建变换矩阵 src = np.float32([ [56, 65], [368, 52], [28, 387], [389, 390], ]) # 原始位置的点 dest = np.float32([ [100, 145], [300, 100], [80, 290], [310, 300] ]) # 变换后的点 M = cv2.getPerspectiveTransform(src, dest) # 进行透射变换 img = cv2.warpPerspective(img, M, img.shape[1:: -1]) # 根据原图像大小进行平移,不进行缩放,img.shape(row, col, color) plt.imshow(img[:, :, ::-1]) plt.show()
1.6 图像金字塔
图像金字塔是图像多尺度表达的一种,最主要用于图像的分割,是一种以多分辨率来解释图像的有效但概念简单的结构
图像金字塔用于及其视觉和图像压缩,一副图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,但来源于同一张原始图的图像集合,其通过梯次向下采样获得,直到达到某个终止条件才停止采样
金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似,层级越高,图像越小,分辨率越低
语法:
cv2.pyrUp(img) # 对图像进行向上采样 cv2.pyrDown(img) # 对图像进行向下采样
2、 形态学操作
形态学的基本思想是利用一种特殊的结构元(本质上就是卷积核)来测量或提取输入图像中相应的形状或特征,以便进一步进行图像分析和目标识别
这些处理方法基本是对二进制图像进行处理,即黑白图像
卷积核决定着图像处理后的效果
学习目标:
- 理解图像的邻域、连通性
- 了解不同的形态学操作:腐蚀、膨胀、开闭运算、礼帽和黑帽等,及其不同操作之间的关系
2.1 图像全局二值化
二值化:将图像的每个像素变成两种值:比如0,255
语法:cv2.threshold(src, thresh, maxval, type[, dest])
参数:
-
thresh:阈值 -
maxval:最大值,最大值不一定是255 -
type:操作类型,常见操作类型如下:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo6.py" __time__ = "2022/7/18 14:31" import cv2.cv2 as cv2 import numpy as np # 导入图片 img = cv2.imread("./img/1.jpg", cv2.IMREAD_GRAYSCALE) # 以灰度图的形式导入 # 二值化操作是对灰度图像操作,注意,这个函数会返回两个值,一个是阈值,一个是原图像 thresh, img_ = cv2.threshold(img, 100, 255, cv2.THRESH_BINARY) print(thresh) cv2.imshow("img", img_) cv2.waitKey(0) cv2.destroyAllWindows()
2.2 自适应阈值
在前面的部分,我们使用是全局阈值,整副图像采用同一个数作为阈值。当时这种方法并不适应与所有情况,尤其是在当同一副图像上的不同部分具有不同亮度时。这种情况下,我们需要采用自适应阈值。此时的阈值是根据图像上每一个小区域计算与其对应的阈值。因此在同一副图像上的不同区域采用不同的阈值,从而使我们能在亮度不同的情况下得到更好的结果
语法:cv2.adaptiveThreshold(src, maxValue, adpativeMethod, type, blockSize, C, dest=None)
参数:
adaptiveThreshold:指定计算阈值的方法cv2.ADAPTIVE_THRESH_MEAN_C:阈值取自相邻区域的平均值cv2.ADAPTIVE_THRESH_GAUSSIAN_C:阈值取值相邻区域的加权和,权重为一个高斯窗口blockSize:邻域大小(用来计算阈值的区域大小)C:这是一个常数,阈值等于的平均值或者加权平均值减去这个常数
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo6.py" __time__ = "2022/7/18 14:31" import cv2.cv2 as cv2 import numpy as np # 导入图片 img = cv2.imread("./img/1.jpg", cv2.IMREAD_GRAYSCALE) # 以灰度图的形式导入 # 自适应阈值二值化只有一个返回值 img_ = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 0) cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack([img[:640, :480], img_[:640, :480]])) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
2.3 连通性
在图像中,最小的单位是像素,每个像素周围有8个邻接像素,常见的邻接关系有3中:4邻接、D邻接和8邻接。
- 4邻接:像素p(x, y)的4邻域是:(x+1, y), (x-1, y), (x, y+1), (x, y-1)
- D邻域:像素p(x,y)的D邻域是:对角上的点,(x+1, y+1), (x+1, y-1), (x-1, y+1), (x-1, y-1)
- 8邻域:像素P(x,y)的8邻域是:4邻域的点 + D邻域的点,用表示像素p的8邻域
连通性是描述区域和边界的重要概念,两个像素连通的两个必要条件是:
-
两个像素的位置是否相邻
-
两个像素的灰度值是否满足特定的相似性准则(或者是否相等)
根据连通性的定义,有4连通、8连通和m连通:
-
4连通:对于具有值V的像素p和q,如果q在集合中,则称这两个像素是4连通
-
8连通:对于具有值V的像素p和q,如果q在集合中,则称这两个像素是8连通
-
m连通:对于具有值V的像素p和q,如果:
- q在集合中,
- 或
- q在集合中,
- 并且和的交集为空(没有值V的像素)
则称这两个像素是m连通的,即4连通和D连通是混合连通
2.4 膨胀和腐蚀
形态学转换是基于图像形状的一些简单操作,它通常在二进制图像上执行。腐蚀和膨胀是两个基本的形态学运算符,然后它的变形形式如运算、闭运算、礼帽黑帽等
腐蚀和膨胀是最基本的形态学操作,腐蚀和膨胀都是针对白色部分(高亮部分)而言的
膨胀就是使图像中高亮部分扩展,效果图拥有比原图更大的高亮区域;腐蚀是原图中高亮区域被蚕食,效果图拥有比原图更小的高亮区域。膨胀是求局部最大值的操作,腐蚀是求局部最小值的操作
-
腐蚀:
具体操作时:用一个结构单元扫描图像中的每一个像素,用结构元素中的每一个像素与其覆盖的像素做“与”操作,如果为1,则该像素为1,否则为0。
作用:腐蚀的作用是消除物体边界点,使目标缩小,可以消除小于结构元素的噪声点
语法:
cv2.erode(img, kernel, iteration)参数:
img:要处理的图像kernel:内核结构iteration:腐蚀次数,默认是1
-
膨胀:
具体操作是:用一个结构元素(卷积核)扫描图像中的每一个像素,用结构单元中的每一个像素与其覆盖的像素做“与”操作,如果都为0,则该像素为0,否则为1,
作用:膨胀的作用是将与接触物体的所有背景点合并到物体中,使目标增大,可添补目标中的孔洞
语法:
cv2.dilate(img, kernel, iterator)
示例:
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo04.py" __time__ = "2022/7/17 9:52" import cv2.cv2 as cv2 import numpy as np import matplotlib.pyplot as plt # 读取图像 img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) # 创建核结构 kernel = np.ones((5, 5), np.uint8) # 图像腐蚀和膨胀 erode_ = cv2.erode(img, kernel) dilate_ = cv2.dilate(img, kernel) # 展示图像 plt.imshow(erode_[:, :, ::-1]) plt.show() plt.imshow(dilate_[:, :, ::-1]) plt.show()
2.5 获取形态学卷积核
OpenCV提供了获取卷积核的接口,不需要我们手动创建卷积核
语法:getStructuringElement(shape, ksize[, anchaor])
参数:
shape:只卷积核的形状,注意不是指长度,是指卷积核中1形成的形状cv2.MORPH_RECT:卷积核中的1是矩形cv2.MORPH_ELLIPSE:椭圆cv2.MORPH_CROSS:十字
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo7.py" __time__ = "2022/7/18 15:17" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg", cv2.IMREAD_GRAYSCALE) assert isinstance(img, np.ndarray) # 获取内核形状 kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)) # 图像腐蚀和膨胀 erode_ = cv2.erode(img, kernel) dilate_ = cv2.dilate(img, kernel) # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack((erode_[:640, :480], dilate_[:640, :480]))) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
2.6 开闭运算
开运算和闭运算是将腐蚀和膨胀按照一定的次序进行处理,但这两者并不是可逆的,即先开后闭并不能得到原来的图像
开运算是先腐蚀后膨胀,其作用是,消除小区域。特点:消除噪点,去除小的干扰块,而不影响原来的图像
- 语法:
cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) - 参数:
MORPH_OPEN:表示进行开运算kernel:如果噪点比较多,会选择大一点的kernel,如果噪点比较小,可以选择小点的kernel
闭运算是先膨胀后腐蚀,其作用是,消除内部的小部分噪点
- 语法:
cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo7.py" __time__ = "2022/7/18 15:17" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg", cv2.IMREAD_GRAYSCALE) assert isinstance(img, np.ndarray) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)) open_ = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) # 开运算 = 腐蚀 + 膨胀 close_ = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) # 闭运算 = 膨胀 + 腐蚀 # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack((open_[:640, :480], close_[:640, :480]))) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
2.7 形态学梯度
梯度 = 原图 - 腐蚀
腐蚀之后原图边缘变小了,原图 - 腐蚀 就可以得到腐蚀的部分,即边缘
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo7.py" __time__ = "2022/7/18 15:17" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg", cv2.IMREAD_GRAYSCALE) assert isinstance(img, np.ndarray) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 9)) # 注意调节kernel大小,以获得更清晰的边缘 img_ = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel) # 得到图像的梯度 # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack((img[:640, :480], img_[:640, :480]))) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
2.8 顶帽运算
顶帽 = 原图 - 开运算
开运算的效果是去除图像外的噪点,原图 - 开运算就得到了去掉的噪点
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo7.py" __time__ = "2022/7/18 15:17" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg", cv2.IMREAD_GRAYSCALE) assert isinstance(img, np.ndarray) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 注意调节kernel大小,以获得更清晰的边缘 img_ = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel) # 顶帽操作,得到去掉的噪点 # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack((img[:640, :480], img_[:640, :480]))) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
2.9 黑帽操作
黑帽 = 原图 - 闭运算
闭运算可以将图形内部的噪点去掉,那么原图 - 闭运算的结果就是图形内部的噪点
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo7.py" __time__ = "2022/7/18 15:17" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg", cv2.IMREAD_GRAYSCALE) assert isinstance(img, np.ndarray) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 9)) # 注意调节kernel大小,以获得更清晰的边缘 img_ = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel) # 顶帽操作,得到去掉的噪点 # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack((img[:640, :480], img_[:640, :480]))) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
3、 图像轮廓
图像轮廓是具有相同颜色或灰度的连续点的曲线,轮廓在形状分析和物体的检测和识别中很有用
轮廓的作用:
- 图形分析
- 物体的识别和检测
注意点:
- 为了检测物体的准确性,需要先对图像进行二值化或Canny操作
- 画轮廓时会修改输入的图像,如果之后想继续使用原始图像,应该先将图像存储到其他变量中
3.1 查找轮廓
语法:findContous(img, mode, method[, contous[, hierachy[, offset]]])
参数:
mode:查找模式cv2.RETR_EXTERNAL=0:表示只检测外围轮廓cv2.RETR_LIST=1:检测的轮廓不建立等级关系,即检测所有轮廓,较为常用cv2.RETR_CCOMP=2:每层最多两级,从小到大,从里到外cv2.RETR_TREE=3:按照树形存储轮廓,从大到小,从右到左
method:轮廓近似方法cv2.CHAIN_APPROX_NONE:保存所有轮廓上的点cv2.CHAIN_APPROX_SIMPLE:只保存角点,比如四边形,只保留四边形的4个角,存储信息较少,比较常用
- 返回
contours和hierachy,即轮廓和层级
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo8.py" __time__ = "2022/7/18 16:04" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg", cv2.IMREAD_GRAYSCALE) # 转换为灰度图 assert isinstance(img, np.ndarray) # 图片二值化处理 img_ = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 0) # 查找轮廓,返回轮廓和层级,注意,要传入二值化后的图像 contr, hiera = cv2.findContours(img_, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) print(contr, hiera) # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack((img[:640, :480], img_[:640, :480]))) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
3.2 绘制轮廓
语法:drawConturs(img, contours, contoursIdx, color[, thick[, lineType[, hierarchy[, maxLeve[, offset]]]]])
参数:
img:要绘制的轮廓图像contours:轮廓点contourIdx:要绘制的轮廓编号,-1表示绘制所有轮廓color:轮廓样式,传入三元组thickness:线框,-1表示全部填充
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo8.py" __time__ = "2022/7/18 16:04" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) img_ = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) # 转化为RGB色道 # 图片二值化处理 img_ = cv2.adaptiveThreshold(img_, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 0) # 查找轮廓 contr, hiera = cv2.findContours(img_, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) # 绘制轮廓 img_copy = img.copy() cv2.drawContours(img_copy, contr, -1, (0, 0, 255), 2) # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack((img[:640, :480], img_copy[:640, :480]))) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
3.3 计算面积和周长
轮廓面积是指每个轮廓中所有的像素点围成区域的面积,单位为像素
轮廓面积是轮廓重要的统计特性之一,通过轮廓面积的大小可以进一步分析每一个轮廓隐含的信息,例如:通过轮廓面积区分物体大小,识别不同物体
在查找到轮廓后,可能会有很多细小的轮廓,我们可以通过轮廓的面积进行过滤
语法:
contourArea(contour):计算面积arcLength(curve, closed):计算周长
参数:
curve:轮廓closed:是否是闭合的轮廓
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo8.py" __time__ = "2022/7/18 16:04" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) img_ = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) # 转化为RGB色道 # 图片二值化处理 img_ = cv2.adaptiveThreshold(img_, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 0) # 查找轮廓 contr, hiera = cv2.findContours(img_, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) # 绘制轮廓 img_copy = img.copy() cv2.drawContours(img_copy, contr, 1, (0, 0, 255), 2) # 计算面积和周长 area = cv2.contourArea(contr[1]) length = cv2.arcLength(contr[1], False) print(area, length) # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack((img[:640, :480], img_copy[:640, :480]))) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
3.4 多边形逼近与凸包
3.4.1 多边形逼近
findContours后的轮廓信息contours可能过于复杂不平滑,可以用approxPolyDP函数对该多边形曲线做适当近似,这就是轮廓的多边形逼近
approxPolyDP就是以多边形去逼近轮廓,采用的是Douglas-Peucker算法
DP算法原理比较简单,核心就是不断找多边形最远的点加入形成新的多边形,直到最短距离小于指定的精度
语法:approxPolyDP(curve, epsilon, closed[, approxCurve])
参数:
epsilon:即DP算法使用的阈值closed:轮廓是否闭合
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo8.py" __time__ = "2022/7/18 16:04" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) img_ = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) # 转化为RGB色道 # 图片二值化处理 img_ = cv2.adaptiveThreshold(img_, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 0) # 查找轮廓 contr, hiera = cv2.findContours(img_, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) # 绘制轮廓 img_copy = img.copy() cv2.drawContours(img_copy, contr, -1, (0, 0, 255), 1) # 使用多边形逼近,近似模拟手的轮廓 approx = cv2.approxPolyDP(contr[0], 10, True) # type: np.ndarry # 再次绘制轮廓 cv2.drawContours(img_copy, [approx], -1, (0, 255, 0), 2) # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack((img[:640, :480], img_copy[:640, :480]))) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
3.4.2 凸包
逼近多边形是轮廓的高度近似,但是有时候,我们希望使用一个多边形的凸包来简化它,凸包跟逼近多边形很像,只不过它是物体最外层的凸多边形,凸包指的是完全包含含有轮廓,并且仅有轮廓上的点所构成的多边形,凸包的每一个都是凸的,即在凸包内连接任意两点的直线都在凸包的内部。在凸包内,任意连续的三个点的内角小于180
语法:convexHull(points[, hull, clockwise[, returnPoints]])
参数:
points:轮廓clockwise:顺时针绘制
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo8.py" __time__ = "2022/7/18 16:04" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) img_ = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) # 转化为RGB色道 # 图片二值化处理 thersh, img_ = cv2.threshold(img_, 150, 255, cv2.THRESH_BINARY) # 查找轮廓 contr, hiera = cv2.findContours(img_, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) # 绘制轮廓 img_copy = np.zeros(img.shape, np.uint8) cv2.drawContours(img_copy, contr, -1, (0, 0, 255), 2) # 使用多边形逼近,近似模拟手的轮廓 hull = cv2.convexHull(contr[1]) print(hull) # 再次绘制轮廓 cv2.drawContours(img_copy, [hull], 0, (0, 255, 0), 2) # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack((img[:640, :480], img_copy[:640, :480]))) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
3.5 外接矩形
外接矩形分为最小外接矩形和最大外接矩形
# !/usr/bin/python3 # -*- coding: UTF-8 -*- __author__ = "A.L.Kun" __file__ = "demo8.py" __time__ = "2022/7/18 16:04" import cv2.cv2 as cv2 import numpy as np # 读取图像 img = cv2.imread("./img/1.jpg") assert isinstance(img, np.ndarray) img_ = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) # 转化为RGB色道 # 图片二值化处理 thersh, img_ = cv2.threshold(img_, 150, 255, cv2.THRESH_BINARY) # 查找轮廓 contr, hiera = cv2.findContours(img_, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) img_copy = np.zeros(img.shape, np.int8) cv2.drawContours(img_copy, contr, 1, (0, 0, 255), 2) # 最小外接矩形 # rect是一个Rotated Rect 旋转的矩形,矩形的真实坐标,矩形的长宽,矩形的旋转角度 rect = cv2.minAreaRect(contr[1]) # 绘制第二个轮廓下的,最小面积内接矩形 # 其实就是帮我们把旋转矩阵的4个坐标点计算出来了,注意坐标必须是整数的坐标,所以需要转换一下 box = cv2.boxPoints(rect) # 绘制旋转矩形 box = np.round(box).astype(np.int32) # 将浮点数转换为整型数据,四舍五入来转换 cv2.drawContours(img_copy, [box], 0, (0, 255, 0), 2) # 最大外接矩形,返回最大外接矩形的参数(x, y), (w, h) x, y, w, h = cv2.boundingRect(contr[1]) # 绘制第二个轮廓下的,最大外接矩形 cv2.rectangle(img_copy, (x, y), (x + w, y + h), (255, 0, 0), 2) # 显示图像 cv2.namedWindow("img", cv2.WINDOW_NORMAL) cv2.resizeWindow("img", 640, 480) cv2.imshow("img", np.hstack([img[:640, :480], img_copy[:640, :480]])) # 对图片进行截取一部分 cv2.waitKey(0) cv2.destroyAllWindows()
本文来自博客园,作者:Kenny_LZK,转载请注明原文链接:https://www.cnblogs.com/liuzhongkun/p/16493256.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!