

Flink组件及特性
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。目前主要还是依靠开源社区的贡献而发展。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。就框架本身与应用场景来说,Flink 更相似与 Storm。
1、Flink组件栈
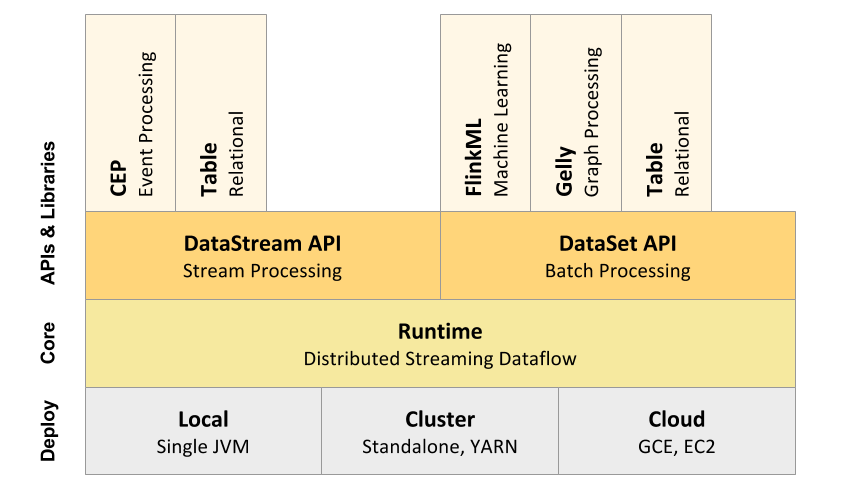
- 部署模式
Flink能部署在云上或者局域网中,提供了所中部署方案(Local、Cluster、Cloud),能在独立集群或者在被YARN或Mesos管理的集群上运行。
- 运行期
Flink的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理,这跟批次处理有很大不同。这个保证了上面说的那些Flink弹性和高性能的特性。
- API
DataStream API和DataSet API都会使用单独编译的处理方式(Separate compilation process)生成JobGraph。DataSet API使用Optimizer来决定针对程序的优化方法,而DataStream API则使用stream builder来完成该任务。
- 代码库
Flink附随了一些产生DataSet或DataStream API程序的的类库和API:处理逻辑表查询的Table,机器学习的FlinkML,图像处理的Gelly,事件处理的CEP
2、Flink特性
- 流处理特性
ü 支持高吞吐、低延迟、高性能的流处理
ü 支持带有事件时间的窗口(Window)操作
ü 支持有状态计算的Exactly-once语义
ü 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
ü 支持具有Backpressure功能的持续流模型
ü 支持基于轻量级分布式快照(Snapshot)实现的容错
ü 一个运行时同时支持Batch on Streaming处理和Streaming处理
ü Flink在JVM内部实现了自己的内存管理
ü 支持迭代计算
ü 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
- API支持
ü 对Streaming数据类应用,提供DataStream API
ü 对批处理类应用,提供DataSet API(支持Java/Scala)
- Libraries支持
ü 支持机器学习(FlinkML)
ü 支持图分析(Gelly)
ü 支持关系数据处理(Table)
ü 支持复杂事件处理(CEP)
- 整合支持
ü 支持Flink on YARN
ü 支持HDFS
ü 支持来自Kafka的输入数据
ü 支持Apache HBase
ü 支持Hadoop程序
ü 支持Tachyon
ü 支持ElasticSearch
ü 支持RabbitMQ
ü 支持Apache Storm
ü 支持S3
ü 支持XtreemFS

