
HAWQ技术总结
HAWQ技术总结:
1、 官网: http://hawq.incubator.apache.org/
2、 特性
2.1 sql支持完善
ANSI SQL标准,OLAP扩展,标准JDBC/ODBC支持。
2.2 具有MPP的性能。
2.3 支持外部数据整合。
HAWQ能够访问HDFS上的Json文件、Hive、HBase等外部数据。
2.4 支持ACID事务。
这是很多现有基于SqlonHadoop引擎无法做到的,能够好的保证数据一致性。
3、 优缺点:
优点:
* sql支持度好:目前能支持SQL99,SQL2003标准
* 支持事务。
* 支持insert
缺点:
* 基于GreenPlum实现,技术实现复杂,包含多个组件。比如对于外部数据源,需要通过PXF单独进行处理;
* C++实现,对内存的控制比较复杂,如果出现segmentfault直接导致当前node挂掉。
* 安装配置复杂;
4、 关键技术:
4.1 系统架构与关键组件
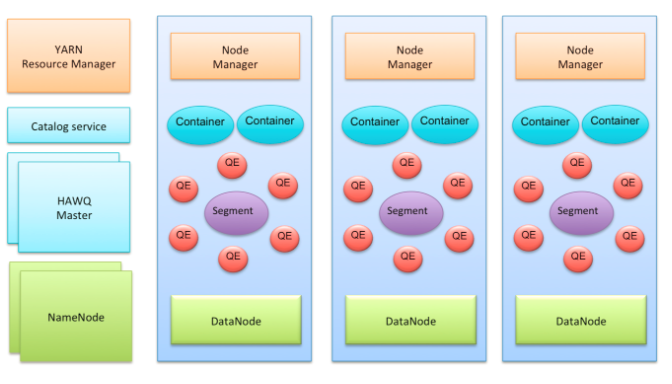
HAWQ集群的主要组件。其中有几个Master节点:包括HAWQ master节点,HDFS master节点NameNode,YARN master节点ResourceManager。每个Slave节点上部署有HDFS DataNode,YARN NodeManager以及一个HAWQ Segment。HAWQ Segment在执行查询的时候会启动多个QE (Query Executor, 查询执行器)。
查询执行器运行在资源容器里。在这个架构下,节点可以动态的加入集群,并且不需要数据重分布。当一个节点加入集群时,它会向HAWQ++ Master节点发送心跳,然后就可以接收未来查询了。
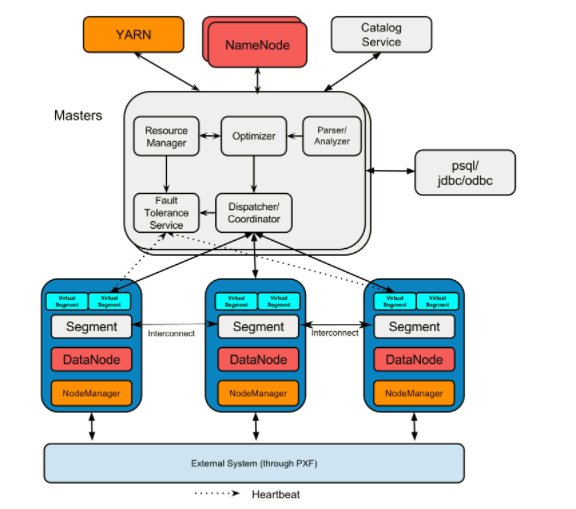
上图是HAWQ master节点内部架构图。可以看到在HAWQ的 Master节点内部有如下重要组件:查询解析器,优化器,资源代理,资源管理器,HDFS元数据缓存,容错服务,查询派遣器和元数据服务。在Slave节点上安装有一个物理Segment,在查询执行时,针对一个查询,弹性执行引擎会启动多个虚拟Segment同时执行查询,节点间数据交换通过Interconnect(高速互联网络,基于UDP)进行。如果一个查询启动了1000个虚拟Segment,意思是这个查询被均匀的分成了1000份任务,这些任务会并行执行。
其中,资源管理器通过资源代理向全局资源管理器(比如YARN)动态申请资源,并缓存资源。在不需要的时候返回资源。缓存资源的主要原因是减少HAWQ与yarn之间的交互代价。因为HAWQ是支持ms级查询。如果每一个查询都向资源管理器申请资源的话,性能会受到影响。位置信息存储在HDFS NameNode上。如果每个查询都访问HDFS NameNode会造成NameNode的瓶颈。所以在HAWQ Master节点上建立了HDFS元数据缓存。查询派遣器则是在优化完查询以后,蒋计划派遣到各个节点上执行,并协调查询执行。
4.2 PXF扩展框架
HAWQ通过名为Pivotal eXtension Framework(PXF)的模块提供数据联合功能。除了常见的数据联合功能外,PXF还利用SQL on Hadoop提供可扩展的功能,PXF提供框架API 使得开发人员能够数据堆栈开发新的连接器,从而增强强数据引擎的松散耦合。
4.3 GPORCA查询优化器
在分区查询、子查询、去重聚合、insert上改进优化。
5、 Benchmark
完全支持TPC-DS.
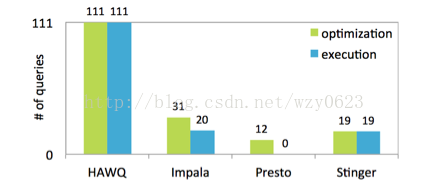
图中所示的基准测试是通过TPC-DS中的99个模板生成的111个查询来执行的。图中显示了4种基于SQL-on-Hadoop常见系统的合规等级,绿色和蓝色分别表示:每个系统可以优化的查询个数;可以完成执行并返回查询结果的查询个数。从图中可以看到,HAWQ完成了所有查询
