
kudu基础入门
一、背景介绍
在KUDU之前,大数据主要以两种方式存储;
(1)静态数据:
以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。这类存储的局限性是数据无法进行随机的读写。
(2)动态数据:
以 HBase、Cassandra 作为存储引擎,适用于大数据随机读写场景。这类存储的局限性是批量读取吞吐量远不如 HDFS,不适用于批量数据分析的场景。
从上面分析可知,这两种数据在存储方式上完全不同,进而导致使用场景完全不同,但在真实的场景中,边界可能没有那么清晰,面对既需要随机读写,又需要批量分析的大数据场景,该如何选择呢?这个场景中,单种存储引擎无法满足业务需求,我们需要通过多种大数据工具组合来满足这一需求。
数据实时写入 HBase,实时的数据更新也在 HBase 完成,为了应对 OLAP 需求,我们定时(通常是 T+1 或者 T+H)将 HBase 数据写成静态的文件(如:Parquet)导入到 OLAP 引擎(如:HDFS)。这一架构能满足既需要随机读写,又可以支持 OLAP 分析的场景。但是缺点也比较明显:
(1)架构复杂。从架构上看,数据在HBase、消息队列、HDFS 间流转,涉及环节太多,运维成本很高。并且每个环节需要保证高可用,都需要维护多个副本,存储空间也有一定的浪费。最后数据在多个系统上,对数据安全策略、监控等都提出了挑战。
(2)时效性低。数据从HBase导出成静态文件是周期性的,一般这个周期是一天(或一小时),在时效性上不是很高。
(3)难以应对后续的更新。真实场景中,总会有数据是延迟到达的。如果这些数据之前已经从HBase导出到HDFS,新到的变更数据就难以处理了,一个方案是把原有数据应用上新的变更后重写一遍,但这代价又很高。
为了解决上述架构的这些问题,KUDU应运而生。KUDU的定位是Fast Analytics on Fast Data,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。
二、kudu基础
2.1 使用场景
适用于那些既有随机访问,也有批量数据扫描的复合场景、高计算量的场景、使用了高性能的存储设备,包括使用更多的内存、支持数据更新,避免数据反复迁移、支持跨地域的实时数据备份和查询。
2.2 kudu架构
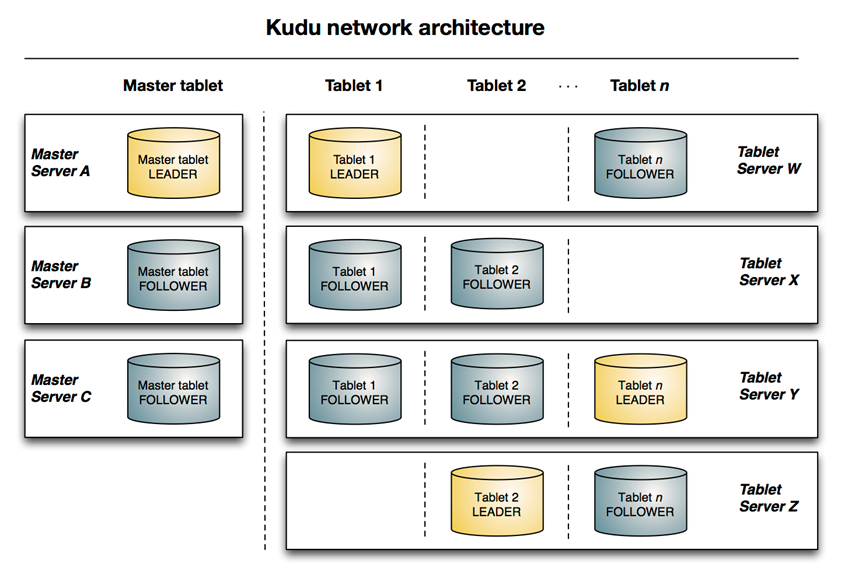
与HDFS和HBase相似,Kudu使用单个的Master节点,用来管理集群的元数据,并且使用任意数量的Tablet Server(可对比理解HBase中的RegionServer角色)节点用来存储实际数据。可以部署多个Master节点来提高容错性。一个table表的数据,被分割成1个或多个Tablet,Tablet被部署在Tablet Server来提供数据读写服务。
一些基本概念:
Master:集群中的老大,负责集群管理、元数据管理等功能
Tablet Server: 集群中的小弟,负责数据存储,并提供数据读写服务。一个 tablet server 存储了table表的tablet 和为 tablet 向 client 提供服务。对于给定的 tablet,一个tablet server 充当 leader,其他 tablet server 充当该 tablet 的 follower 副本。只有 leader服务写请求,然而 leader 或 followers 为每个服务提供读请求 。一个 tablet server 可以服务多个 tablets ,并且一个 tablet 可以被多个 tablet servers 服务着。
Table(表):一张table是数据存储在Kudu的tablet server中。表具有 schema 和全局有序的primary key(主键)。table 被分成称为 tablets 的 segments。
Tablet:一个 tablet 是一张 table连续的segment,tablet是kudu表的水平分区,类似于google Bigtable的tablet,或者HBase的region。每个tablet存储着一定连续range的数据(key),且tablet两两间的range不会重叠。一张表的所有tablet包含了这张表的所有key空间。与其它数据存储引擎或关系型数据库中的 partition(分区)相似。给定的tablet 冗余到多个 tablet 服务器上,并且在任何给定的时间点,其中一个副本被认为是leader tablet。任何副本都可以对读取进行服务,并且写入时需要在为 tablet 服务的一组 tablet server之间达成一致性。
三、kudu分区
为了提供可扩展性,Kudu 表被划分为称为 tablets 的单元,并分布在许多 tablet servers 上。行总是属于单个tablet 。将行分配给 tablet 的方法由在表创建期间设置的表的分区决定。 kudu提供了3种分区方式。
3.1 Range Partitioning ( 范围分区 )
范围分区可以根据存入数据的数据量,均衡的存储到各个机器上,防止机器出现负载不均衡现象.


1 /** 2 3 * 测试分区: 4 5 * RangePartition 6 7 */ 8 9 @Test 10 11 public void testRangePartition() throws KuduException { 12 13 //设置表的schema 14 15 LinkedList<ColumnSchema> columnSchemas = new LinkedList<ColumnSchema>(); 16 17 columnSchemas.add(newColumn("CompanyId", Type.INT32,true)); 18 19 columnSchemas.add(newColumn("WorkId", Type.INT32,false)); 20 21 columnSchemas.add(newColumn("Name", Type.STRING,false)); 22 23 columnSchemas.add(newColumn("Gender", Type.STRING,false)); 24 25 columnSchemas.add(newColumn("Photo", Type.STRING,false)); 26 27 28 29 //创建schema 30 31 Schema schema = new Schema(columnSchemas); 32 33 34 35 //创建表时提供的所有选项 36 37 CreateTableOptions tableOptions = new CreateTableOptions(); 38 39 //设置副本数 40 41 tableOptions.setNumReplicas(1); 42 43 //设置范围分区的规则 44 45 LinkedList<String> parcols = new LinkedList<String>(); 46 47 parcols.add("CompanyId"); 48 49 //设置按照那个字段进行range分区 50 51 tableOptions.setRangePartitionColumns(parcols); 52 53 54 55 /** 56 57 * range 58 59 * 0 < value < 10 60 61 * 10 <= value < 20 62 63 * 20 <= value < 30 64 65 * ........ 66 67 * 80 <= value < 90 68 69 * */ 70 71 int count=0; 72 73 for(int i =0;i<10;i++){ 74 75 //范围开始 76 77 PartialRow lower = schema.newPartialRow(); 78 79 lower.addInt("CompanyId",count); 80 81 82 83 //范围结束 84 85 PartialRow upper = schema.newPartialRow(); 86 87 count +=10; 88 89 upper.addInt("CompanyId",count); 90 91 92 93 //设置每一个分区的范围 94 95 tableOptions.addRangePartition(lower,upper); 96 97 } 98 99 100 101 try { 102 103 kuduClient.createTable("student",schema,tableOptions); 104 105 } catch (KuduException e) { 106 107 e.printStackTrace(); 108 109 } 110 111 kuduClient.close(); 112 113 }
3.2 Hash Partitioning (哈希分区)
哈希分区通过哈希值将行分配到许多 buckets ( 存储桶 )之一; 哈希分区是一种有效的策略,当不需要对表进行有序访问时。哈希分区对于在 tablet 之间随机散布这些功能是有效的,这有助于减轻热点和 tablet 大小不均匀。
1 /** 2 3 * 测试分区: 4 5 * hash分区 6 7 */ 8 9 @Test 10 11 public void testHashPartition() throws KuduException { 12 13 //设置表的schema 14 15 LinkedList<ColumnSchema> columnSchemas = new LinkedList<ColumnSchema>(); 16 17 columnSchemas.add(newColumn("CompanyId", Type.INT32,true)); 18 19 columnSchemas.add(newColumn("WorkId", Type.INT32,false)); 20 21 columnSchemas.add(newColumn("Name", Type.STRING,false)); 22 23 columnSchemas.add(newColumn("Gender", Type.STRING,false)); 24 25 columnSchemas.add(newColumn("Photo", Type.STRING,false)); 26 27 28 29 //创建schema 30 31 Schema schema = new Schema(columnSchemas); 32 33 34 35 //创建表时提供的所有选项 36 37 CreateTableOptions tableOptions = new CreateTableOptions(); 38 39 //设置副本数 40 41 tableOptions.setNumReplicas(1); 42 43 //设置范围分区的规则 44 45 LinkedList<String> parcols = new LinkedList<String>(); 46 47 parcols.add("CompanyId"); 48 49 //设置按照那个字段进行range分区 50 51 tableOptions.addHashPartitions(parcols,6); 52 53 try { 54 55 kuduClient.createTable("dog",schema,tableOptions); 56 57 } catch (KuduException e) { 58 59 e.printStackTrace(); 60 61 } 62 63 64 kuduClient.close(); 65 66 }
3.3 Multilevel Partitioning ( 多级分区 )
Kudu 允许一个表在单个表上组合多级分区。 当正确使用时,多级分区可以保留各个分区类型的优点,同时减少每个分区的缺点需求.
1 /** 2 3 * 测试分区: 4 5 * 多级分区 6 7 * Multilevel Partition 8 9 * 混合使用hash分区和range分区 10 11 * 12 13 * 哈希分区有利于提高写入数据的吞吐量,而范围分区可以避免tablet无限增长问题, 14 15 * hash分区和range分区结合,可以极大的提升kudu的性能 16 17 */ 18 19 @Test 20 21 public void testMultilevelPartition() throws KuduException { 22 23 //设置表的schema 24 25 LinkedList<ColumnSchema> columnSchemas = new LinkedList<ColumnSchema>(); 26 27 columnSchemas.add(newColumn("CompanyId", Type.INT32,true)); 28 29 columnSchemas.add(newColumn("WorkId", Type.INT32,false)); 30 31 columnSchemas.add(newColumn("Name", Type.STRING,false)); 32 33 columnSchemas.add(newColumn("Gender", Type.STRING,false)); 34 35 columnSchemas.add(newColumn("Photo", Type.STRING,false)); 36 37 38 39 //创建schema 40 41 Schema schema = new Schema(columnSchemas); 42 43 //创建表时提供的所有选项 44 45 CreateTableOptions tableOptions = new CreateTableOptions(); 46 47 //设置副本数 48 49 tableOptions.setNumReplicas(1); 50 51 //设置范围分区的规则 52 53 LinkedList<String> parcols = new LinkedList<String>(); 54 55 parcols.add("CompanyId"); 56 57 58 59 //hash分区 60 tableOptions.addHashPartitions(parcols,5); 61 62 63 64 //range分区 65 66 int count=0; 67 for(int i=0;i<10;i++){ 68 PartialRow lower = schema.newPartialRow(); 69 lower.addInt("CompanyId",count); 70 count+=10; 71 72 PartialRow upper = schema.newPartialRow(); 73 upper.addInt("CompanyId",count); 74 tableOptions.addRangePartition(lower,upper); 75 76 } 77 78 try { 79 80 kuduClient.createTable("cat",schema,tableOptions); 81 82 } catch (KuduException e) { 83 84 e.printStackTrace(); 85 86 } 87 88 kuduClient.close(); 89 90 }
四、kudu原理
4.1 表与schema
Kudu设计是面向结构化存储的,因此,Kudu的表需要用户在建表时定义它的Schema信息,这些Schema信息包含:列定义(含类型),Primary Key定义(用户指定的若干个列的有序组合)。数据的唯一性,依赖于用户所提供的Primary Key中的Column组合的值的唯一性。 Kudu提供了Alter命令来增删列,但位于Primary Key中的列是不允许删除的。 Kudu当前并不支持二级索引。 从用户角度来看,Kudu是一种存储结构化数据表的存储系统。在一个Kudu集群中可以定义任意数量的table,每个table都需要预先定义好schema。每个table的列数是确定的,每一列都需要有名字和类型,每个表中可以把其中一列或多列定义为主键。这么看来,Kudu更像关系型数据库,而不是像HBase、Cassandra和MongoDB这些NoSQL数据库。不过Kudu目前还不能像关系型数据一样支持二级索引。
Kudu使用确定的列类型,而不是类似于NoSQL的"everything is byte"。这可以带来两点好处: 确定的列类型使Kudu可以进行类型特有的编码。 可以提供 SQL-like 元数据给其他上层查询工具,比如BI工具。
4.2 kudu的底层数据模型
kudu的底层数据文件的存储,未采用HDFS这样的较高抽象层次的分布式文件系统,而是自行开发了一套可基于
Table/Tablet/Replica视图级别的底层存储系统。
这套实现基于如下的几个设计目标:
- 可提供快速的列式查询
- 可支持快速的随机更新
- 可提供更为稳定的查询性能保障
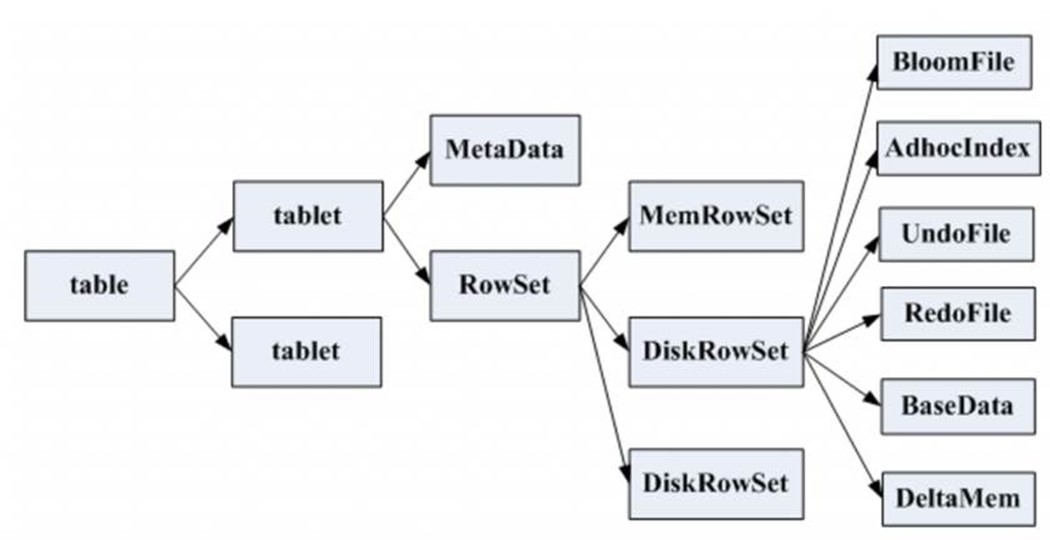
一张表会分成若干个tablet,每个tablet包括MetaData元信息及若干个RowSet,RowSet包含一个MemRowSet及若干个DiskRowSet,DiskRowSet中包含一个BloomFile、Ad_hoc Index、BaseData、DeltaMem及若干个RedoFile和UndoFile(UndoFile一般情况下只有一个)。
- MemRowSet:用于新数据insert及已在MemRowSet中的数据的更新,一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。每次到达32M生成一个DiskRowSet。
- DiskRowSet:用于老数据的变更(mutation),后台定期对DiskRowSet做compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。
- BloomFile:根据一个DiskRowSet中的key生成一个bloom filter,用于快速模糊定位某个key是否在DiskRowSet中存在。
- Ad_hocIndex:是主键的索引,用于定位key在DiskRowSet中的具体哪个偏移位置。
- BaseData是MemRowSet flush下来的数据,按列存储,按主键有序。
- UndoFile是基于BaseData之前时间的历史数据,通过在BaseData上apply UndoFile中的记录,可以获得历史数据。
- RedoFile是基于BaseData之后时间的变更(mutation)记录,通过在BaseData上apply RedoFile中的记录,可获得较新的数据。
- DeltaMem用于DiskRowSet中数据的变更mutation,先写到内存中,写满后flush到磁盘形成RedoFile。
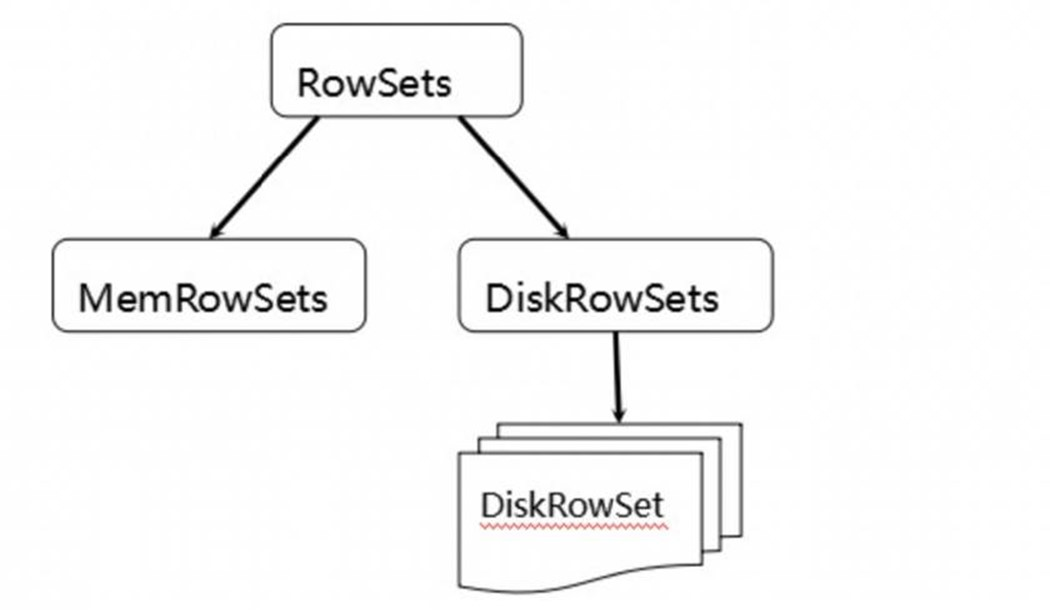
MemRowSets可以对比理解成HBase中的MemStore, 而DiskRowSets可理解成HBase中的HFile。MemRowSets中的数据按照行试图进行存储,数据结构为B-Tree。
MemRowSets中的数据被Flush到磁盘之后,形成DiskRowSets。
DisRowSets中的数据,按照32MB大小为单位,按序划分为一个个的DiskRowSet。 DiskRowSet中的数据按照Column进行组织,与Parquet类似。
这是Kudu可支持一些分析性查询的基础。每一个Column的数据被存储在一个相邻的数据区域,而这个数据区域进一步被细分成一个个的小的Page单元,与HBase File中的Block类似,对每一个Column Page可采用一些Encoding算法,以及一些通用的Compression算法。 既然可对Column Page可采用Encoding以及Compression算法,那么,对单条记录的更改就会比较困难了。
前面提到了Kudu可支持单条记录级别的更新/删除,是如何做到的?
与HBase类似,也是通过增加一条新的记录来描述这次更新/删除操作的。DiskRowSet是不可修改了,那么 KUDU 要如何应对数据的更新呢?在KUDU中,把DiskRowSet分为了两部分:base data、delta stores。base data 负责存储基础数据,delta stores负责存储 base data 中的变更数据.
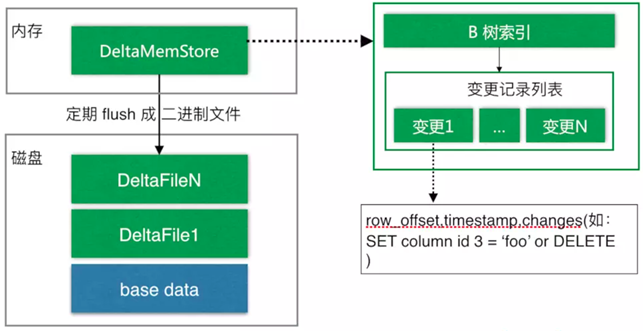
如上图所示,数据从 MemRowSet 刷到磁盘后就形成了一份 DiskRowSet(只包含 base data),每份 DiskRowSet 在内存中都会有一个对应的DeltaMemStore,负责记录此 DiskRowSet 后续的数据变更(更新、删除)。DeltaMemStore 内部维护一个 B-树索引,映射到每个 row_offset 对应的数据变更。DeltaMemStore 数据增长到一定程度后转化成二进制文件存储到磁盘,形成一个 DeltaFile,随着 base data 对应数据的不断变更,DeltaFile 逐渐增长。
4.3 kudu的写流程
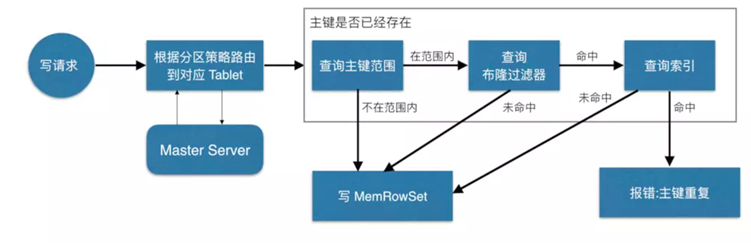
如上图,当 Client 请求写数据时,先根据主键从Master Server中获取要访问的目标 Tablets,然后到依次对应的Tablet获取数据。
因为KUDU表存在主键约束,所以需要进行主键是否已经存在的判断,这里就涉及到之前说的索引结构对读写的优化了。一个Tablet中存在很多个RowSets,为了提升性能,我们要尽可能地减少要扫描的RowSets数量。
首先,我们先通过每个 RowSet 中记录的主键的(最大最小)范围,过滤掉一批不存在目标主键的RowSets,然后在根据RowSet中的布隆过滤器,过滤掉确定不存在目标主键的 RowSets,最后再通过RowSets中的 B-树索引,精确定位目标主键是否存在。
如果主键已经存在,则报错(主键重复),否则就进行写数据(写 MemRowSet)。
4.4 kudu的读流程
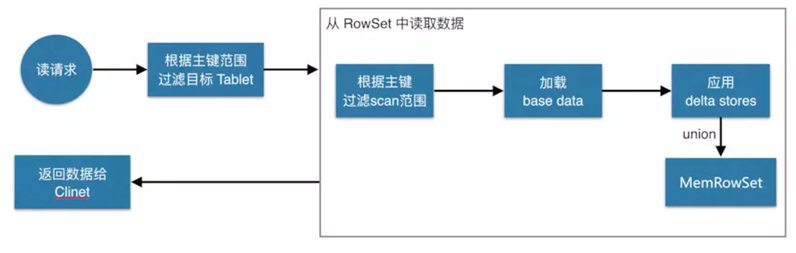
如上图,数据读取过程大致如下:先根据要扫描数据的主键范围,定位到目标的Tablets,然后读取Tablets 中的RowSets。
在读取每个RowSet时,先根据主键过滤要scan范围,然后加载范围内的base data,再找到对应的delta stores,应用所有变更,最后union上MemRowSet中的内容,返回数据给Client。
4.5 kudu的更新流程
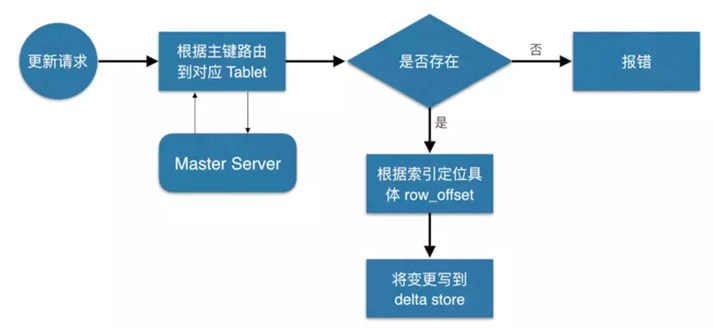
数据更新的核心是定位到待更新数据的位置,这块与写入的时候类似,就不展开了,等定位到具体位置后,然后将变更写到对应的delta store 中。
