ElasticSearch 6.2.3 Windows10 安装
一、安装Es
1、安装java,最新版本的ElasticSearch 需要java8 版本,因此需要先去Oracle官网下载jdk,下载之后就直接安装:
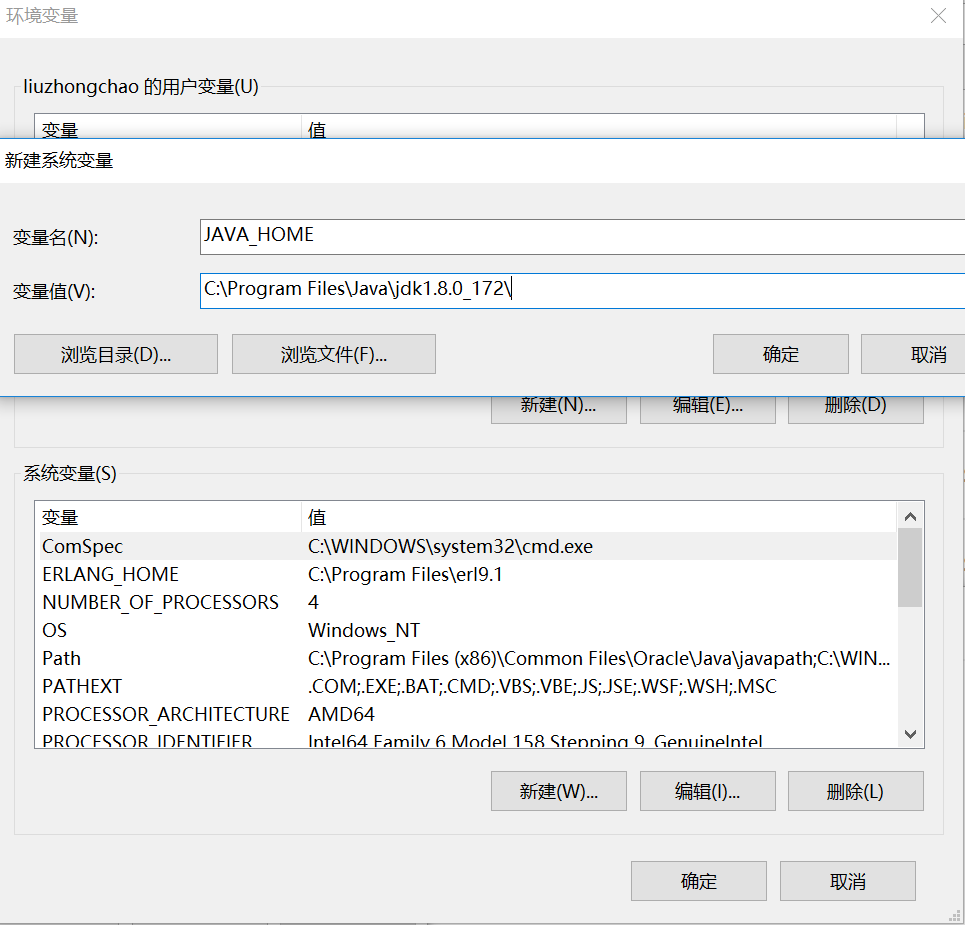
2、安装过程中将其安装目录copy下来:C:\Program Files\Java\jdk1.8.0_161\ 后续还需要将其添加到环境变量JAVA_HOME:
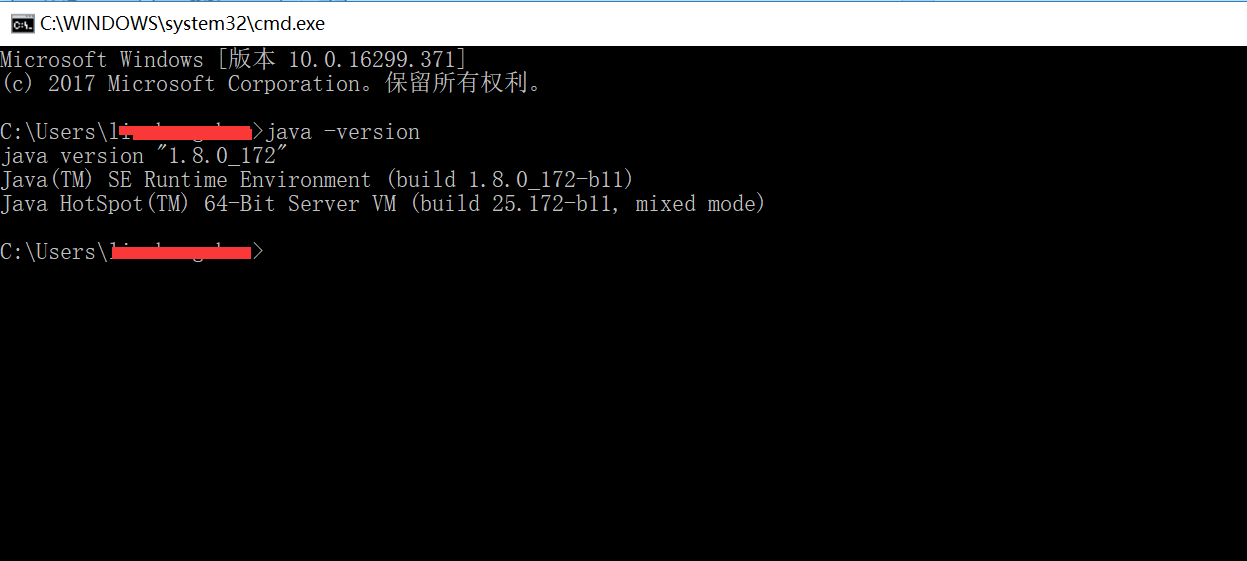
环境变量设置好之后,再通过命令行确认下:
3、安装Es有MSI安装程序和zip压缩包,现用MSI安装包来安装,官网下载地址,官网上有详细安装流程。
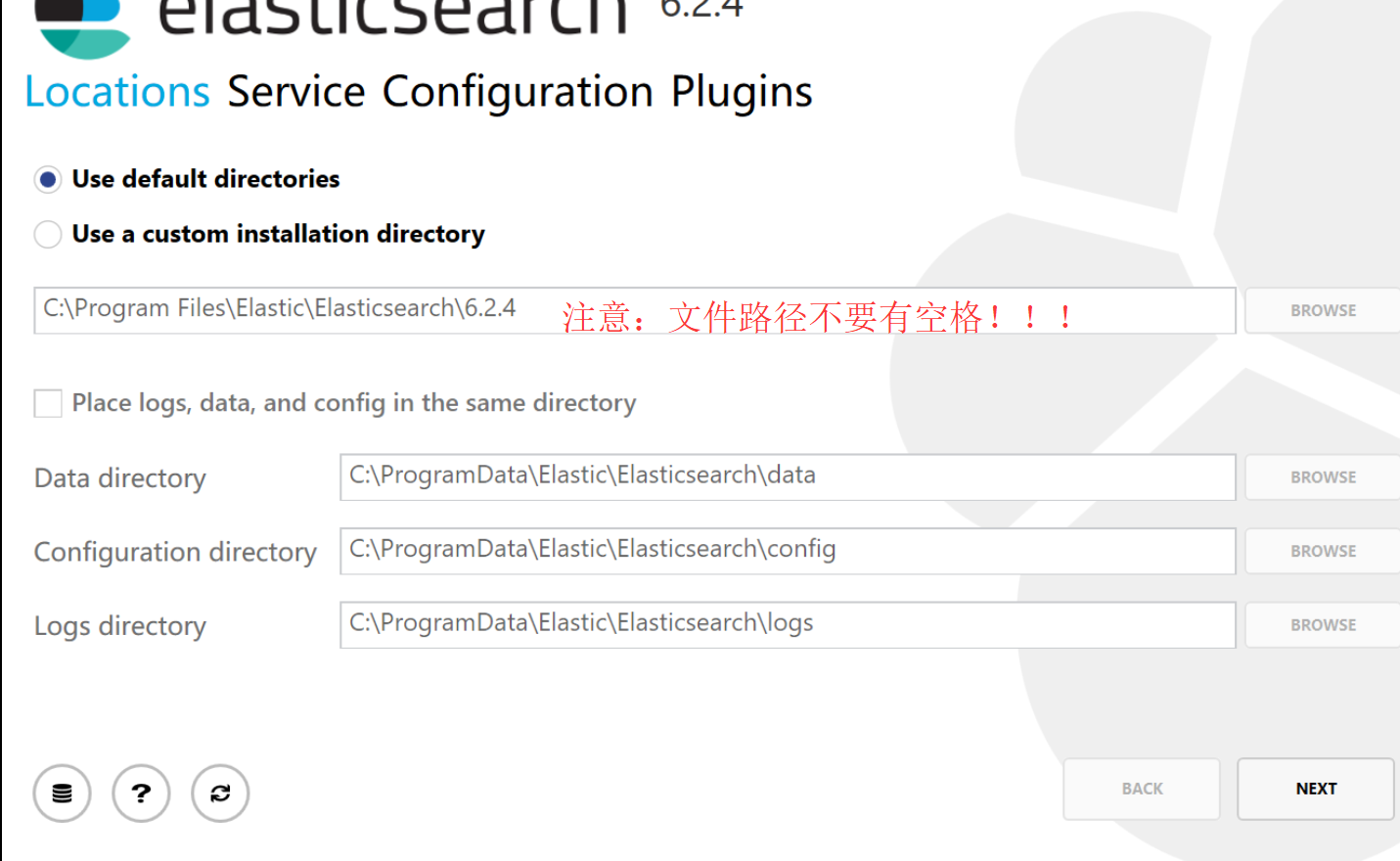
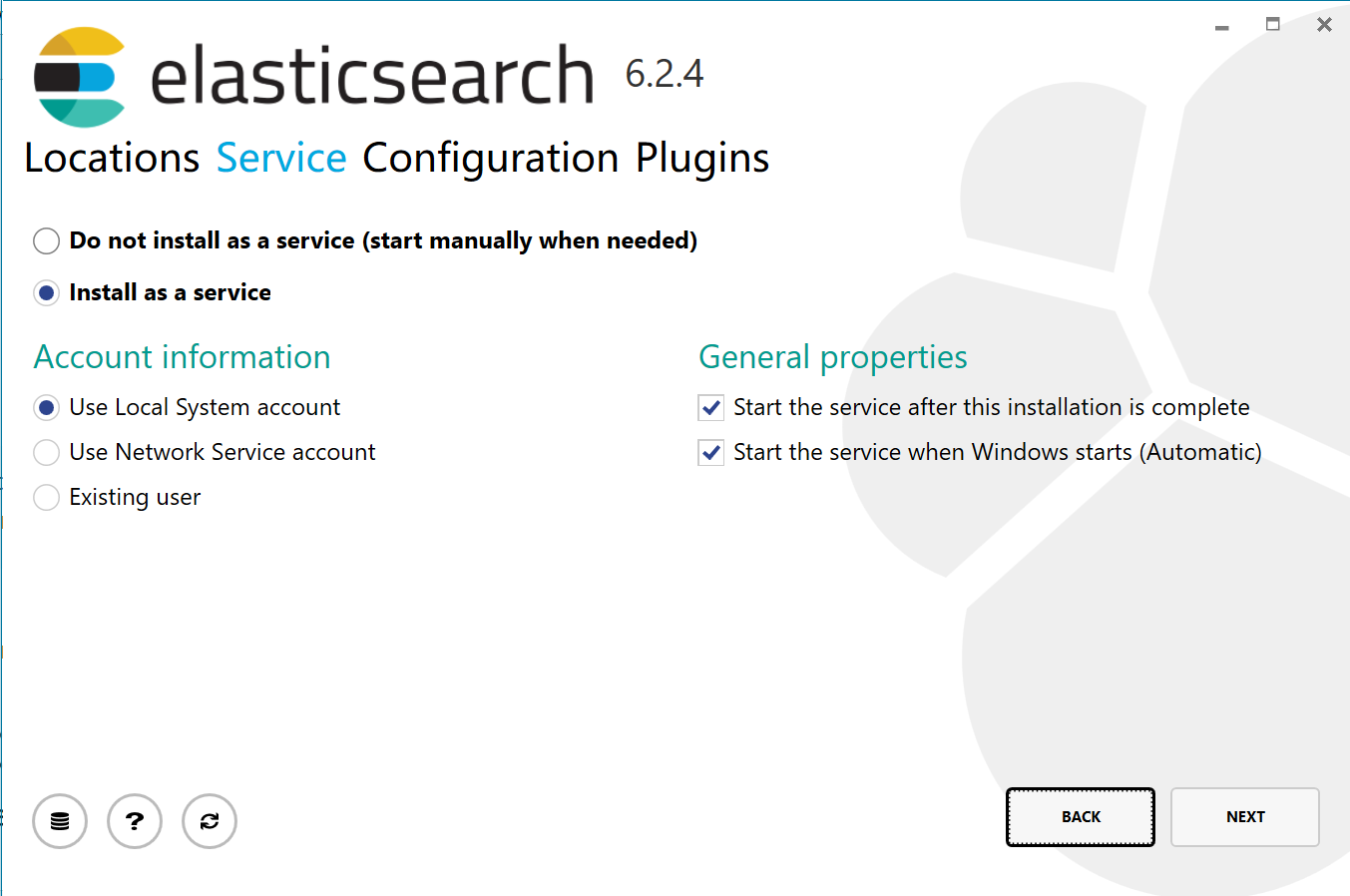
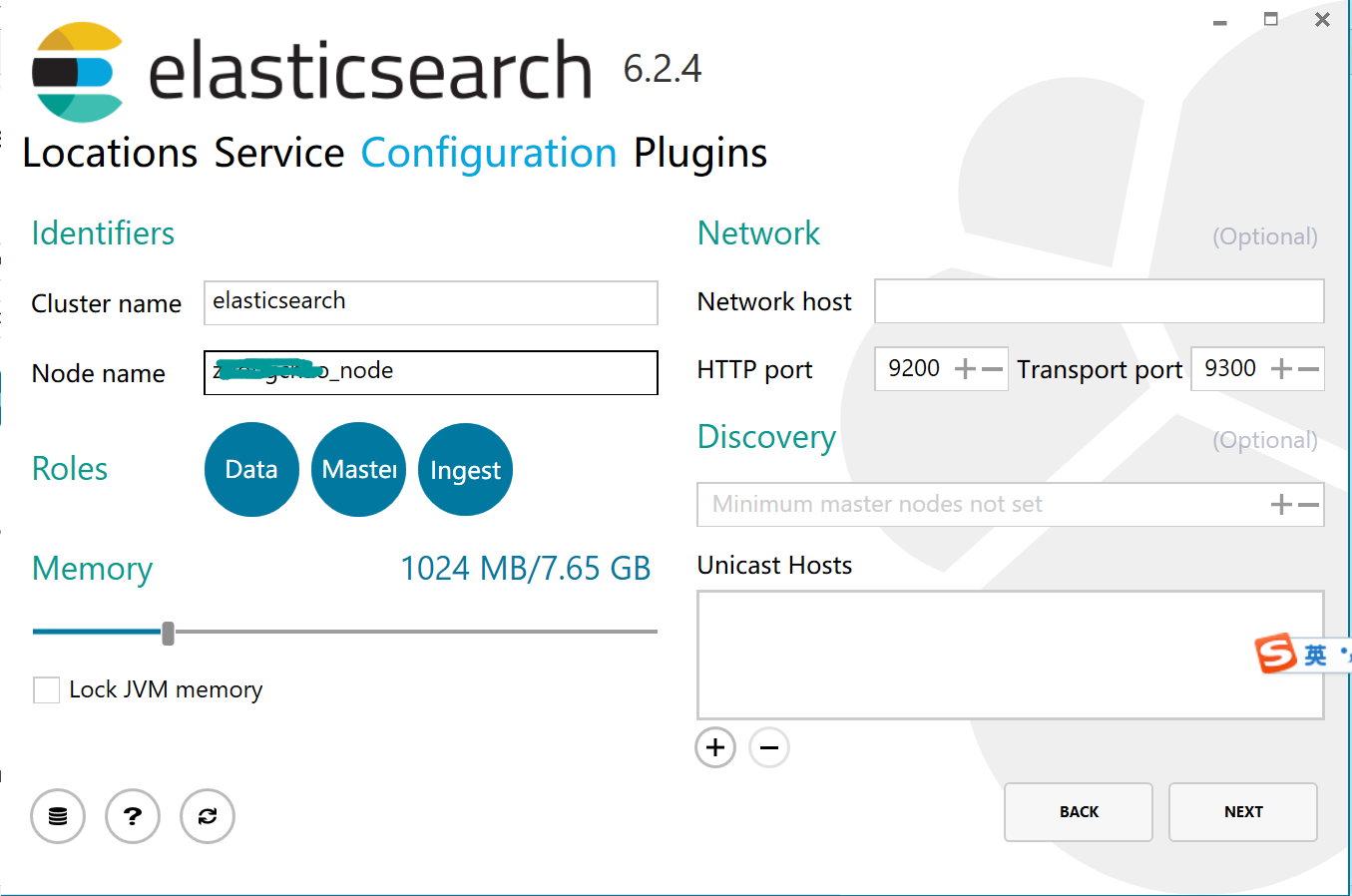
安装完成后,浏览器输入http://localhost:9200查看安装是否成功,成功安装如下:
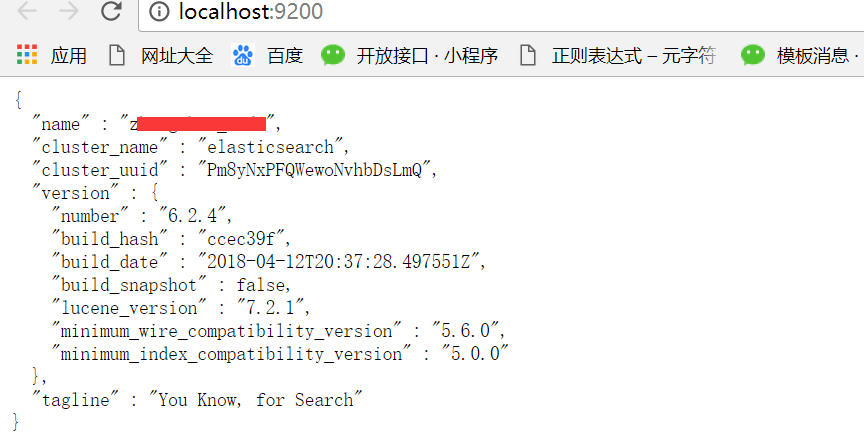
4、重启服务:在系统服务中找到elasticsearch服务,重启即可
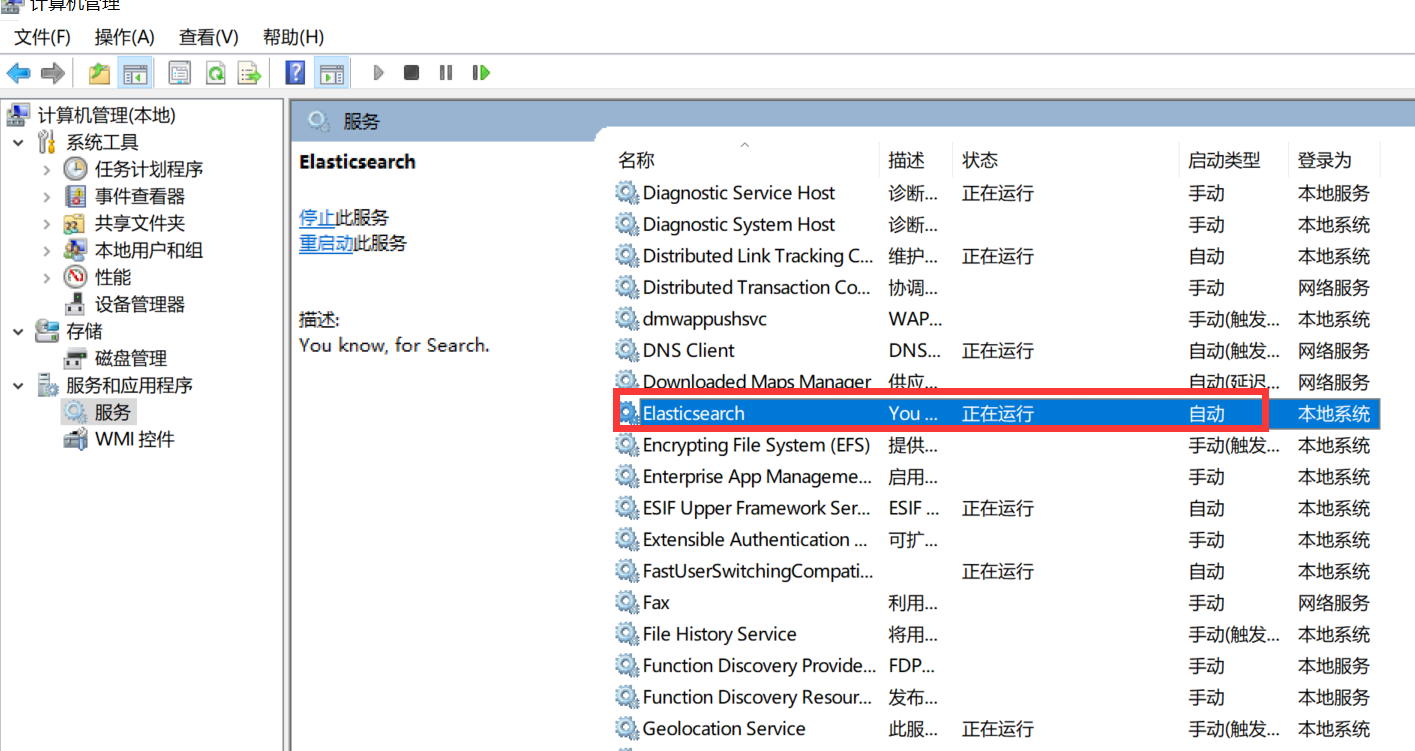
二、安装插件head
1、下载node.js ,网址:https://nodejs.org/en/
查看node.js版本
node -v
查看npm版本
npm -v
2、安装grunt
使用npm安装grunt
npm install -g grunt -cli
查看grunt版本
grunt -version
3、下载ElasticSearch-head压缩包,下载地址https://github.com/mobz/elasticsearch-head,下载后解压,执行
npm install
npm run start 或 grunt server 启动插件
输入http://localhost:9100/查看安装是否成功
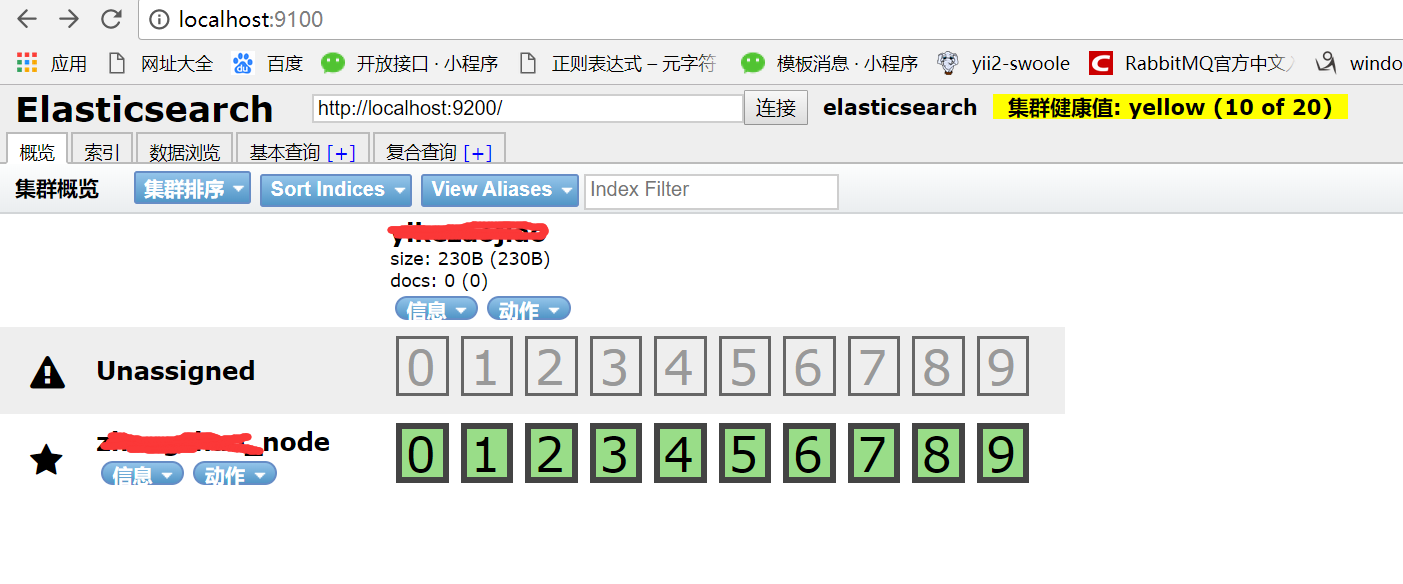
4、如果启动未成功,打开es配置文件config目录,找到es的配置文件elasticsearch.yml,在最后面添加如下代码
http.cors.enabled: true http.cors.allow-origin: "*"
重新启动es,查看是否启动成功
三、安装Kibana插件
Kibana 是一个开源分析和可视化平台,旨在可视化操作 Elasticsearch 。Kibana可以用来搜索,查看和与存储在 Elasticsearch 索引中的数据进行交互。可以轻松地进行高级数据分析,并可在各种图表,表格和地图中显示数据。
Kibana 可以轻松理解海量数据。其简单的基于浏览器的界面使您能够快速创建和共享动态仪表板,实时显示 Elasticsearch 查询的更改。
1、打开下载地址 https://www.elastic.co/downloads/kibana,下载后解压缩,打开其bin目录,执行Kinana,如下
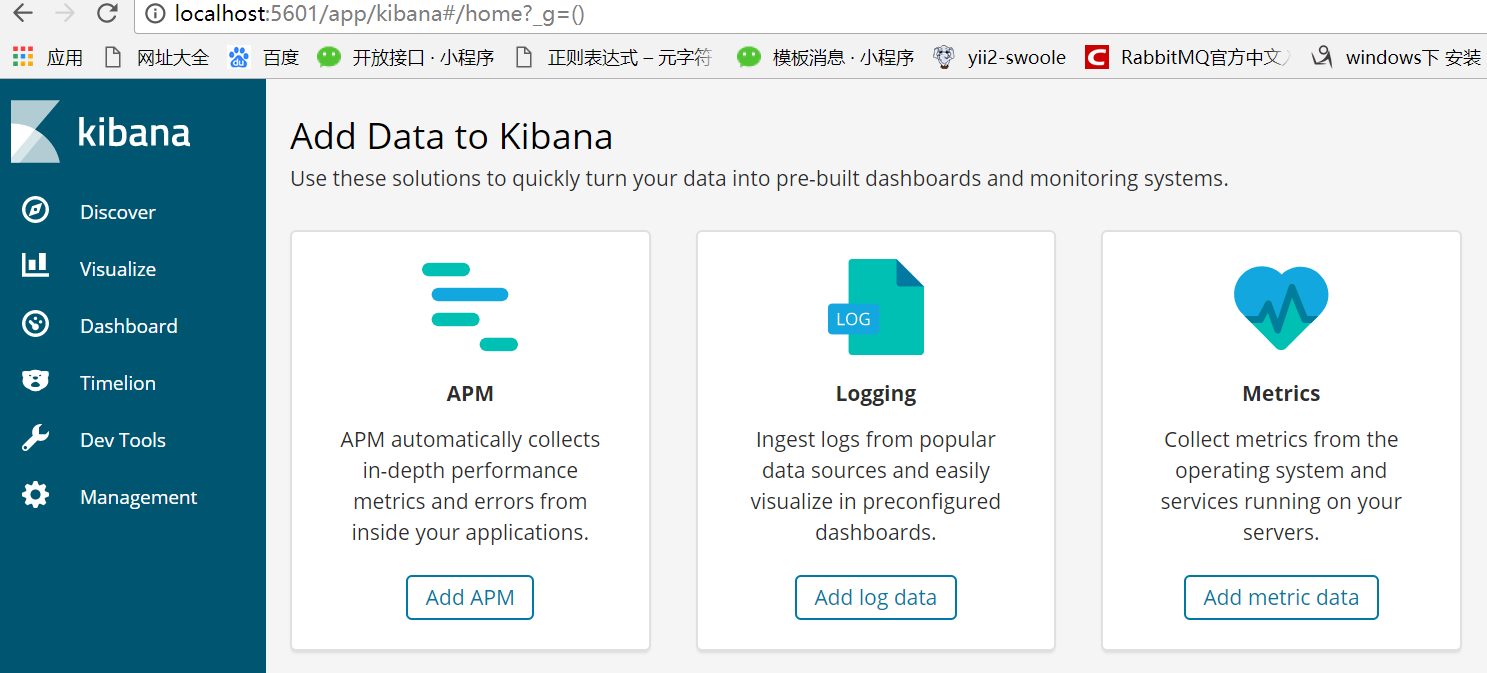
2、在浏览器中输入: http://localhost:5601 ,出现如下图所示安装成功
四、安装ik插件
1、安装Maven,安装方法请参考此教程
2、下载ik插件地址,https://github.com/medcl/elasticsearch-analysis-ik
3、下载完成解压,执行如下命令:
mvn clean package
编译完成后会在target\releases目录下生成elasticsearch-analysis-ik-6.2.3.zip文件,如下
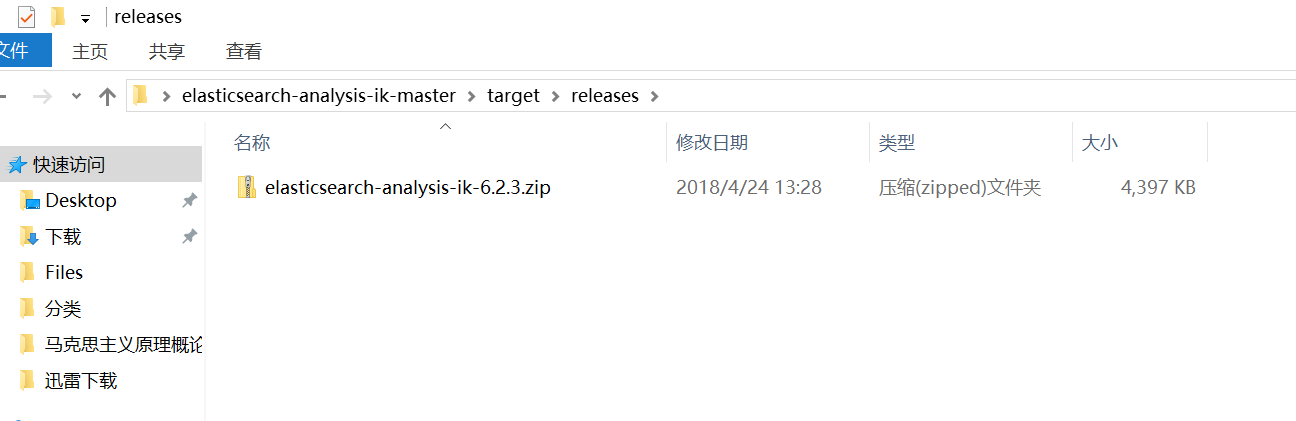
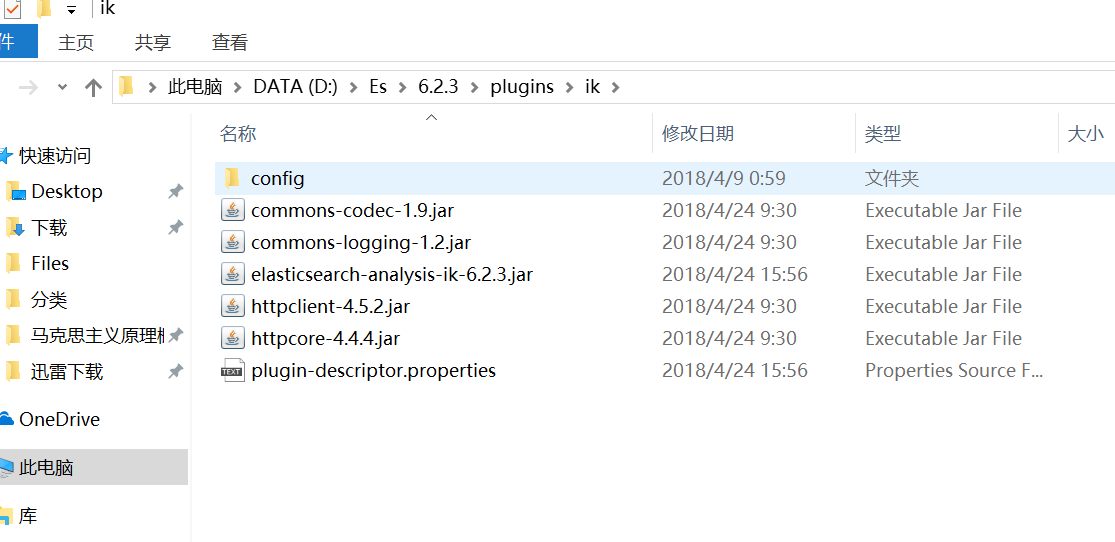
4、打开es的plugins目录D:\Es\6.2.3\plugins,新建ik目录,将刚才生成的elasticsearch-analysis-ik-6.2.3.zip文件解压,如下
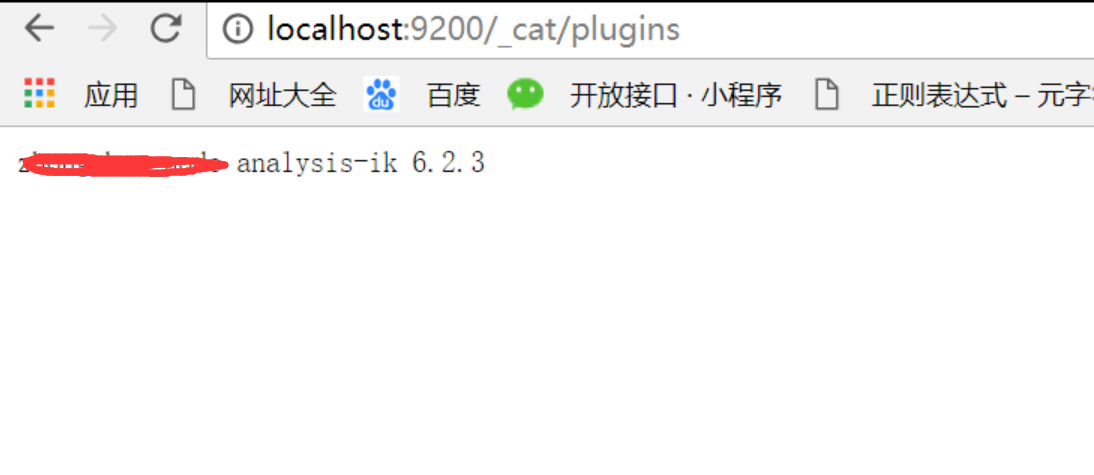
5、重启es,输入http://localhost:9200/_cat/plugins 查看安装是否成功,如下
5、测试分词功能
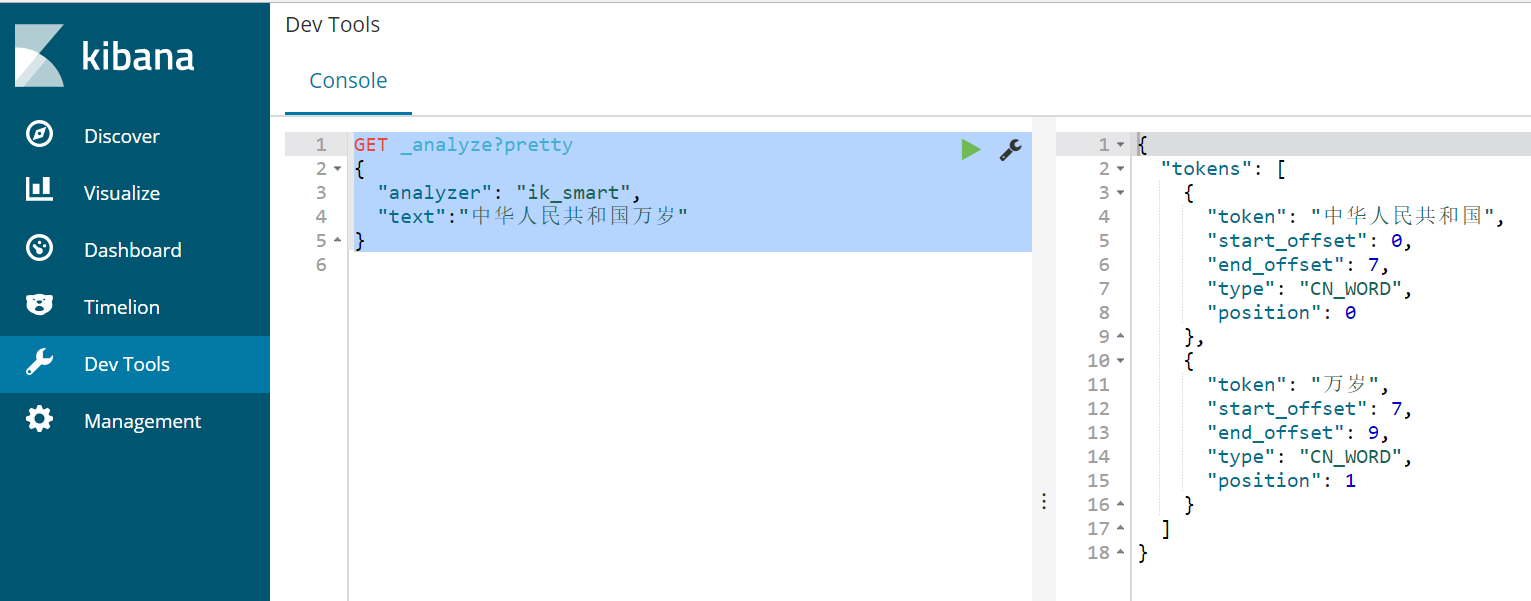
(1)ik_smart
其中pretty本意”漂亮的”,表示以美观的形式打印出JSON格式响应。
GET _analyze?pretty { "analyzer": "ik_smart", "text":"中华人民共和国万岁" }
(2)ik_max_word
GET _analyze?pretty { "analyzer": "ik_max_word", "text":"中华人民共和国万岁" }
分词结果:
{ "tokens": [ { "token": "中华人民共和国", "start_offset": 0, "end_offset": 7, "type": "CN_WORD", "position": 0 }, { "token": "中华人民", "start_offset": 0, "end_offset": 4, "type": "CN_WORD", "position": 1 }, { "token": "中华", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 2 }, { "token": "华人", "start_offset": 1, "end_offset": 3, "type": "CN_WORD", "position": 3 }, { "token": "人民共和国", "start_offset": 2, "end_offset": 7, "type": "CN_WORD", "position": 4 }, { "token": "人民", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 5 }, { "token": "共和国", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 }, { "token": "共和", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 7 }, { "token": "国", "start_offset": 6, "end_offset": 7, "type": "CN_CHAR", "position": 8 }, { "token": "万岁", "start_offset": 7, "end_offset": 9, "type": "CN_WORD", "position": 9 }, { "token": "万", "start_offset": 7, "end_offset": 8, "type": "TYPE_CNUM", "position": 10 }, { "token": "岁", "start_offset": 8, "end_offset": 9, "type": "COUNT", "position": 11 } ] }
五、实例
1、创建索引,使用kibana插件
PUT kid_search
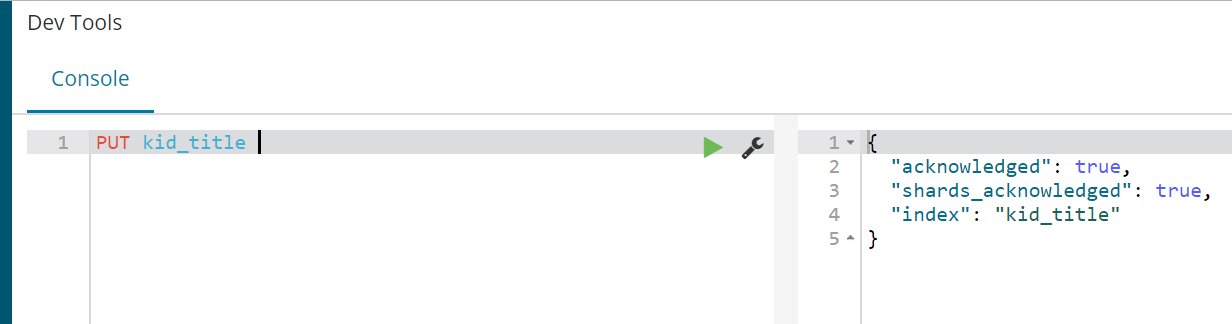
2、创建mapping
POST kid_search/_doc/_mapping { "properties": { "title": { "type": "text", "analyzer": "ik_smart", "search_analyzer": "ik_smart" } } }
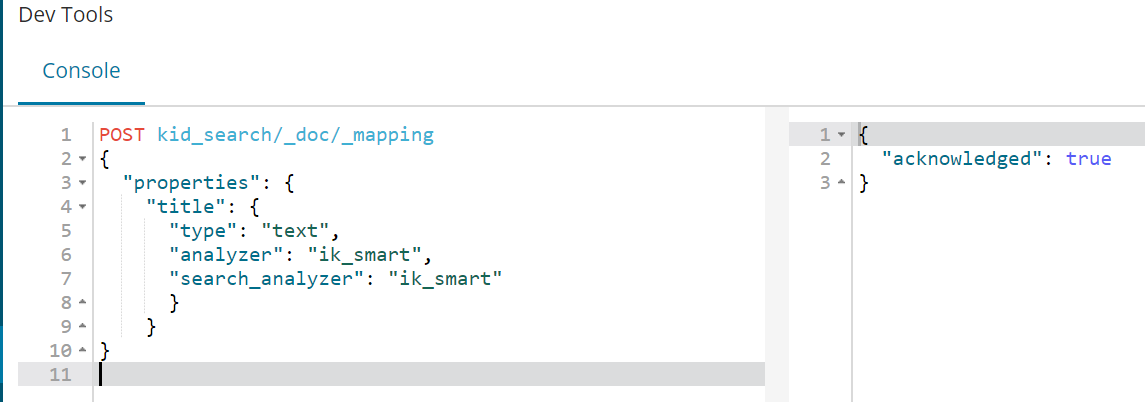
3、插入文档数据
POST kid_search/_doc { "title":"我爱你中国" } POST kid_search/_doc { "title":"中国你真美" } POST kid_search/_doc { "title":"我是中国人" } POST kid_search/_doc { "title":"中国人民" } POST kid_search/_doc { "title":"中国真伟大" }
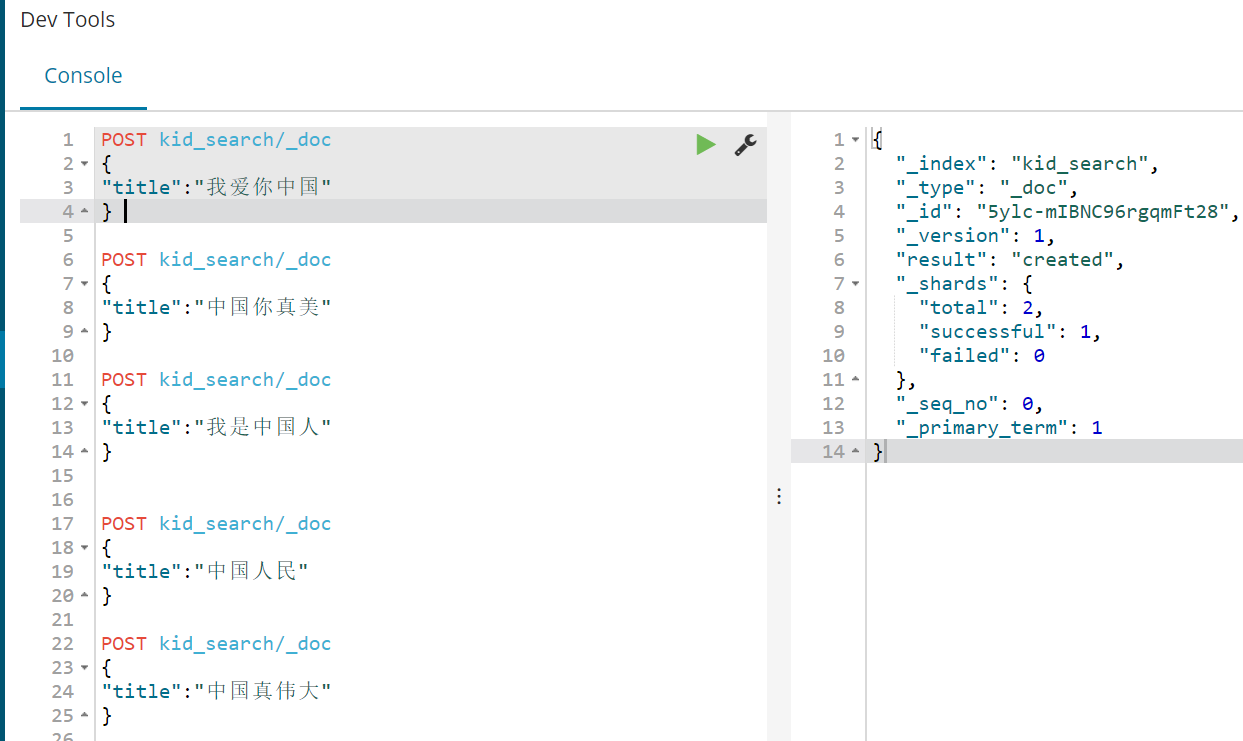
4、查看分词结果
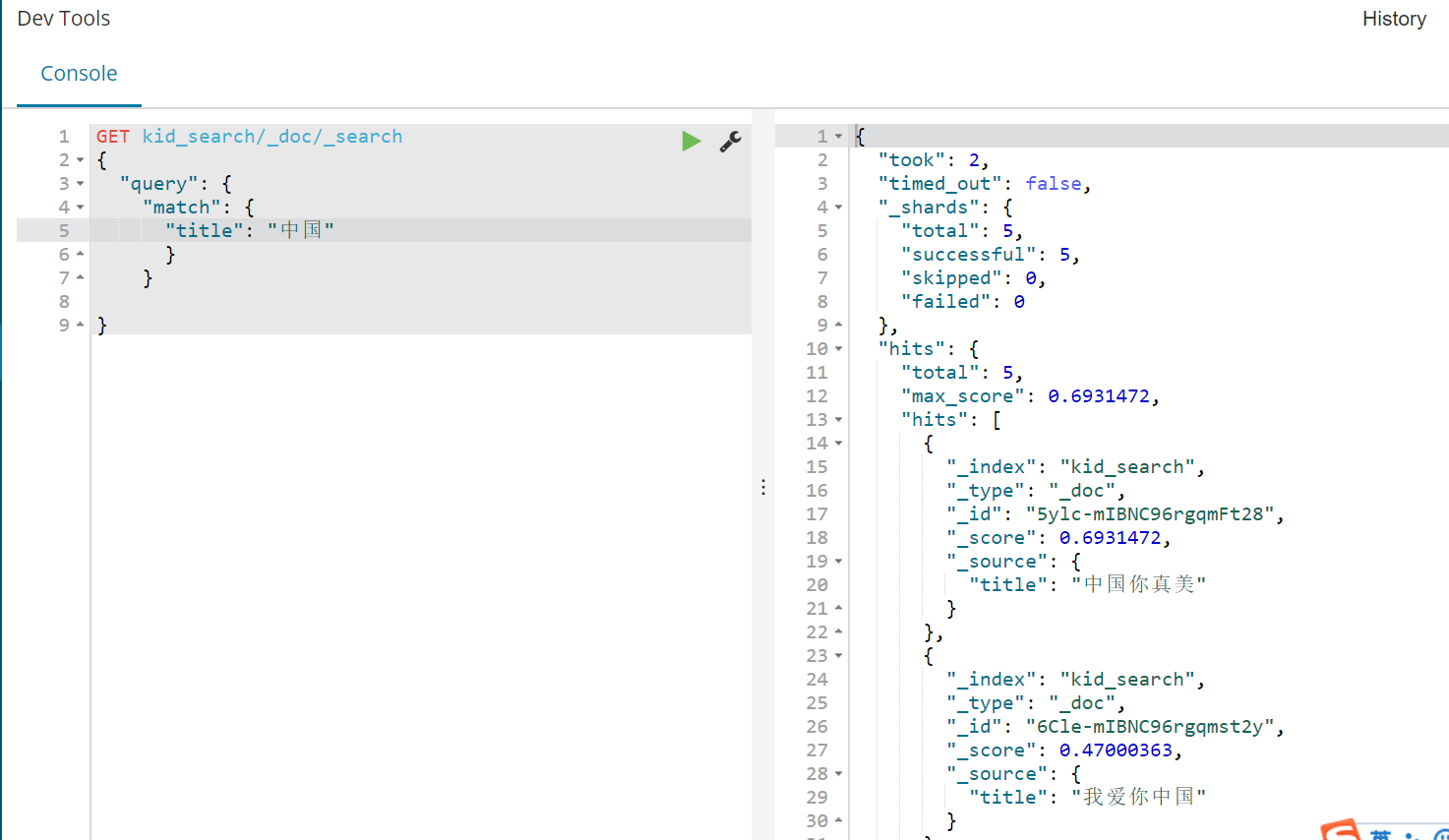
GET kid_search/_doc/_search { "query": { "match": { "title": "中国" } } }