


三十一、Gawk基础入门
AWK:Aho Weinberger Kernighan
awk :报告生成器、格式化文本输出
一、gawk - pattern scanning and processing language
基本用法:gawk [optins] 'program' FILE ... 语句之间用分号分割 选项: -F ' ' :指明输入时用到的字段分隔符 -v var=value :自定义变量
PATTERN: 定义读入哪些行时对行处理
ACTION :对行如何处理,文本格式化输出:print, printf 多个语句之间用“;”分开
二、工作模式:
默认读取全文 ,PATTERN只是决定能处理的行,同sed
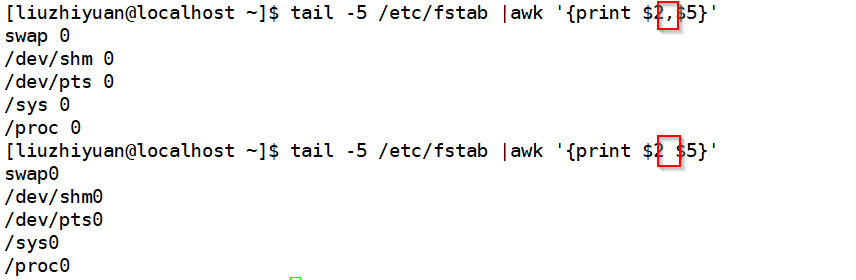
读取文件一行,以-F指定的输入字段分隔符切割字段,并且将每一片记录与awk内建的变量中,$1,$2,$3,...$#,$@,$0 ,支持行的字段条件判断,判断后此行满足时,显示此行的部分字段或对行内循环
注:默认以空格分隔,不管空白字符多少都只认为一个空白字符
三、变量
3.1、内建变量
a)、FS:input field seperator 默认为空白字符
e.g awk '{print $1}' /etc/passwd
awk -v FS=":" '{print $1,$3}' /etc/passwd
b)、OFS :output field seperator 默认为空白字符

c) 、RS:Raw Seperator 输入的换行符,默认为$
d)、ORS:Output Raw Seperator 输出时的换行符,默认为$
awk -v RS=":" -v ORS="^_^" '{print $1,$3}' /etc/passwd
e)、NF :Number of Raw 字段数量
$NF:每行最后一个字段
[root@redhat wilsontest]# awk '{print NF,NR,$0}END{print FILENAME}' filetest 2 1 hello wilson 1 2 world 1 3 linux 1 4 oracle 1 5 C++ 说明: 第一列NF输出读取记录的域的个数; NR表示已经读取的记录数; $0实际就是把记录输出出来; $0就表示一个记录,$1表示记录中的第一个字段。 一般 print $0 就是打印整行内容($0前面不需要反斜杠),print $1表示只打印每行第一个字段。
f)、NR :Number of Filed 文件中的行数
#awk '{print NR}' FILE
#awk '{print NR}' FILE1 FILE2 ... 对行进行累计计数
g)、FNR :对每一个文件单独计数
#awk '{print FNR}' FILE1 FILE2 ... 对每个文件分别计行数
h)、FILENAME:显示当前被处理的文件的文件名
#awk '{print FILENAME}' FILE1 FILE2
I)、ARGC : 命令行中给定的参数的个数
#awk '{print ARGC}' FILE1 FILE2
K)、ARGV :数组,保存的是命令行所给定的各参数

e.g
awk '{print ARGV[0]}' /etc/fstab /etc/issue =====》awk
awk '{print ARGV[1]}' /etc/fstab /etc/issue ======》/etc/fstab
awk '{print ARGV[2]}' /etc/fstab /etc/issue ======》/etc/issue
3.2、自定义变量
a) -v name="Obama"
变量名一样区分字符大小写
b) 在program中直接定义
{name="value";print name}
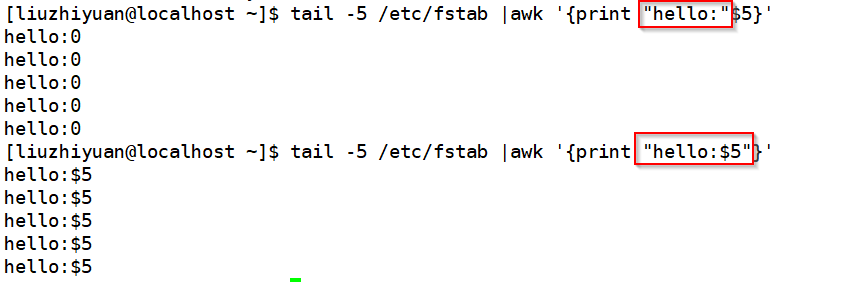
注:变量不能用$符,$符号表示字段
变量用能用"" ,""中的变量不会被替换
四、ACTION
4.1、print -----输出内容之后自动换行
print item1,item2,... 要点: a) 逗号分隔符 b) 默认输出分隔符为空白字符 c) 输出的各item可以字符串,也可以是数值;当前记录的字段、变量或awk的表达式 字符串 :"STRING" 变量: 不能被引号包含 即放在引号之内当做字符串,放在引号之外才能做变量替换 d) 如省略item ,相当于{print} ==》 {print $0}
4.2、printf-----可以自定义输出的模式,另外输出内容之后不自动换行
文本格式化输出:printf "FORMAT" ,item1,item2, ...
a)FORMAT是必须要输出
b) 不会自动换行,需要给出换行控制符:\n
b)format中需要分别为后面的每个item指定一个格式化符号
格式符:
%c : 显示字符的ASCII码
%d, %i :显示为十进制整数
%e :科学计数法 数值显示
%f : 显示为浮点数
%g,%G :以科学计数法或浮点形式显示数值
%s : 显示字符串
%u :无符号整数
%% :显示%自身
修饰符 :
#[.#] :第一数字控制显示的宽度;第二个#表示小数点后的精度
- :左对齐。默认为右对齐
+ : 显示数值的符号
e.g
awk -F : '{printf "%s,%d\n",$1,$2}' /etc/passwd
awk -F : '{printf "%-15s,%d\n",$1,$3}' /etc/passwd

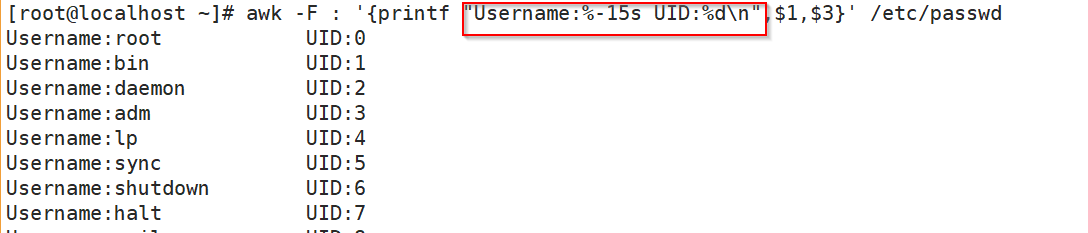
awk -F : '{printf "Username:%-15s UID:%d\n",$1,$3}' /etc/passwd
3、操作符


函数调用:函数名(argu1,argu2,...)
function_name(arg1,arg2,...) 规范式
内建条件表达式:
selector?if-ture-expression:if-false-expression
selector :条件表达式
?:看它为真或假
if-ture-expression :条件表达式为真时,执行
if-false-expression :条件表达式为假时,执行
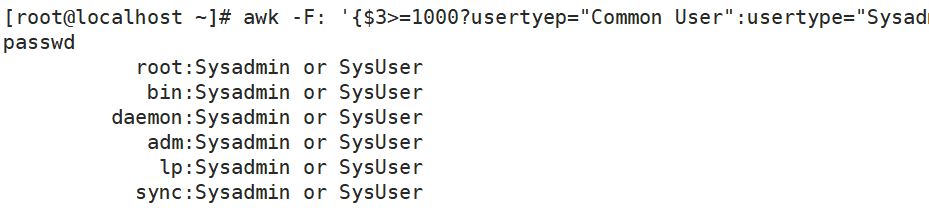
awk -F: '{$3>=1000?usertyep="Common User":usertype="Sysadmin or SysUser";printf "%15s:%s\n",$1,usertype}' /etc/passwd
五、PATTERN地址定界功能 :'PATTERN{ACTION STATEMENT}'
5.1、empty :处理文本的每一行,sed空模式,每一行都会进行script
5.2、/regex-pattern/ 仅处理能够被此处的模式所匹配到的行
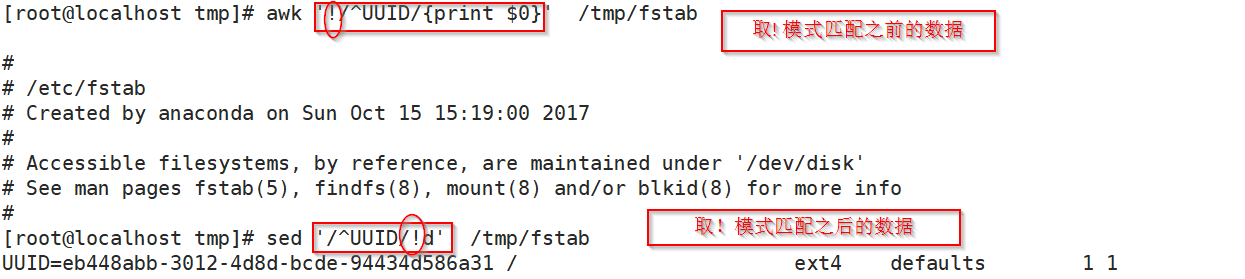
#awk '/^UUID/{print $1}' /etc/paawd
5.3、relational expression : 关系表达式,结果有“真”有“假” ---结果为“真”才会被处理
真:结果为非0值,非空字符串
0表示假;空串为假
#awk -F ':' ‘$3>=1000{print $1,$2}’ /etc/passwd 显示用户id大于1000的用户名
#awk -F ':' '$NF=="/bin/bash" {print $1,$NF}’ /etc/passwd
5.4、模式符号 (所制定要匹配的字符要用 “//” 圈起来)
显示用户shell为bash
#awk -F ':' '$NF~/bash$/ {print $1,$NF}’ /etc/passwd
5.5、地址定界
line ranges :行范围
#awk -F ':' '(NR >=10 && NR<=20) {print $1}’ /etc/passwd
/PATTERN/,/PATTERN/ :第一个指定的模式匹配开始 ---另一个指定模式匹配结束
#awk -F ':' '/^root/,/^myuser/ {print $1}’ /etc/passwd
注:不支持直接给出数字的格式
5.6、BEGIN/END模式 即表头/表尾
BEGIN{program} :{}里面为代码段 仅在开始处理文件中每一行文本之前,仅执行一次;(表头)

END{program} 仅在文本处理完成后,命令结束前仅执行一次; (表尾)

awk -F ":" 'BEGIN{print "username uid \n================"}{print $1,$3}' /etc/passwd
awk -F ":" '{print "username uid \n================" ;print $1,$3}' /etc/passwd #每一行都会显示

5.7、! 取反
六、ACTION


6.1 if-else
使用场景:对awk取得的整行或某个字段做条件判断
语法:
{if (condition) {true-statement}} 或 if (condition) true-statement
{ if (condition) {true-statement} else {false-statement} }
e.g
id号大于1000为普通用户 # awk -F ':' '{if ($3>500){print $1,$3}}' /etc/passwd # awk -F ':' '{if ($3>500){printf "%15s %-d\n",$1,$3}}' /etc/passwd
awk -F: '{if($3>1000){printf "Common user:%s\n",$1} else {printf "Root or System:%s\n",$1}}' /etc/passwd
最后一个字段的行/bin/bash结尾 # awk -F ':' '{if ($NF == "/bin/bash"){print $1,$3}}' /etc/passwd # awk -F ':' '{if ($NF ~ /\<bash$/){print $NF}}' /etc/passwd
每行字段数大于5个,显示行,否则不显示 # awk -F ':' '{if (NF>5){print $0}}' /etc/passwd
显示文件系统使用结果>80则显示
df -h|awk -F "%" '/^\/dev/{print $1}'|awk '{if($NF>20){print $1}}' 条件过滤
# df -hP | awk -v FS="%" '!/^File/{print $1}' | awk '{if ($NF>80){print $1}}'
6.2、while
使用场景:对一行内的多个字段逐一处理时使用;对数组中各元素逐一处理时使用
while (condition) {true-statement} (condition) 判断条件 {true-statement} 条件为真时,执行循环体 length(arg1,arg2,...) 显示字段的长度
a)对整个一行中的各字段,显示各字段内容和字段中包含的字段的个数
思路: awk '{print length($i)}' FILE
i表示每个字段即可
#awk '/^[[:space:]]*linux16/{i=1;while(i<NF) {print $i,length($i);i++ }}' /tmp/grub2.cfg linux16 7 /boot/vmlinuz-3.10.0-957.27.2.el7.x86_64 40 root=UUID=eb448abb-3012-4d8d-bcde-94434d586a31 46 ro 2 crashkernel=auto 16 net.ifnames=0 13 idle=halt 9
b)循环嵌套if条件判断
对整个一行中的各字段,字段大于等于7才显示字段内容和字段中包含的字段的个数
#awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {if(length($i)>=7) {print $i,length($i)};i++}}' ./grub2.cfg linux16 7
6.3、do-while循环
do {true-statement} while (condition) 意义:至少执行一次循环体
# awk '{i=1;do {print $i,length($i);i++} while (i<=NF)}' /etc/issue
6.4 for 循环
for (控制变量初始化;控制变量条件表达式;控制变量的修正表达式) {statement} for (variable assignment;condition;iteration process) {for-body}
#awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}' ./grub2.cfg
linux16 7
#awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {if(length($i)>=16) print $i,length($i)}}' ./grub2.cfg
/boot/vmlinuz-3.10.0-957.27.2.el7.x86_64 40
注:循环体中嵌套单分支if语句 ,单分支if的statement的{} 可省略
特殊用法:能够遍历数组中的元素
语法:for(var in array) {for-body}
6.5、switch语句 多分支if
字符串比较使用(awk 不常用)
switch (expression) (case VALUE1 or /REGEXP1/:statement;case VALUE2 or /REGEXP2/:statement;...; default:statemet) 表达式 == value1 或 表达式 ~ /REGEXP1
default:statemet ==相当于bash语句case中 最后*)statemet;
6.6 break [n] 或 continue---提前结束本轮循环直接进入下一个循环(无非处理的时下一个字段而已)
显示奇数字段 # awk -F ':' '{i=1;while (i<=NF){if (i%2==0) {i++;continue} else {print i,$i;i++}}}' /etc/passwd
6.7 next(控制awk内生循环)-----提前结束对本行的处理直接进入下一行
显示以/bin/bash结尾的行,非/bin/bash结尾的行next # awk -F ':' '{if ($NF != "/bin/bash"){next} else {print $0}}' /etc/passwd
显示用户id号为偶数的用户
# awk -F ':' '{if ($3%2 != 0){next} else {print $0}}' /etc/passwd
6.8 、array数组
关联数组:array_name[index-expression] index-expression(索引表达式) 可使用任意字符串:字符串要使用双引号 如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空串” 内部的字符串,必须要用到双引号,变量不能使用'"" 若要判断数组中是否存在某元素,要使用“index in array”格式进行 赋值 weekdays["mon"]="Monday" 显示 print weekdays["mon"]
e.g 显示第一个元素
# awk 'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Thuseday";print weekdays["mon"]}'遍历数组每个元素要使用for循环
语法:for (var in array) {statement} var会遍历数组array[Index]的每个索引(下标index) var会逐一被赋值,为array的每一个Index
# awk 'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Thuseday";for(i in weekdays) {print weekdays[i]}}'
场景:当多类数值,统计每一类数值各自出现多少次
netstat -ant | awk '/^tcp\>/' # ^ 行开头; \> 单词结尾
1)查看所有状态 netstat -tan | awk '{print $NF}' 2)# netstat -tan | awk '/^tcp\>/'{state[$NF]++} END{for (i in state){print i,state[i]}}'
统计日志 1)查看httpd是否被安装 rpm -q httpd 2) 启动httpd service httpd start 3)httpd自带压力测试工具,ab ab -c 100 -n 1000 4)统计日志IP # awk '{count[$1]++}END{for (i in count){print i,count[i]}}' /var/log/httpd/access_log
统计/etc/fstab文件中每个单词出现的次数(行内字段遍历) # awk '{i=1;while (i<=NF){count[$i]++;i++}}END{for (i in count){print i,count[i]}}' /etc/fstab # awk '{for(i=1;i<=NF;i++){count[$i]++}}END{for (i in count){print i,count[i]}}' /etc/fstab
统计/etc/fstab文件中每个文件系统类型出现的次数 # awk '{print $3}' /etc/fstab # awk '/^UUID/{fs[$3]++}END{for (i in fs){print i,fs[i]}}' /etc/fstab
6.9、函数(了解)
a)、内置函数
1)、数值处理:
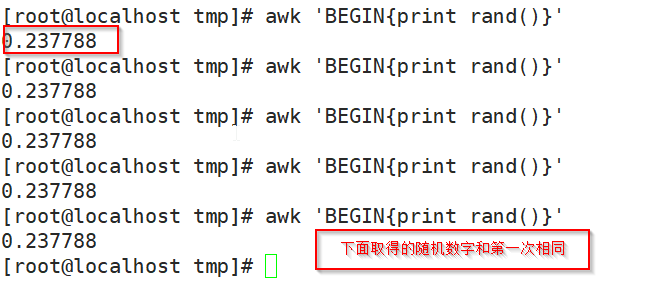
rand():返回0和1之间的一个随机数
#awk 'BEGIN{print rand()}'
注:awk命令取随机时只要取得一次后,以后这个随机数字永远为第一次取得的随机数值
2)、字符串处理:
length([s]) :返回指定字符串的长度
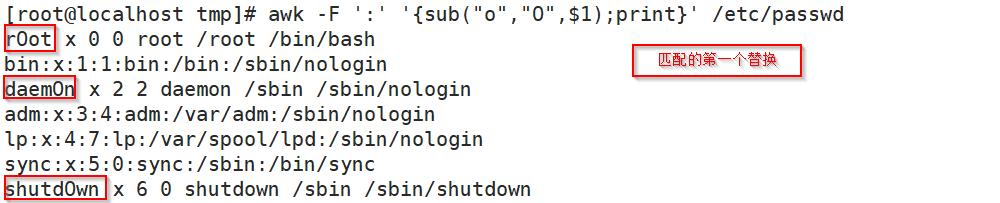
sub(r,s,[t]):[t] 可选参数
以r表示的模式,来查找t所表示的字符中的匹配的内容,并将其第一次出现替换为s所表示的内容
# awk -F ':' '{sub("o","O",$1);print}' /etc/passwd
gsub(r,s,[t]):[t] 可选参数
以r表示的模式,来查找t所表示的字符中的匹配的内容,并将其所有匹配到的内容替换为s所表示的内容
split(s,a[,r])
以r分割符切割字符串s,将切割后的结果保存至a所表示的数组中
统计每一个ip建立ip的个数
# netstat -tan|awk '/^tcp\>/{split($5,ip,":");print ip[1]}'
0.0.0.0
0.0.0.0
116.77.75.251
100.100.30.26
# netstat -tan|awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++}END{for (i in count){print i,count[i]}}'
116.77.75.251 1
0.0.0.0 2
100.100.30.26 1
统计每一个ip建立ip的个数 # netstat -tnl | awk '!/^Proto/ && !/^Active/{split($5,state,":");ip[state[1]]++}END{for (i in ip){print i,ip[i]}}'

