


四、IO重定向和管道以及基本文本处理工具
一、三种IO设备
程序:数据+指令 或 数据结构+算法
程序必须能够读入输入然后经过加工来产生结果,其接受的输入可以是变量、数组、列表、文件等等,生产出来的结果可以使变量、数组、列表、文件等等。即:
程序都有读入数据和输出数据的需求
读入数据:input
输出数据:output
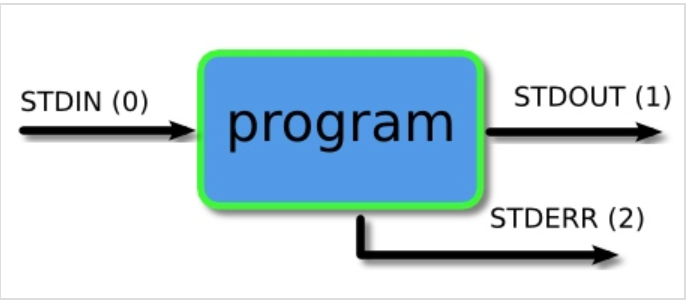
一、标准文件描述符
linux系统将每个对象当作文件处理,这包括输入和输出进程。linux用文件描述符(file descriptor)来标识每个文件对象。文件描述符是一个非负整数,可以唯一标识会话中打开的文件。每个进程一次最多可以有九个文件描述符。出于特殊目的,bash shell保留了前三个文件描述符(0,1和2)
Linux给程序提供三种IO设备:
- 标准输入(STDIN)-0 默认接受来自键盘的输入
- 标准输出(STDOUT)-1 默认输出到终端窗口
- 标准错误(STDERR)-2 默认输出到终端窗口
在Linux中,一切皆文件,我们每打开文件,系统都会自动分配一个FD(file description,文件描述符)。上面的0,1,2就是系统分配的文件描述符。
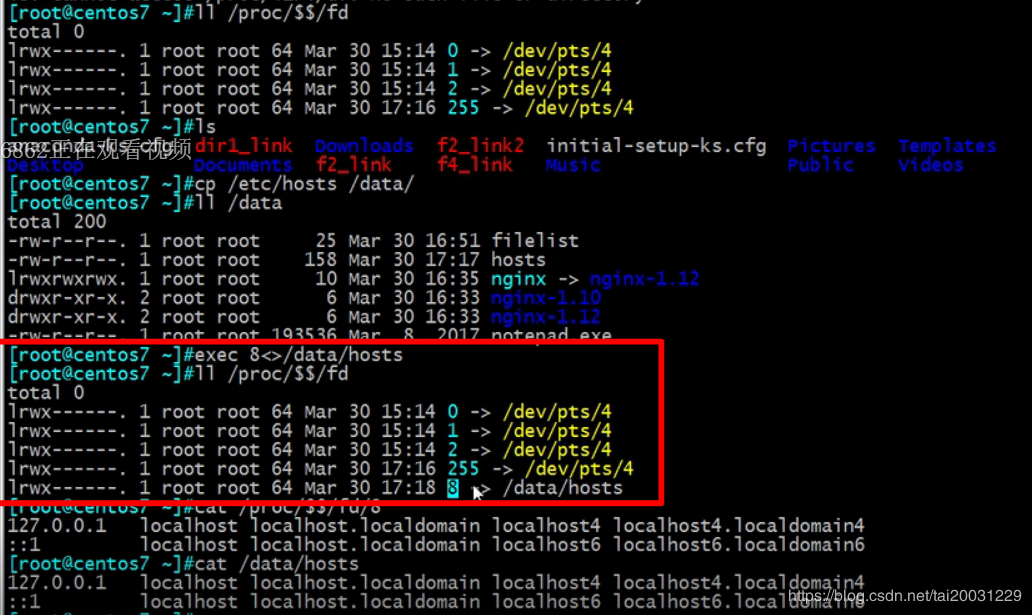
1 ll /proc/$$/fd 查看目前的文件描述符 2 exec 8<>/data/hosts 3 表示给/data/hosts文件指定一个文件描述符8,且8与/data/hosts之间是软链接 4 exec 8>&- 删除8号这个文件描述符
二、IO重定向:改变默认位置
1、>标准的输出重定向:
ls > /dev/pts/5 命令ls重定向输出至窗口5
ls > /data/ls.out 命令ls重定向输出至/data/ls.out文件中
注意:假如ls.out文件中本来就有内容,那么重定向输出后会覆盖文件中原有的内容
2、>>:追加重定向,新内容会追加至目标文件尾部
ls >> /data/ls.out
3、():合并多个程序的STDOUT
(cal 2007;cal 2008) > all.txt
4、2>标准错误的输出重定向:
cmd 2> /data/err.log cmd(本身无cmd这个命令,所以输入此命令会显示错误的结果)的错误结果重新定向显示至 data/err.log 中
注意:history 2> /data/err.log 由于本身history命令是正确的,所以默认的输出设备会正常显示history命令的内容,且不会输出至/data/err.log中。原data/err.log中的文件会被空文件覆盖。
cmd 2>> /data/err.log 这样就会将正确的信息显示在默认的输出设备上,而且每次的错误信息输入至err.log文件中,方便后面研究问题
对于输出既有正确信息又有错误信息的场景:
1 ls /err /data >f1 2>f2 则正确信息输出至f1 中,错误信息输出至f2 中 2 ls /err /data &>all.log 正确信息和错误信息都输出至all.log文件中。 3 或 4 ls /err /data >all.log 2>&1 #把错的当成对的 5 ls /err /data 2>all.log >&2 注意次序!!
- 注意区分以下几项,哪个与众不同:
1 cmd > log 2>&1 2 cmd 2>&1 >log 此项与众不同 3 cmd &> log 4 cmd 2>log >&2
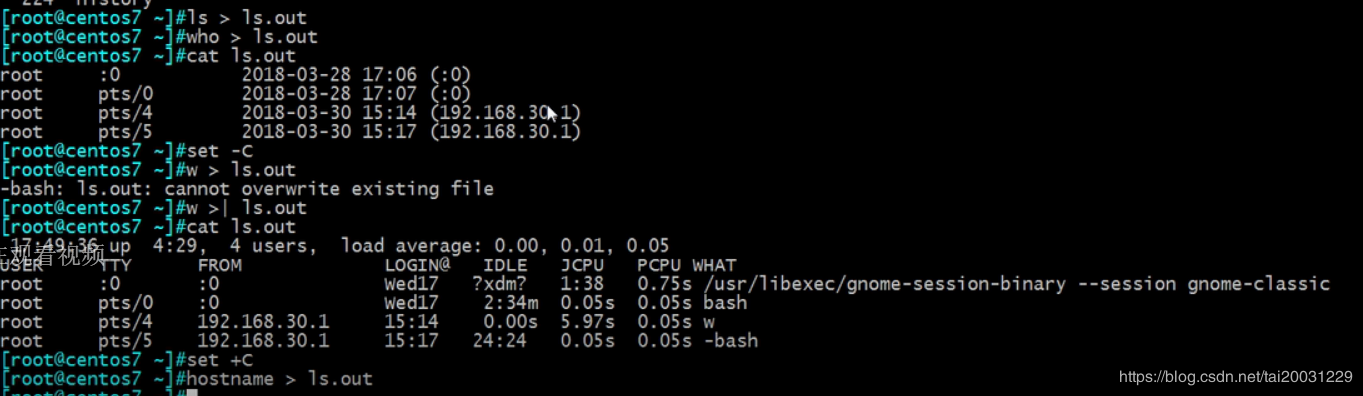
set –C 禁止将内容覆盖已有文件,但可追加
>| file 强制覆盖
set +C 允许覆盖
TIPS:
小技巧:> bigfile效果是创建了一个bigfile的空文件。背后的原理是利用重定向标准输出的原理,重定向输出至bigfile文件,由于无任何输出结果,所以直接效果就是创建了一个空的bigfile文件。所以一个比较安全的创建空文件的方法是:\>> file .
原因:1. 假如file文件原来就存在,那么>> 不会覆盖原来的文件,只会在原文件基础上累加。
2.>> 不会刷新时间,touch命令会刷新时间
*** 非常重要: 假如 abc_link -> abc (abc_link软链接abc),
那么我们> abc_link 的话,会直接覆盖源文件abc !!!!
5、 < 标准输入重定向
cat < file file文件内容输入到cat命令上
1 cat < f1 > f2 f2里显示f1 内容的文件 2 cat < f1 > f1 清空f1 文件 3 cat < f1 >>f2 无限循环将f1文件累加至f2文件
二、tr命令(删除和转换字符)
tr [OPTION]... SET1 [SET2]
Translate, squeeze, and/or delete characters from standard input, writing to standard output.
1 tr 'a-z' 'A-Z' #将输入的任意小写字符转换为大写,其他的字符保持原样 2 tr -c,–C --complement:#use the complement of SET1;取字符集的补集; 3 tr -d,--delete: #delete characters in SET1, do not translate;删除所有属于第一字符集的字符 4 tr -s,--squeeze-repeats:#replace each input sequence of a repeated character that is listed in SET1 with a single occurrence of that character;把连续重复的字符以单独一个字符表示 5 tr -t,--truncate-set1:#first truncate SET1 to length of SET2;将第一个字符集对应字符转化为第二字符集
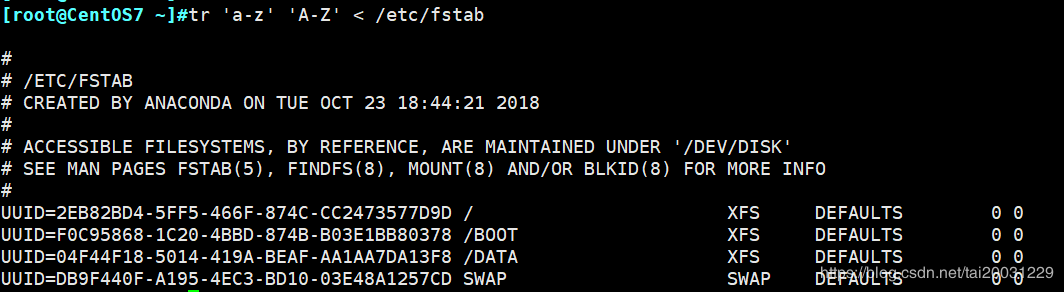
tr 'a-z' 'A-Z' < /etc/fstab :将/etc/fstab这个文件中的小写字符转换为大写字符
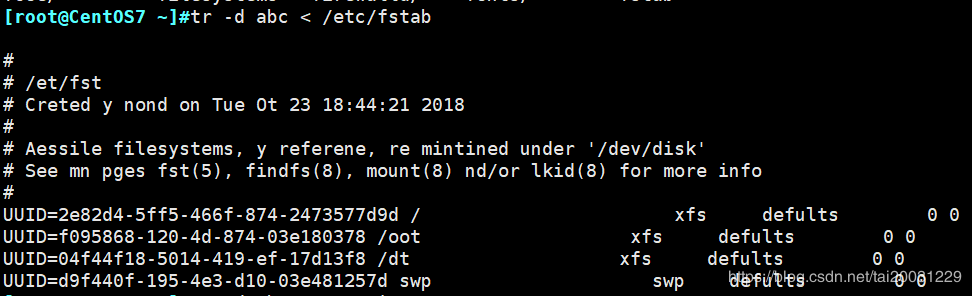
tr –d abc < /etc/fstab 删除/etc/fstab这个文件中的abc字符
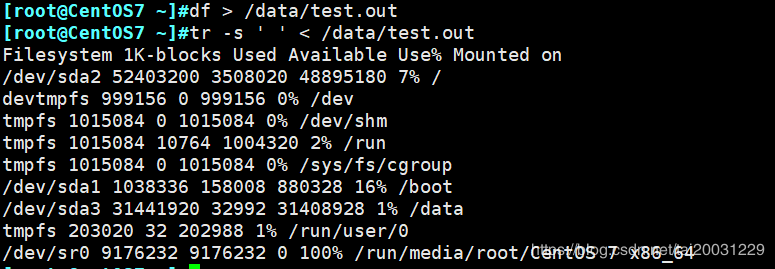
实验1:将df命令显示输出里的连续空格全部以一个空格输出
第一步:df > /data/test.out 将df命令的输出结果定向至/data/test.out文件中。
第二步:tr -s ' ' < /data/test.out 完成
把多行发送给STDIN
使用“<<终止词”命令从键盘把多行重导向给STDIN
1 mail -s "PleaseCall" admin@magedu.com << END 2 3 >HiWang, 4 > 5 >Pleasegivemeacallwhenyougetin.Wemayneed 6 >todosomemaintenanceonserver1. 7 > 8 >Detailswhenyou’reon-site 9 >Zhang 10 >END 11 用END终止多行输入,并将内容以邮件方式发送给admin@magedu.com,邮件主题为PleaseCall
三、管道
less :一页一页地查看输入 ls -l /etc | less mail :通过电子邮件发送输入 echo "test email" | mail -s "test" user @example.com lpr:把输入发送给打印机 echo "test print" | lpr -p printer_name
管道(使用符号“|”表示)用来连接命令
命令1 | 命令2 | 命令3 | …
- 将命令1的STDOUT发送给命令2的STDIN,命令2的STDOUT发送到命令3的STDIN
- STDERR默认不能通过管道转发,可利用2>&1 或|& 实现
1 ls /data /err 2>&1 | tr 'a-z' 'A-Z' 2 ls /data /err |& tr 'a-z' 'A-Z'
实验1: 随机产生的16位字符串,将其中的小写字符换成大写字符,并且删除无用的字符。
第一步:
openssl rand -base64 16 > /data/test.out 随机产生16位的字符串。并将其定向输出至文件中。
第二步:
tr -dc '[:alpha:]' < /data/test.out | tr 'a-z' 'A-Z' 删除非字母的字符并将小写转换为大写
实验2: 计算1+2+3+4+…+100 =
echo {1..100} | tr ' ' '+' | bc
seq -s + 1 100 | bc
管道中"-"符号
示例:
将/home 里面的文件打包,但打包的数据不是记录到文件,而是传送到stdout,经过管道后,将tar -cvf-/home 传送给后面的tar -xvf-, 后面的这个-则是取前一个命令的stdout,因此,就不需要使用临时file了
tar -cvf-/home | tar -xvf-
四、tee,重定向到多个目标
tee - read from standard input and write to standard output and files
tee [OPTION]... [FILE]...
命令1 | tee [-a ] 文件名| 命令2
把命令1的STDOUT保存在文件中,同时做为命令2的输入,
1 tee -a, --append #append to the given FILEs, do not overwrite,追加输出至文件中
使用场景:
- 保存不同阶段的输出
- 复杂管道的故障排除
- 同时查看和记录输出
五、几个文本查看工具:wc, cut, sort, uniq, diff, patch
1.wc:word count
wc - print newline, word, and byte counts for each file
wc [OPTION]... [FILE]... ~]# wc anaconda-ks.cfg 66 167 1858 anaconda-ks.cfg # 66:表示行数 # 167:表示字数 # 1858:字节数 # option -l:只计数行数 -w:只计算单词总数 -c:只计数字节总数 -m:只计数字符总数
2.cut:remove sections from each line of files
cut OPTION... [FILE]... # option: -d --delimiter=DELIM : 指明分隔符,默认tab -f --fields=LIST : # :指定第#个字段 #-#:指定第#-#个字段;如3-5,第3-5个字段 #,#:指定离散的多个字段;如3,5,7 #,#-#:
3.sort:sort lines of text files
把整理过的文本显示在STDOUT,不改变原始文件
sort [OPTION]... [FILE]... # option: -n:基于数值大小而非字符进行排序; -r:逆序排序; -f:忽略字符大小写 -t CHAR:指定分隔符; (类似cut的-d命令) -k #:用于排序比较的字段;(类似cut -f 命令) -u:连续且相同的重复的行只保留一行;
4.uniq:report or omit repeated lines
报告或移除重复的行
uniq [OPTION]... [INPUT [OUTPUT]] # option -c:显示每行的重复次数; -u:仅显示未曾重复过的行; -d:仅显示重复过的的行; # 常和sort一起使用: sort userlist.txt | uniq-c
5.diff、patch
diff - compare files line by line
patch - apply changes to files
diff [OPTION]... FILES diff /PATH/TO/OLDFILE /PATH/TO/NEWFILE > /PATH/TO/PATCH_FILE -u:使用unfied机制,即显示要修改的行的上下文,默认为3行,适用于补丁文件; ### patch:复制在其它文件中进行的改变(要谨慎使用),即向文件打补丁; patch [OPTIONS] -i /PATH/TO/PATCH_FILE /PATH/TO/OLDFILE patch /PATH/TO/OLDFILE < /PATH/TO/PATCH_FILE -b:自动备份改变了的文件
6.cat、tac、rev
cat - concatenate files and print on the standard output cat [OPTION]... [FILE]... # option: -E: 显示行结束符$ -n: 对显示出的每一行进行编号 -A:显示所有控制符 -s:压缩连续的空行成一行 ### tac - concatenate and print files in reverse (反向显示cat的输出结果) tac [OPTION]... [FILE]... ### rev - reverse lines of a file or files rev [options] [file ...]
7.more、less
分页查看文件内容
8.head、tail
head - output the first part of files 默认显示前10行
tail - output the last part of files 默认显示后10行
head [OPTION]... [FILE]... # option: -n #: 指定获取前#行 -c #: 指定获取前#字节 -#:指定行数 ### tail [OPTION]... [FILE]... # option: -n #: 指定获取后#行 -c #: 指定获取后#字节 -#:指定行数 -f: 跟踪显示文件fd新追加的内容,常用日志监控;相当于--follow=descriptor -F: 跟踪文件名,相当于—follow=name --retry
要获取/etc/passwd文件, 要获取其第6-10行,并显示每行的行号
# 1). -n显示行号,tail -n +6显示第6行之后的行,结合head -n 5,获取前面5行,刚好6-10 $ cat -n /etc/passwd | tail -n +6 | head -n 5 # 2). 先用head -n 10来获取前10行,再结合tail -n 5获取后面5行,刚好也是6-10行 $ cat -n /etc/passwd | head -n 10 | tail -n 5 |sort -n -k3 |cut -d: -f1 # 3). cat -n来显示行号,再用awk中$1来判断行号范围 $ cat -n /etc/passwd | awk '($1 > 1 && $1 < 11){print $0}' # 4). 借助于6,10p来打印第6行到第10行 $ cat -n /etc/passwd | sed -n '6,10p' # 5). =打印行号,使用N;来获取下一行,再用\t来替换换行符,最后使用6,10p来获取 $ sed = /etc/passwd | sed 'N;s/\n/\t/' | sed -n '6,10p'
六、练习
1、将/etc/issue文件中的内容转换为大写后保存至/tmp/issue.out文件中
tr 'a-z' 'A-Z' < /etc/issue | tee -a /data/issue.out
2、将当前系统登录用户的信息转换为大写后保存至/tmp/who.out文件中
who | tr 'a-z' 'A-Z' > /data/who.out
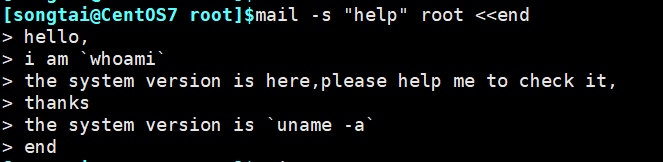
3、一个linux用户给root发邮件,要求邮件标题为”help”,邮件正文如下:
Hello, I am 用户名,The system version is here,pleasehelp me to check it ,thanks!
操作系统版本信息
4、将/root/下文件列表,显示成一行,并文件名之间用空格隔开
ls /root | tr '\n' ' '
5、计算1+2+3+…+99+100的总和
echo {1..100} | tr ' ' '+' | bc
6、处理字符串“xt.,l 1 jr#!$mn2 c*/fe3 uz4”,只保留其中的数字和空格
tr -dc [0-9][:space:]
7、将PATH变量每个目录显示在独立的一行
echo $PATH | tr ':' '\n'
8、将指定文件中0-9分别替代成a-j
tr '0-9' 'a-j' < 文件

