写时复制集合 —— CopyOnWriteArrayList
前言
JUC 下面还有一个系列的类,都是 CopyOnWriteXXX ,意思是写时复制,这个究竟是怎么回事?那就以 CopyOnWriteArrayList 为切入点,一起了解写时复制是怎么回事?
公众号:liuzhihangs,记录工作学习中的技术、开发及源码笔记;时不时分享一些生活中的见闻感悟。欢迎大佬来指导!
介绍
ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。
像名字一样,每次进行操作的时候,都会进行一次复制,当然会有很大的性能消耗,但是在某些使用场景下,又会提高性能。具体是怎么操作的,那就一步一步阅读源码,然后再做总结归纳。
基本使用
public class CopyOnWriteArrayListTest {
public static void main(String[] args) {
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
// 添加元素
list.add("liuzhihang");
// 移除元素
list.remove("liuzhihang");
// 查看元素
String value0 = list.get(0);
// 遍历
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String next = iterator.next();
}
}
}
问题疑问
- 为什么要叫写时复制集合?
- CopyOnWriteArrayList 实现原理是什么?
- CopyOnWriteArrayList 和 ArrayList 有什么区别?
- CopyOnWriteArrayList 复制是怎么进行复制的?
源码分析
基本结构
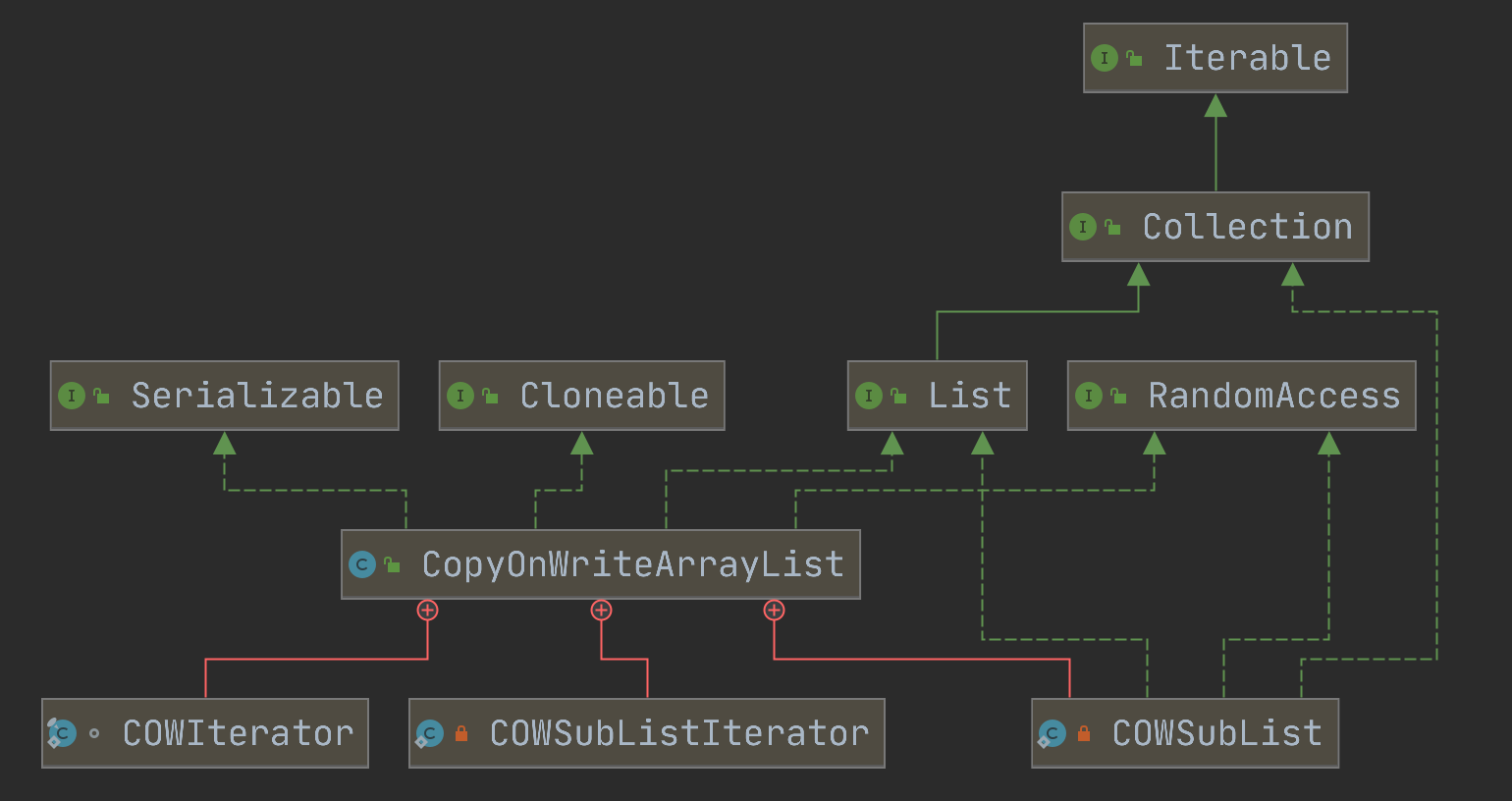
参数介绍
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final long serialVersionUID = 8673264195747942595L;
/** 数据有变动时使用 */
final transient ReentrantLock lock = new ReentrantLock();
/** 数组 只能通过 getArray/setArray 访问 */
private transient volatile Object[] array;
final Object[] getArray() {
return array;
}
// 将数组指向传入的新数组
final void setArray(Object[] a) {
array = a;
}
}
通过参数可以了解到以下内容:
- 基于数组实现;
- 使用了 ReentrantLock 互斥锁。
构造函数
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
在初始化 CopyOnWriteArrayList 时,就是创建了一个 Object 的数组。
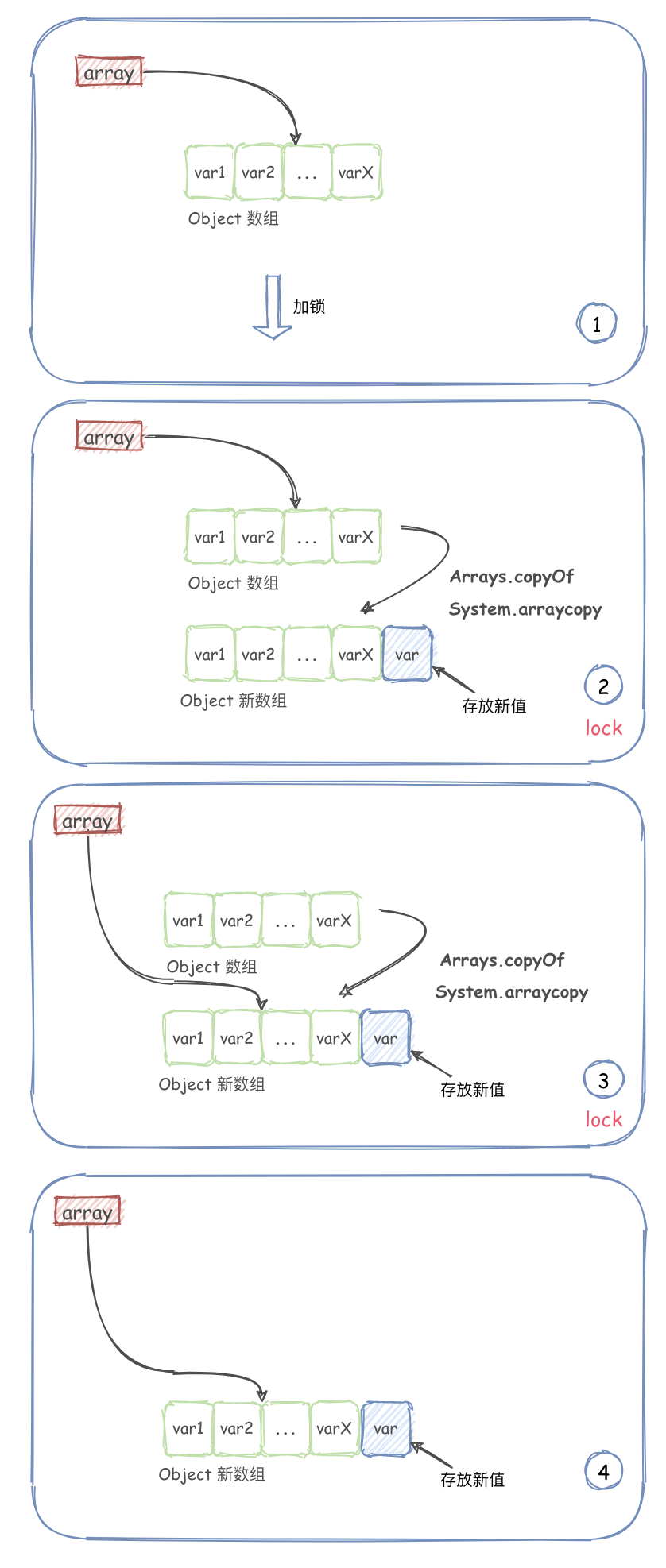
add
public boolean add(E e) {
// 加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 获取当前数组
Object[] elements = getArray();
int len = elements.length;
// 创建一个新数组,并将原数组数据复制到新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 添加的新元素到数组尾部
newElements[len] = e;
// 将数组指向新数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
add 方法逻辑很简单:
- 通过加互斥锁(ReentrantLock)从而保证在写的时候只有一个线程可以写。
- 新增元素时,先使用
Arrays.copyOf(elements, len + 1)复制出一个长度 +1 的新数组。 - 添加元素到新数组。
- 然后再将原数组对象指向新数组。
画图如下:
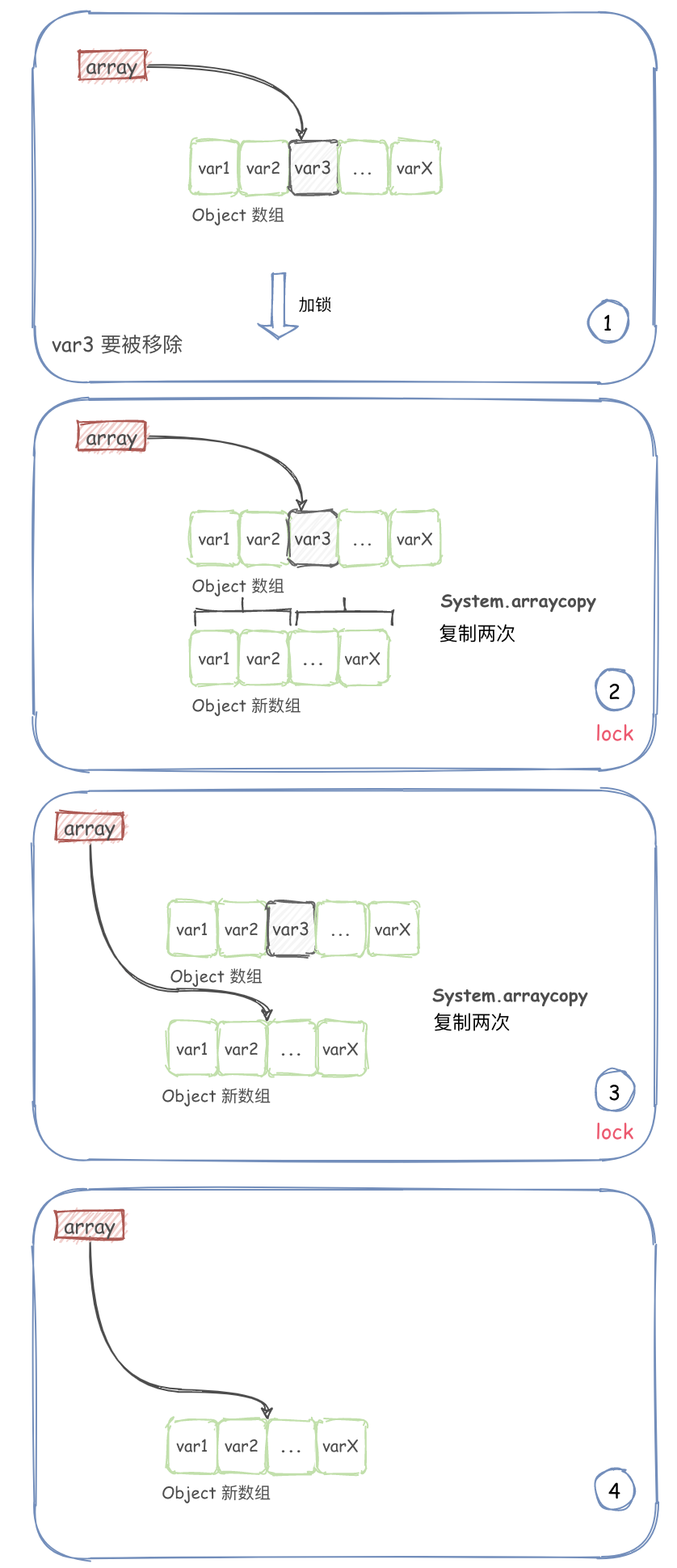
remove
public E remove(int index) {
// 加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 原数组
Object[] elements = getArray();
int len = elements.length;
// 移除的值
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
// 如果移除最后一个元素
// 直接复制前面的元素即可
setArray(Arrays.copyOf(elements, len - 1));
else {
// 移除中间的元素,进行两次复制
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();
}
}
remove 方法相对多了一些判断:
- 通过加互斥锁(ReentrantLock)从而保证在写的时候只有一个线程可以移除元素。
- 如果移除的是最后一个元素,则直接复制前面的元素到新数组,并指向新数组即可。
- 如果移除的是中间的元素,则需要进行两次复制,然后指向新数组。
画图如下:
get
public E get(int index) {
return get(getArray(), index);
}
get 方法可以看出:
- 获取元素并没有进行加锁。
- 从原数组获取的元素。
所以并发情况下,并不能保证很及时的读取的刚插入或者移除的元素。
数组复制
通过阅读 add 和 remove 相关代码,可以看到在数组复制时使用了 Arrays.copyOf 和 System.arraycopy,这相当于一个优化方面吧。
毕竟数组复制总不能把原数组遍历一遍,挨着赋值到新数组里面吧。
那接下来看一下内部是如何实现的:
public class Arrays {
// 其他方法省略 ...
/**
* original 要复制的数组
* newLength 新数组的长度
*/
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
/**
* original 要复制的数组
* newLength 新数组的长度
*/
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
// 创建一个新数组,长度是指定的长度
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
// 创建具有指定的组件类型和长度的新数组
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
// 调用 System.arraycopy 复制数组
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
}
通过阅读 Arrays.copyOf 相关源码,发现其实 Arrays.copyOf 底层也是调用的 System.arraycopy
public final class System {
// 其他方法省略 ...
/**
* src 源数组
* srcPos 源数组起始位置
* dest 目标数组
* destPos 目标数组的起始位置
* length 要复制的元素数量
*/
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
}
可以看到 System.arraycopy 是一个 native 方法,这个是 JVM 内部实现的,具体可以阅读相关资料。而使用这种方式要比 for 循环和 clone 要高效很多。
总结
Q&A
Q: 为什么要叫写时复制集合?
A: 因为在 add、remove 操作时会复制出来一个新数组。
Q: CopyOnWriteArrayList 实现原理是什么?
A: 在 add、remove 操作时会进行加锁,然后复制出来一个新数组,操作的都是新数组,而此时原数组是可以提供查询的。当操作结束之后,会将对象指针指向新数组。
Q: CopyOnWriteArrayList 和 ArrayList 有什么区别?
A: CopyOnWriteArrayList 在读多写少的场景下可以提高效率,而 ArrayList 只是普通数组集合,并不适用于并发场景,而如果对 ArrayList 加锁,则会影响一部分性能。
同样对 CopyOnWriteArrayList 而言,仅能保证最终一致性。因为刚写入的数据,是写到的复制的数组中,此时并不能立即查询到。如果要保证实时性可以尝试使用 Collections.synchronizedList 或者加锁等方式。
Q: CopyOnWriteArrayList 复制是怎么进行复制的?
A: 内部使用的是本地方法 System.arraycopy 进行数组的复制。
结束语
通过阅读 CopyOnWriteArrayList 源码,了解到写时复制是的原理。同时了解到可以使用 System.arraycopy 的方式提高数组复制的效率。
同样 CopyOnWriteArrayList 适合读多写少的场景,满足最终一致性,但是并不能保证数据修改及时查询到。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号