使用 awk 命令统计文本
2022-04-19 11:25:15.008,b4d13bfca8fe4b93a85e65a88520d945,LogScheduler#printLog,10ms,Y,xxxxxxxx
2022-04-19 12:01:15.002,4d10d093dce8491c8ae3c1bff6dbd7c5,LogScheduler#printLog,999ms,N,xxxxxxxx
2022-04-19 12:12:16.003,d9d1f4b121764edb8cb260417cd75229,LogScheduler#printLog,5ms,Y,xxxxxxxx
2022-04-19 12:15:22.004,e3e10340e51c49ce9d688541ba799283,LogScheduler#printLog,1001ms,N,xxxxxxxx
2022-04-19 12:55:59.005,209d2f1407894da5aa0f44de621515c7,LogScheduler#printLog,1020ms,Y,xxxxxxxx
2022-04-19 13:25:15.006,e09f75c6d0d849068ae713820c94f3f9,LogScheduler#printLog,15ms,Y,xxxxxxxx
2022-04-19 13:25:15.008,b4d13bfca8fe4b93a85e65a885231231,LogScheduler#printLog,99ms,Y,xxxxxxxx
有那么一段日志,需要统计出来以下信息:
- 输出耗时超过 1000ms 并且结果是 Y 的整行
- 12:00 ~ 13:00 之间成功的行数,成功率
日志格式:时间,traceId,类方法名,耗时,结果,内容
看到这里,如果小伙伴已经有思路了,那就没必要往下面看了,直接拉到最后,点赞、在看。
这里要使用的就是 awk 命令。
常用内置变量
awk 的主要功能就是对文本进行统计报告,具体介绍可以看菜鸟笔记,下面仅介绍几个常用的内置变量。
- FS:行字段分隔符,默认是空格,可以使用
-F指定分隔符 - $0、$1……:行字段分隔符分割后获取指定部分,$0 是获取整行记录
- NF:当前行的字段数量
- RS:行记录分隔符
- NR:行号
大概常用的就这几个,下面看一下实际使用效果
效果展示#
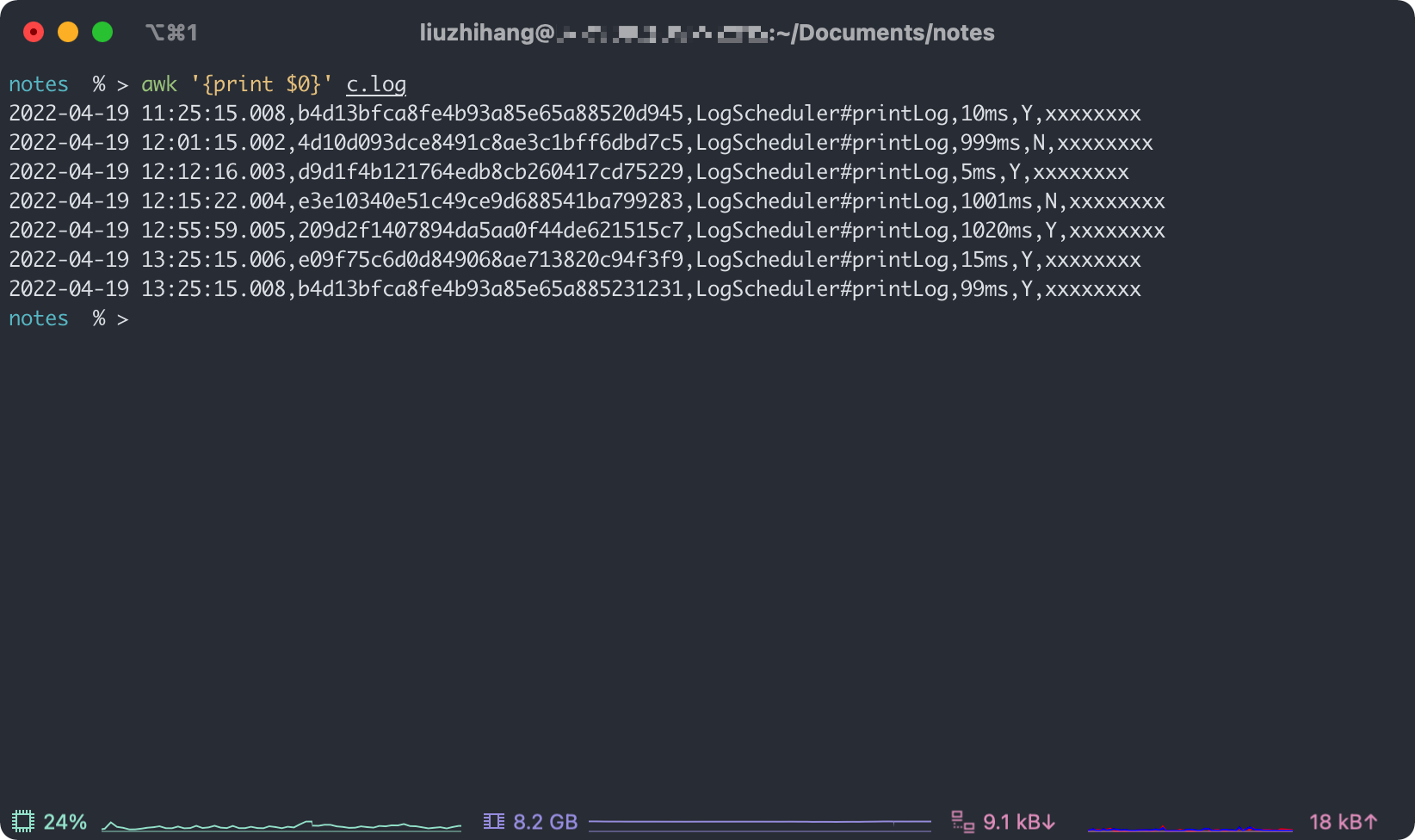
notes % > awk '{print $0}' c.log
因为 $0 就代表整行记录,所以输出结果如下。
那 $1 的结果呢?
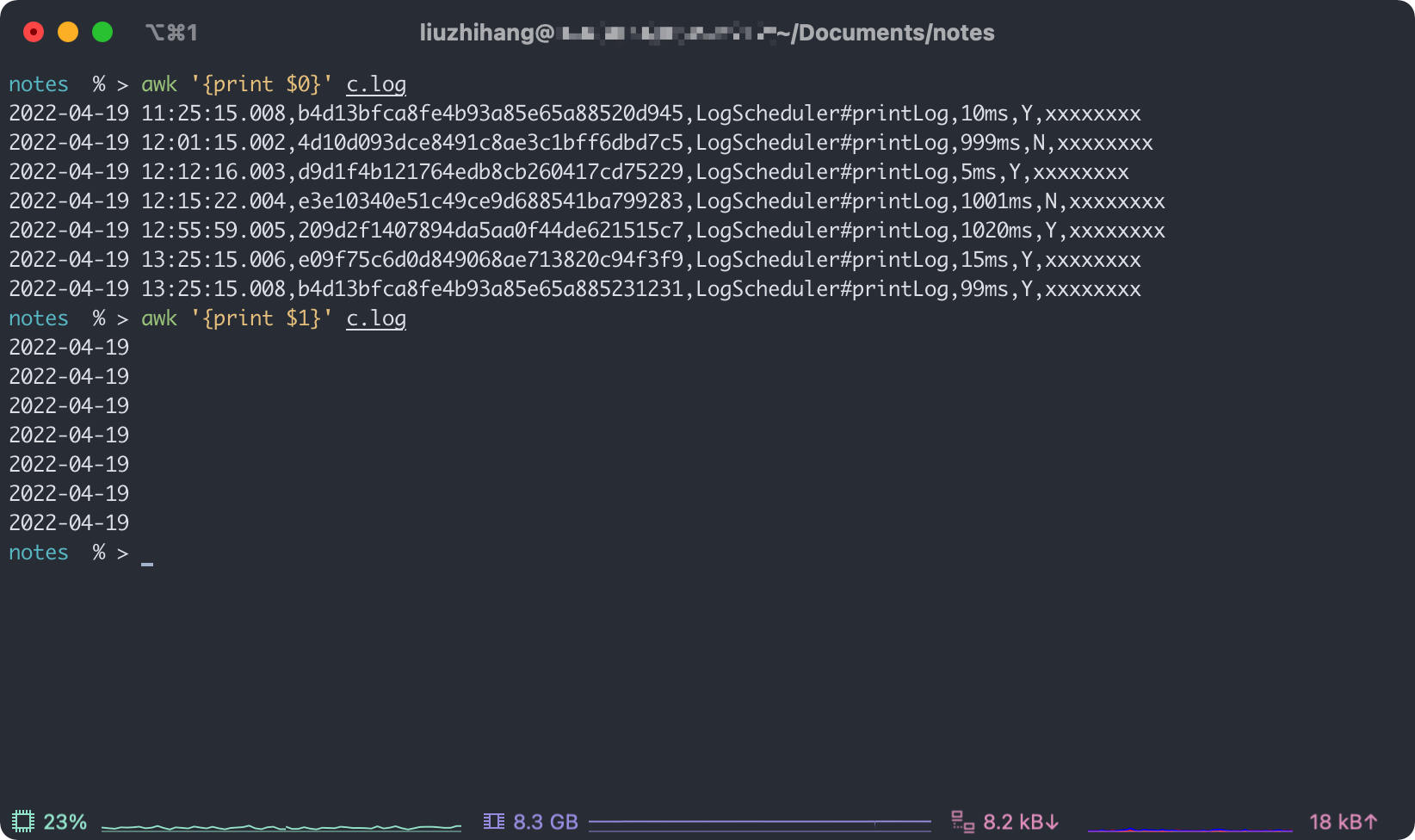
因为默认是空格作为分隔符,所以输出的结果就只有日期了。
指定分隔符为,之后,看一下输出结果:
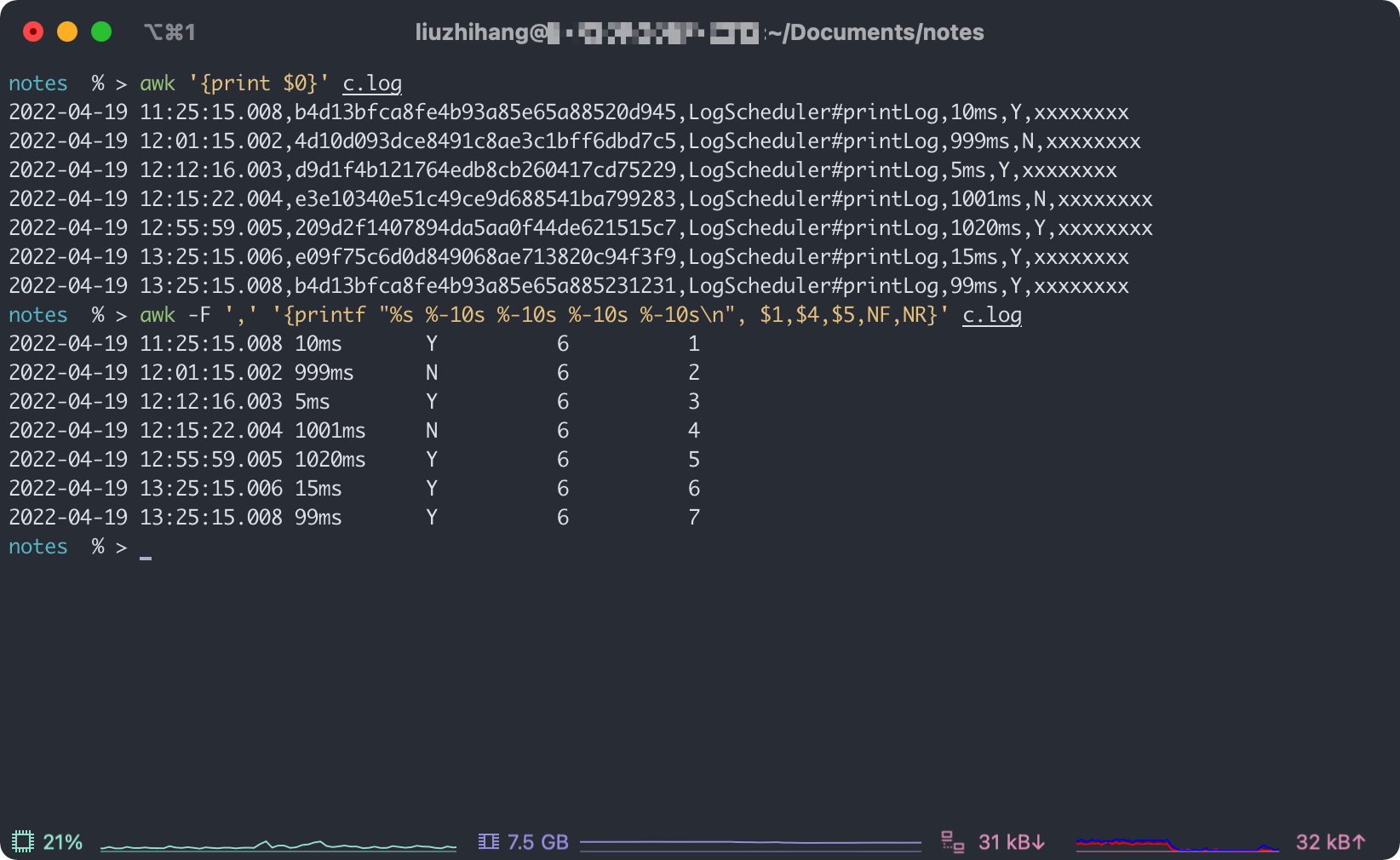
题目答案
基本上熟悉了怎么使用剩下的就比较好办了。
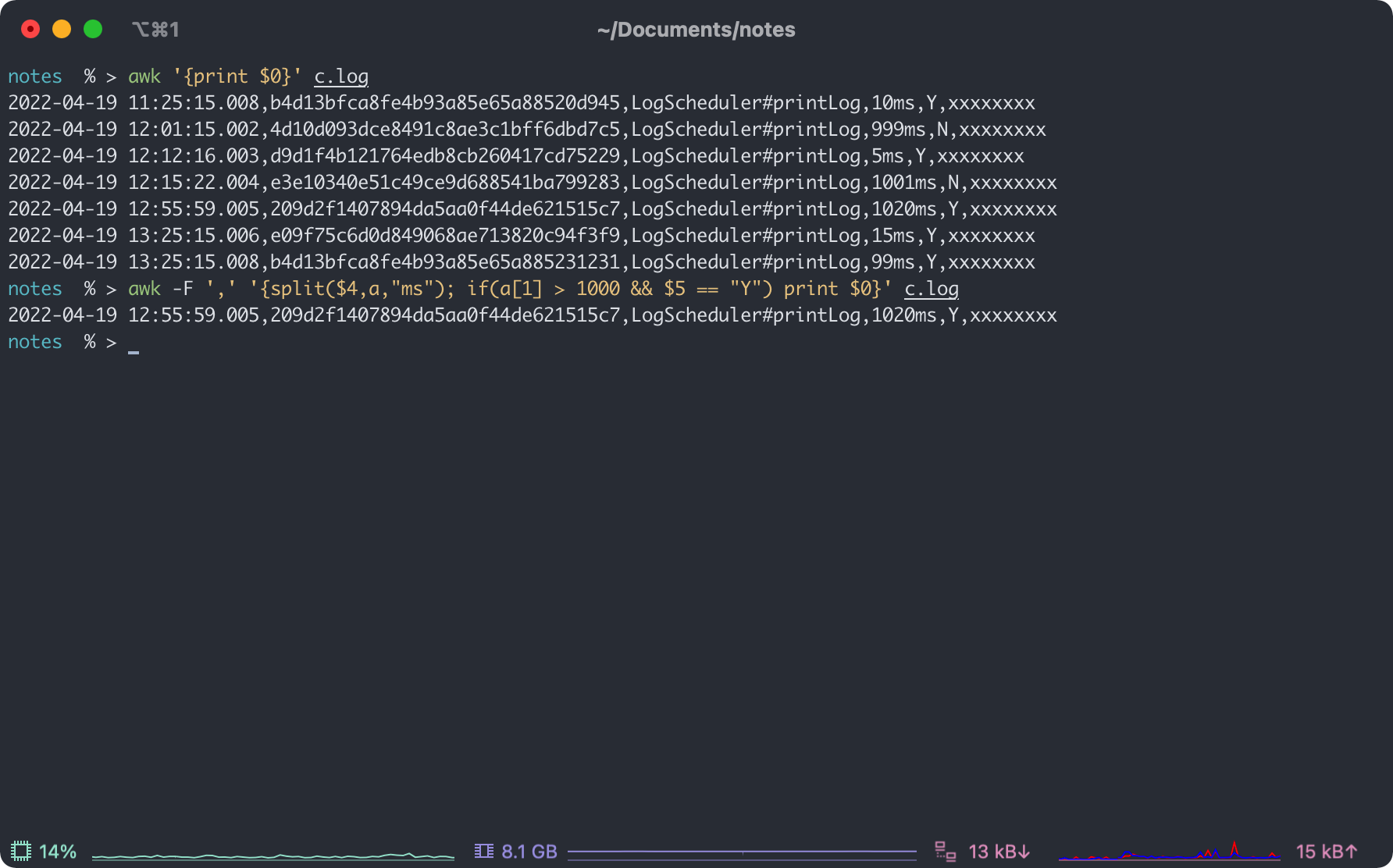
- 耗时超过 1000ms 且 Y 的行
notes % > awk -F ',' '{split($4,a,"ms"); if(a[1] > 1000 && $5 == "Y") print $0}' c.log
- 12:00 ~ 13:00 之间成功的行数,成功率
awk -F ',' 'BEGIN{count=0;sum=0}{if($1>="2022-04-19 12:00:00.000" && $1<"2022-04-19 13:00:00.000"){sum+=1;if($5 == "Y")count+=1}}END{print NR,count,sum,count/sum}' c.log
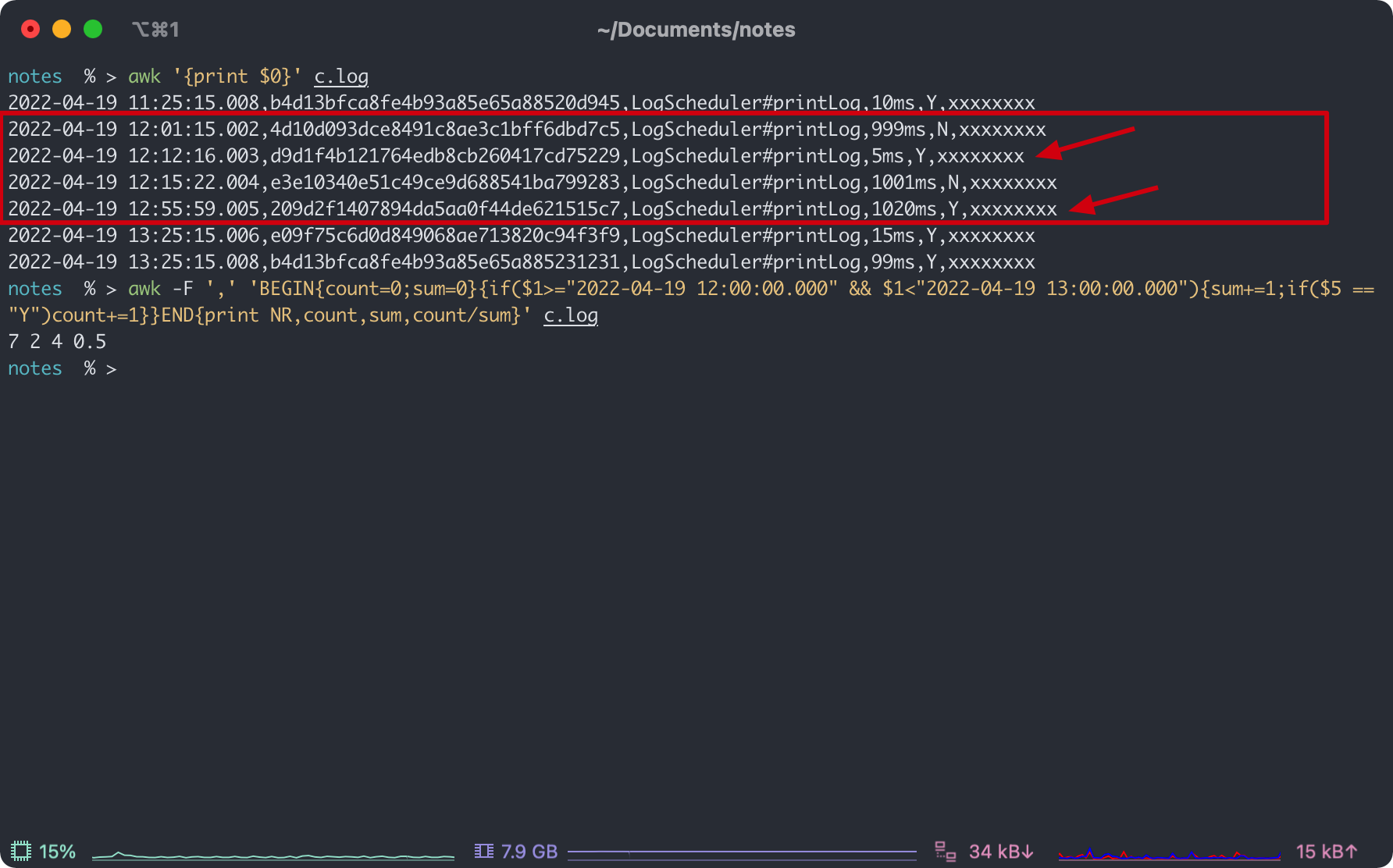
总记录 7 条, 12:00 ~ 13:00 之间成功的行数是 2,成功率 0.5。
总结
上面只是在工作中可能会遇到的一个场景,所以记录下来,如果小伙伴有更合适的方式来统计计算,欢迎留言。
作者:程序员小航
出处:https://www.cnblogs.com/liuzhihang/p/16306959.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
欢迎关注个人公众号:『 程序员小航 』




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2021-05-24 Mac 常用软件推荐 —— Java 开发工程师