深度聚类算法浅谈
目录
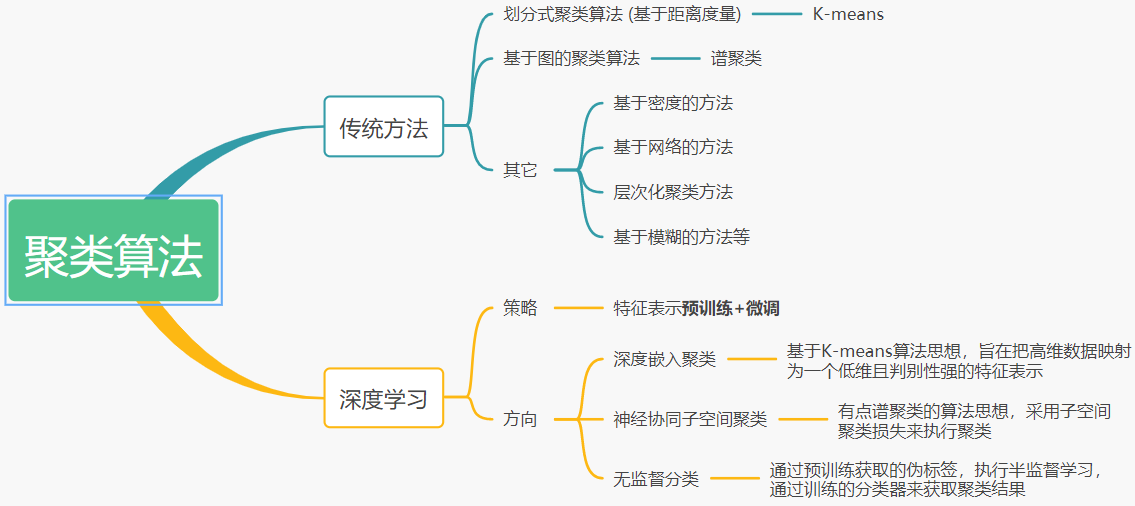
传统的聚类算法可以分为划分式聚类算法(例如K-means),基于图的聚类算法(例如谱聚类),基于层次的聚类算法等[1][2]。
传统的聚类算法应用最广泛的两种算法:K-means聚类和谱聚类。
K-means聚类通过确定簇心,并计算各个数据点到簇心的距离,来划分类别的归属。
谱聚类是最流行的聚类算法之一,它的实现简单,而且效果往往胜过传统的聚类算法,如K-means。它的主要思想是把所有数据看作空间中的点,这些点之间用带权重的边相连,距离较远的点之间的边权重较低,距离较近的点之间边权重较高,通过对所有数据点和边组成的图进行切图,让切图后不同子图间边权重和尽可能低,而子图内边权重和尽可能高来达到聚类的目的[3]。
然而传统的聚类算法对于高维数据集很难达到理想的聚类效果。例如,谱聚类算法对于高维数据集,会需要很高的内存计算消耗,在实际的大数据集聚类中不适用。虽然目前也有相关方法对原始高维数据执行降维,但是相关降维方法只能对线性数据执行降维处理,而不能够对原始高维数据进行非线性关系映射处理。针对该问题,基于深度学习的聚类算法在近些年引发了众多学者的研究兴趣。
深度聚类的核心:可以视为特征表示的预训练+微调。
预训练:采用深度神经网络(例如卷积自动编码器),将原始高维数据,映射为一个低维的特征表示。
微调:通过KL散度损失[4]、K-means损失[5]、子空间损失[6]和交叉熵损失[7]等,对预训练获取的表示进行微调,使之在聚类过程中更加具有判别性。
本文主要记录自己阅读的三篇关于深度聚类的问题,分别是ICML2016, ICML2019, CVPR2021。其中ICML2016算是深度聚类领域的开创性文章,ICML2019则是为了解决谱聚类方向的一个比较有意思的文章,CVPR2021则是当前采用伪标签执行半监督分类的最新聚类文章。
此处推荐一个关于聚类方向记录最新顶会文章和开放源码的GitHub仓库(目前已累计1.1k个Star)
1 深度嵌入聚类(ICML, 2016)
1.1 动机
传统的基于距离(distance functions)和组(grouping algorithms)划分的聚类算法在实际场景中被广泛应用。然而,很少有工作聚焦于采用学习的表示执行聚类。
痛点分析:
1) 直接采用K-means等传统基于距离度量的距离算法,在原始像素高维图像数据集上计算欧式距离不够高效,即当维度很高时,计算非常耗时;
2) 传统的先降维后聚类的算法,只能对原始数据执行线性嵌入学习,导致很多重要特征丢失;
3) 谱聚类算法虽然能够在高维数据集中很好地执行聚类,但是当数据集变大时,其计算特征矩阵时的内存和运算资源会暴增。
1.2 贡献
针对传统聚类算法不能很好地对高维大数据执行聚类,本文提出了一种深度嵌入聚类算法,能够采用深度神经网络同时学习特征表示和执行聚类。主要贡献可以分为以下三点:
1) 联合优化深度嵌入特征表示和聚类分配结果
2) 提出了一种新颖的迭代细化的软标签
3) 在高维大数据集上的聚类实验表明,本文提出的DEC算法具有最先进的准确率和运行速度
本文最大的亮点:
采用KL散度损失函数,来衡量微调过程中表示的软标签,从而使得最终的聚类效果得到提升。该方案的初衷是:深度神经网络参数的学习一般是依靠有监督的标签来指导学习,而在无监督聚类过程中,则不能使用标签来指导网络的参数更新。因此,本文通过KL散度损失函数来指导网络参数的更新。
DEC (Deep Embedding Clsuting)模型的框架如下图:

本文模型的思路:
1) 采用encoder-decoder的自动编码器预训练,将原始的MNIST 784维非线性映射为10维的特征表示;
2) 采用预训练的特征表示输入到K-means中执行聚类,得到一组簇中心初始化聚类的簇;
3) 采用初始化的簇结合预训练的特征表示,采用KL散度损失函数对Encoder网络参数进行微调,旨在学习一组更加具有判别性的表示。
软标签的概率计算和分配公式如下:

即对每个数据点,计算一个概率q,用于衡量当前样本属于不同簇的概率。
接着,依据软标签概率p,结合初始化设定的目标分布p,采用KL散度损失来衡量微调的聚类效果,具体公式如下:

最后,通过反向传播算法,对初始化设定的簇中心u和初始化的特征表示z进行微调优化,其反向传播更新的公式如下:

1.3实验分析
本文采用的数据集信息如下:
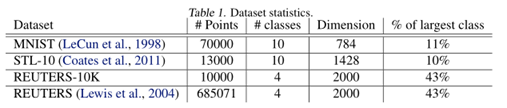
实验结果如下:
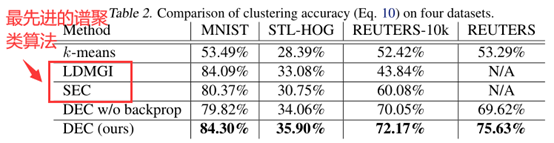

分析表3中的AE+k-means和表2中的K-means聚类结果可知,本文算法相比传统谱聚类算法取得较大提升的地方在于采用AE(自动编码器)能够学习到一组很好的特征表示,而采用AE+DEC的微调的提升幅度在MNIST上只有3%左右。
此外,本文实验的最大亮点在于对聚类簇中心和表示进行了可视化,来解释本文软标签的实际作用,我认为该实验基本是为本文的实验结果可解释性方面提升了一个台阶,具体如下图:

上图X轴表示软标签q的概率值,Y轴表示梯度的更新幅度值。默认是q越大,越靠近簇中心数字5,相关手写的图像数字5也越规范清晰,并且梯度更新幅度也越大。反之,q越小,手写数字5越像数字8,并且所占梯度更新值越小,即越可能被认定为数字8。
1.4 我的想法
上述模型的方法存在一个较严重的问题:最终模型的聚类结果和学习的特征表示初步聚类效果有较大的关联关系。即如果原始的特征表示聚类效果不理想,最终的聚类效果提升不会太大。另外,对于CIFAR-10等其它图像数据集,本文的自动编码器不能够提取到理想的差异性表示。
此外,我自己对原文网上开源的Pytorch复现版本,采用缩小版的MNIST数据集执行聚类时,发现最终的聚类效果要比采用原始完整的MNIST数据集差很多(PS: 数据集缩小幅度越大,聚类效果下降的越多)。初步的原因推测:和自动编码器结构和参数的设定有较大关系,即原文的自动编码器结构和参数是经过精细化调参后设定的,但其并不具备一般性,即该模型的参数具有较大的偏见性。初步的实验代码见链接:代码
虽然本文存在上述问题,但是本文在写作,实验和创新点方面可以被认为是深度聚类研究方面最有代表性的一篇文章,并且基本是目前所有最新关于深度聚类文章实验中的baseline方法。
2 神经协同子空间聚类(ICML, 2019)
代码:已发邮件询问作者,但是未得到回复,估计是没有公开版本源码。
2.1 动机
子空间聚类是从高维空间中部分空间维度进行特征判别性的搜索,从而将原始的高维数据划分为认定的K个簇。已有的工作需要依赖谱聚类算法,导致在大数据集上的运行和内存消耗较大。
痛点分析:
1) 子空间聚类一般需要构造亲和力(affinity)矩阵,然而其在大数据集上的构建代价很高。一般需要O(n^2)内存,O(kn^2)计算复杂度,其中k是簇的个数,n是数据点个数;
2) 谱聚类一般需要对原始数据矩阵计算奇异值矩阵(SVD),然而其在大数据集上计算获取SVD是苛刻的,即计算代价很高。
2.2 贡献
为了避免在大数据集上直接计算获取亲和力矩阵,并绕过谱聚类算法执行聚类操作,本文提出一种神经协同子空间聚类算法,主要贡献如下:
1) 为了提高子空间聚类的可扩展性,本文将子空间聚类变为了一个分类问题,从而能够去除谱聚类导致高计算量的问题;
2) 为了避免直接采用全部数据计算亲合力矩阵,本文通过训练的分类器,结合batch分组训练,能够有效降低计算亲和力矩阵的时间和内存消耗;
3) 通过分类器学习的亲和力矩阵,联合自我表示层获取的亲和力矩阵,进行协同优化,使得分类部分能够改进自我表达部分创建一个更好的亲和力矩阵,能够对含噪声和异常的数据具有更高的鲁棒性,从而提高最终的聚类效果。
本文创新点最大的亮点:
分类模块能够提取更加抽象和鉴别的特征,而自我表示模块能够捕获相似样本间的联系,能够提高对噪声和异常数据点的聚类效果。具体模型框架如下图:
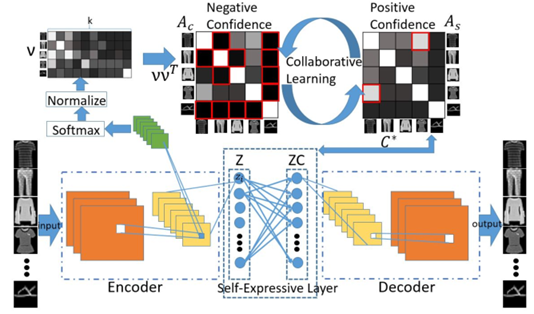
上图中Ac表示分类模块获取的消极亲和力矩阵,其计算方式如下:
采用Softmax对Encoder的隐藏层表示执行分类,其在概率大的认定为目标簇,而此处的消极亲和力是指哪些概率极低,即很大可能不属于对应目标簇的分类结果,即概率越低标记的颜色越接近黑色,具体分类演示如下图:
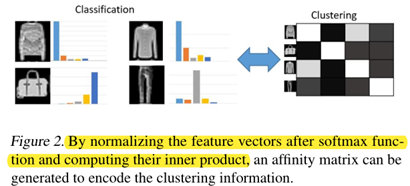
上图中的As表示采用Encoder学习的特征表示Z和ZC通过子空间聚类获取的积极亲和力矩阵。其颜色越接近白色,表示概率越大,越属于对应的簇。该矩阵返回哪些无限接近白色的数据点。其计算的公式如下所示:

本文通过协同优化计算Ac中大概率不属于某个簇的数据loss,和As中大概率属于某个簇的数据loss,来执行聚类,从而提高最终的聚类效果。协同优化的Loss定义如下:

最后,本文通过子空间聚类损失联合协同选取亲和力矩阵中数据点Loss执行最终的联合优化,具体公式和算法如下:
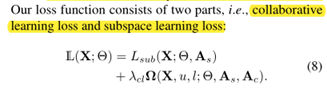

2.3 实验分析
本文采用了MNIST, Fashion-MNIST和Stanford Online Products三种数据集执行了聚类分析,并和DEC等深度聚类算法进行对比。具体结果如下:
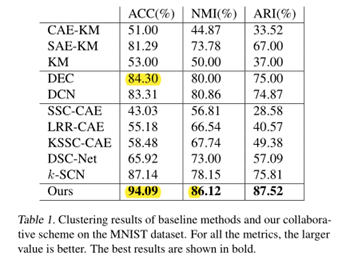
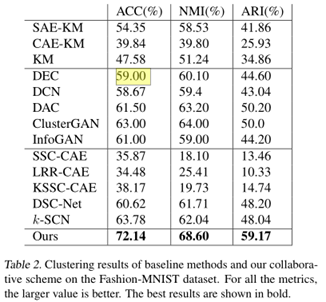
由表1和表2可以,相比DEC,本文提出的聚类算法效果要高很多。
2.4 我的想法
本文的创新点和问题分析比较容易理解,但是本文没有公开版的源码。另外,本文的实验部分做的有些简单,只是从最终的聚类结果性能进行对比分析,对于其采用的分类模块和自我表达模板获取的亲和力矩阵训练的loss作用及核心原理没有进行可视化分析,导致读者很难对本文的创新点进行深入理解(PS:即只看聚类结果,大概率只能从黑盒理论的视角来对本文的模型进行分析和理解)。
3 基于鲁棒学习的改进的无监督图像聚类 (CVPR, 2021)
3.1 动机
无监督图像聚类,经常会出现错误的预测结果和过于自信的结果。
痛点分析:
1) 深度神经网络如果在初始化时,相关数据点被认定为错误的簇时,随着训练的进行,会出现错误累积传播的现象,从而导致过于自信的错误预测结果。
2) 现有的半监督聚类算法[8](ICLR,2020),直接采用原始获取的伪标签作为ground-truth值,导致容易出现次优结果。
3.2 贡献
本文受到鲁棒学习(PS:关于鲁棒学习的概述,可以见参考资料[9])的启发,提出了一种从含噪声和错误分类结果样本中提取伪标签的聚类方法。主要贡献如下:
1) 通过已存在的聚类算法的聚类结果结合再训练能够避免过于自信的预测结果;
2) 采用本文鲁棒无监督学习获取的伪标签指导聚类算法,能够有效提高现有半监督分类聚类算法的最终聚类效果;
3) 本文的消融实验表明,本文提出的三种基于自信度量、基于基准度量和基于混合机制的干净样本选择机制,能够很好地缓解噪声样本的影响。
本文最大的亮点:通过鲁棒学习的思想,把原始的聚类伪标签结果,划分为干净样本集和不干净样本集。然后,通过干净样集指导半监督分类的聚类算法执行聚类,从而提高最终的聚类效果。具体如下图:
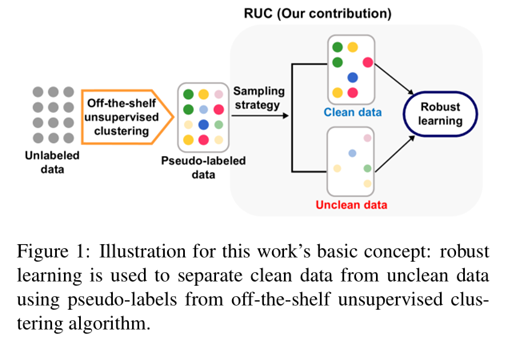
干净样本的不干净样本的选择机制如下图:

本文提出了三种机制,用于选择干净样本:
1) Confidence-based strategy
采用无监督指导的分类器分类结果来判定,即分类的概率大于阈值时,认定为干净样本。
2) Metric-based strategy
采用Encoder获取的嵌入表示,输入到两个K-NN中执行分类,如果两个分类结果一致,则认定为干净样本。
3) 结合1)和2)方法,选取交集为干净样本
本文的鲁棒学习机制,通过对标签加入鲁棒的噪声,具体如下所示:

最后,通过定义的损失函数来优化选取干净样本和不干净样本集,具体如下:
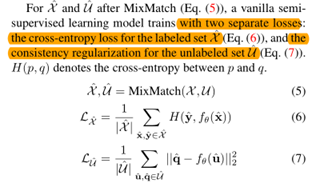
3.3 实验分析
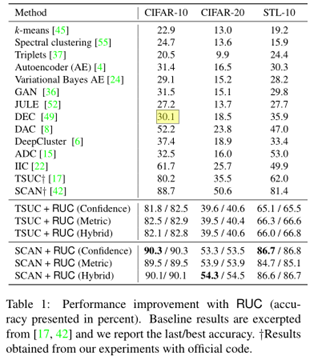
本文实验采用了CIFAR10, CIFAR100和ImageNet-50三种图像数据集执行了聚类实验,并结合半监督分类思想的TSUC和SCAN聚类算法执行了聚类,可以看出本文学习的伪标签能够较大幅度提高最终的聚类效果。
3.4 我的想法
本文最大的贡献在于表明了DEC未探讨和挖掘的原始数据包含噪声和聚类结果中容易出现过于自信的预测结果问题,并提出了本文的接近方案,从而进一步提升深度聚类效果。针对该问题,本文提出了鲁棒的无监督聚类算法来学习一组更加具有判别性的标签。
另外,本文的工作基础是一篇ICLR2020文章,该文章也有源码,具体请参考文献[8]。
4 拓展衍生
此处,简单介绍两篇最新的聚类文章,也是我后续计划深入看的文章。
1)arXiv 2021
简介:本文也是探讨采用伪标签进行聚类的文章,其目标在于学习一组更加具有判别性的伪标签,但是该文章的路线好像是和上述介绍的CVPR2021不一样。
2)AAAI 2021
简介:本文采用对比学习的思想,对图像上的高维数据集执行聚类。通过最大化积极组内点的相似度,并最小化消极组内点的相似度,从而提高最终的聚类效果。该思路,我初步感觉和本文重点提到的ICML 2019的协同子空间聚类算法有些类似。
参考文献
[1] “常用聚类算法综述,” 知乎专栏. https://zhuanlan.zhihu.com/p/78382376 (accessed Apr. 14, 2021).
[2] “用于数据挖掘的聚类算法有哪些,各有何优势? - 知乎.” https://www.zhihu.com/question/34554321 (accessed Apr. 14, 2021).
[3] “谱聚类(spectral clustering)原理总结 - 刘建平Pinard - 博客园.” https://www.cnblogs.com/pinard/p/6221564.html (accessed Apr. 14, 2021).
[4] J. Xie, R. Girshick, and A. Farhadi, “Unsupervised Deep Embedding for Clustering Analysis,” Nov. 2015, Accessed: Jan. 25, 2021. [Online]. Available: https://arxiv.org/abs/1511.06335v2.
[5] Q. Ma, J. Zheng, S. Li, and G. Cottrell, “Learning Representations for Time Series Clustering,” Dec. 2019.
[6] T. Zhang, P. Ji, M. Harandi, W. Huang, and H. Li, “Neural Collaborative Subspace Clustering,” in International Conference on Machine Learning, May 2019, pp. 7384–7393, Accessed: Apr. 05, 2021. [Online]. Available: http://proceedings.mlr.press/v97/zhang19g.html.
[7] S. Park et al., “Improving Unsupervised Image Clustering With Robust Learning,” arXiv:2012.11150 [cs], Mar. 2021, Accessed: Apr. 05, 2021. [Online]. Available: http://arxiv.org/abs/2012.11150.
[8] D. Gupta, R. Ramjee, N. Kwatra, and M. Sivathanu, “Unsupervised Clustering using Pseudo-semi-supervised Learning,” presented at the International Conference on Learning Representations, Sep. 2019, Accessed: Apr. 14, 2021. [Online]. Available: https://openreview.net/forum?id=rJlnxkSYPS.
[9] 哈工大SCIR, “鲁棒表示学习简述,” 微信公众平台. http://mp.weixin.qq.com/s?__biz=MzU2OTA0NzE2NA==&mid=2247554282&idx=3&sn=b07b18f25c000ed0143904d42257e77f&chksm=fc86f5f9cbf17cef931bf666091b485851475fec9b861269aa6742165577741e5558daa378e1#rd (accessed Apr. 15, 2021).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号