Python爬虫:爬取动态网页数据“你”需要知道的事
前一段时间在知乎或者CSDN问答上,常常看见过这样的问题,就是说为什么用Python爬虫请求某个网页时,要不就是打印出的结果数据不全,要不就是打印出的结果什么数据都没有,只有基本的html骨架代码,那么,为什么会出现这种情况呢?其实,这要涉及到了”动态网页数据“这个词了,简单而言,就是后台的数据不是请求网页链接时就已经将数据写入到相应的标签上了,而是利用ajax请求将后台的数据写入到相应的标签上。通常要得到这些数据,可以有两种方式,其一为找到这个ajax请求链接,然后访问这个链接,解析相应的json数据即可(不一定是json数据喔!);另外一种是使用selenium访问这个网址,等待网页加载完之后,然后解析相应的html标签得到这些数据。

1. 方法1-找到ajax请求链接
现在我想得到以下评论信息,很显然这些信息用到了ajax技术,直接使用requests模块或者urllib模块访问这个网址是得不到这些信息。
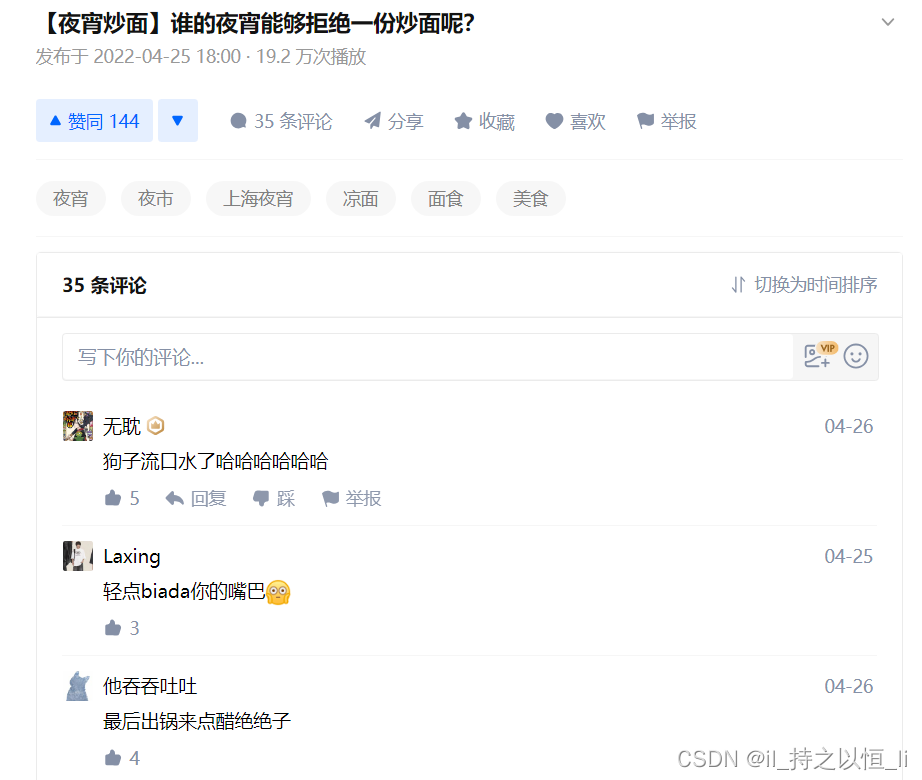
此时,应该这些评论信息的请求网址,通常在浏览器的开发者工具Network->XHR(或js)下的某一个链接里。
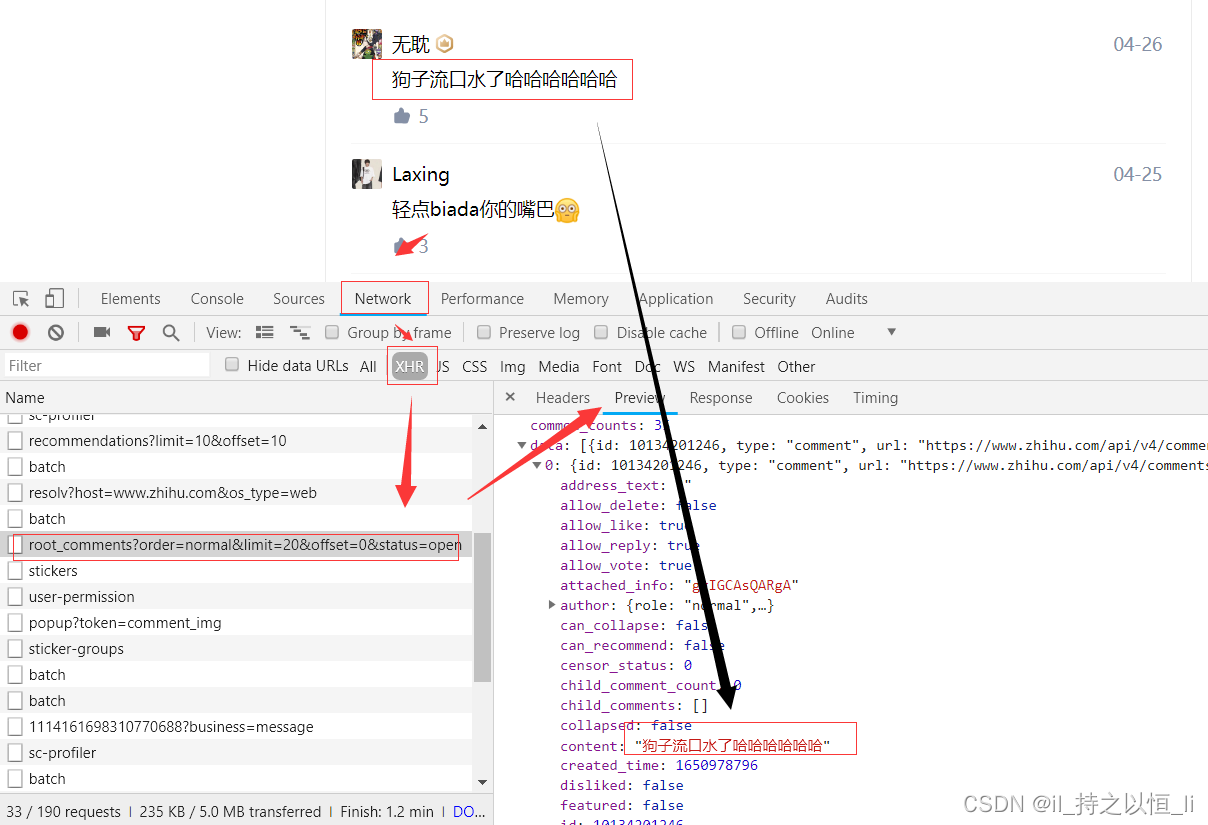
我们可以直接使用requests模块或者urllib模块访问这个网址即可。
参考代码如下:
import requests
import json
url = 'https://www.zhihu.com/api/v4/zvideos/1501903286600495105/root_comments'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36'
}
params = {
'order':'normal',
'limit':20,
'offset':0,
'status':'open'
}
rsp = requests.get(url=url,headers=headers,params=params)
dict1 = json.loads(rsp.text)
datas = dict1['data']
for data in datas:
print(data['content'])
运行结果:
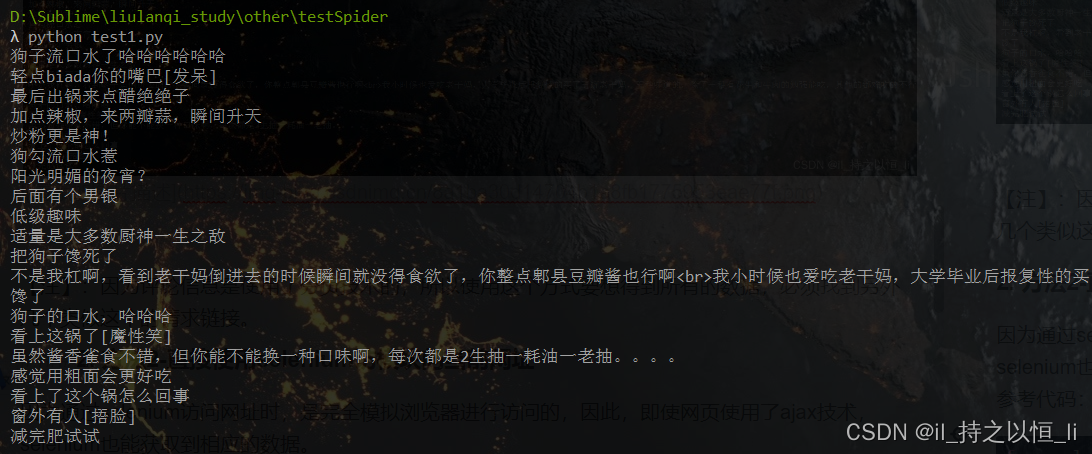
【注】:因为评论信息是使用了分页技术的,所以使用这个方式要想得到所有的数据,必须找到另外几个类似这个的请求链接。
2. 方法2-直接使用selenium模块访问当前网址
因为通过selenium访问网址时,是完全模拟浏览器进行访问的,因此,即使网页使用了ajax技术,selenium也能获取到相应的数据。
参考代码:
from selenium import webdriver
url = 'https://www.zhihu.com/zvideo/1501903286600495105'
driver = webdriver.Chrome()
driver.get(url=url)
driver.implicitly_wait(15)
# 等待网页完全加载
datas = driver.find_elements_by_xpath(
"//div[@class='CommentListV2']/ul/li[@class!='NestComment--child']//*[contains(@class,'ztext')]")
for data in datas:
print(data.text)
driver.close()
运行结果:
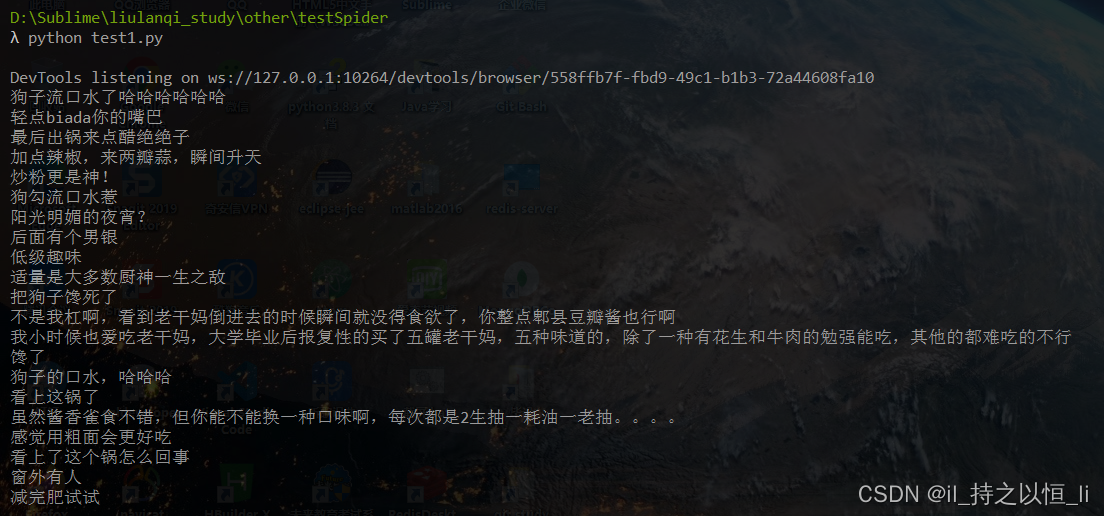
通过分析发现,两种方式获取得到数据基本相同。
本文作者:坚持不懈的大白
本文链接:https://www.cnblogs.com/liuze-2/p/16440321.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术