Python爬虫:知乎热榜(静态网页)的爬取
1. 请求知乎热榜网页
参考代码如下:
import requests
url = 'https://www.zhihu.com/hot'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36',
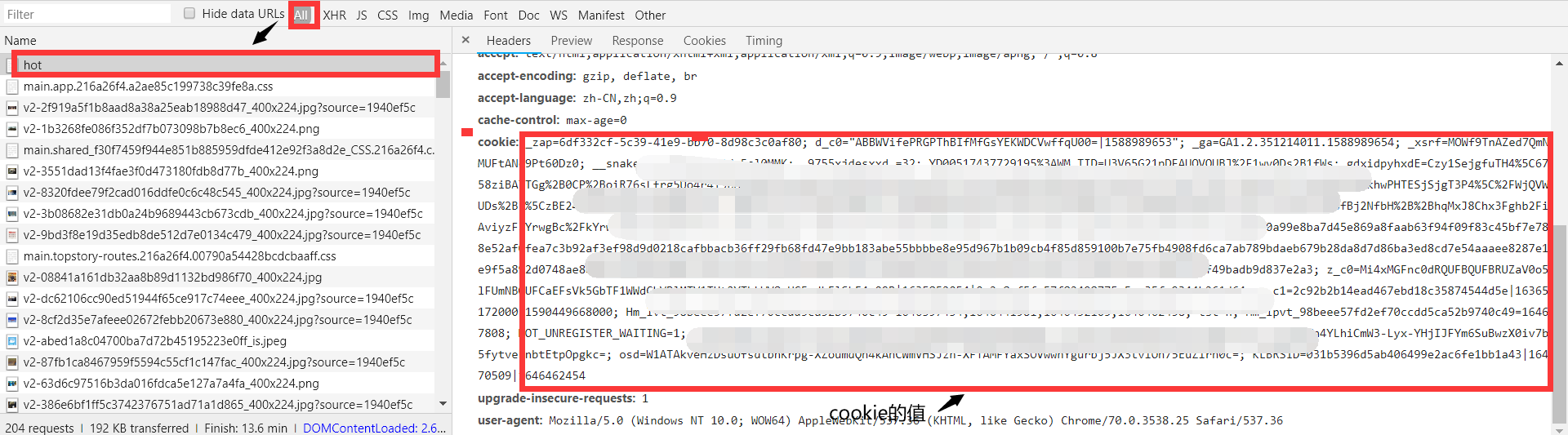
'cookie':'知乎账号下请求头的cookie的值'
}
rsp2 = requests.get(url=url,headers=headers)
因为知乎这个网站不论浏览它下面什么内容,都需要登录,所以在请求头上加了cookie这个字段以及它的值。
2. 解析热榜上的信息
2.1 使用模块pyquery进行数据解析
pq2 = pq(rsp2.text)
list1 = pq2('.HotList-list section .HotItem-content a')
for index,ele in enumerate(list1.items()):
print(index+1,ele.attr('title'),ele.attr('href'))
2.2 使用模块lxml(xpath语法)进行数据解析
html2 = etree.HTML(rsp2.text)
list2 = html2.xpath('//*[@class="HotList-list"]/section/*[@class="HotItem-content"]/a')
for i in range(len(list2)):
ele = list2[i]
print(i+1,ele.xpath('./@title')[0],ele.xpath('./@href')[0])
2.3 使用模块bs4进行数据解析
html2 = BeautifulSoup(rsp2.text,'lxml')
list3 = html2.select('.HotList-list section .HotItem-content a')
for i in range(len(list3)):
ele = list3[i]
print(i,ele['title'],ele['href'])
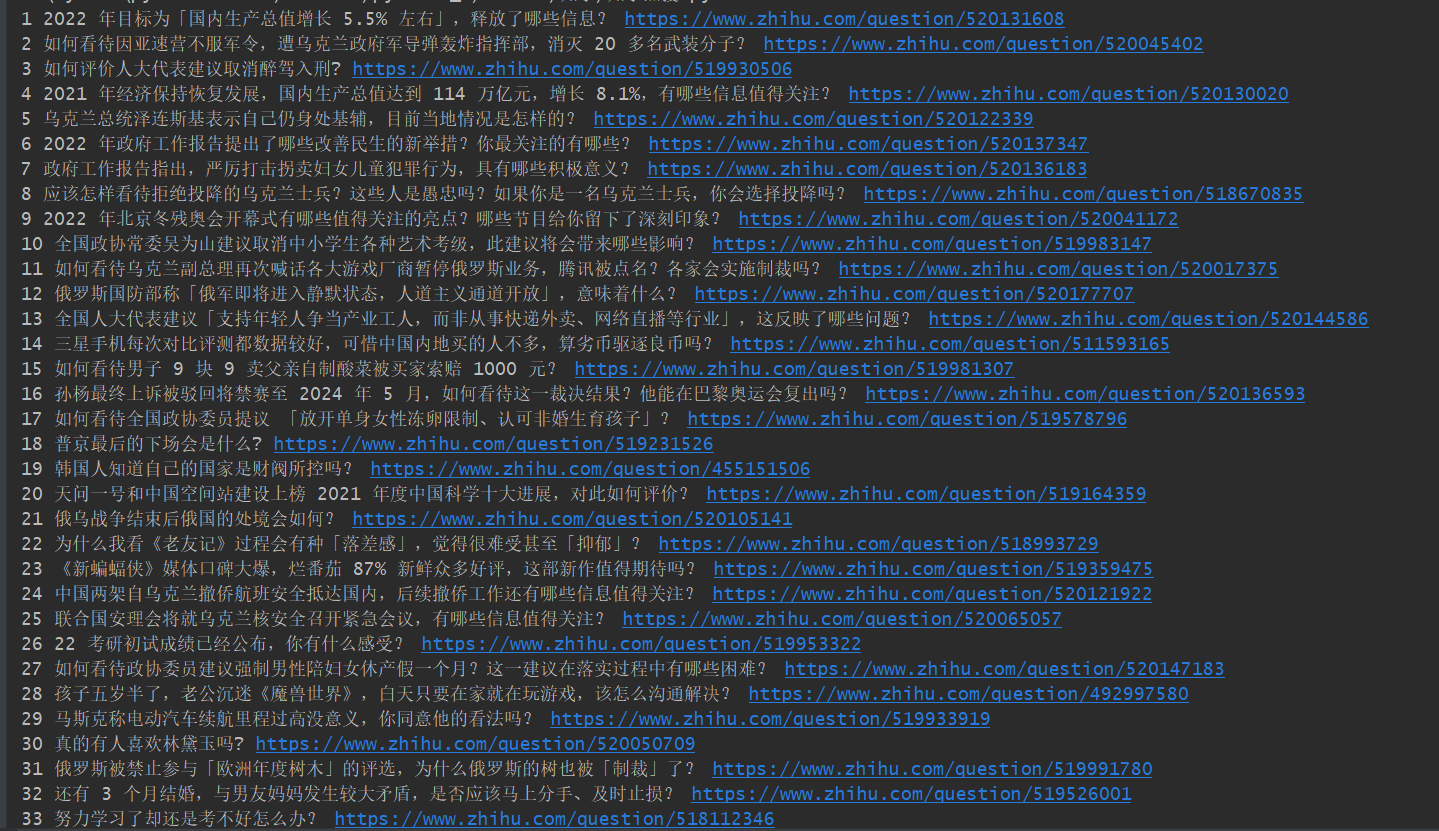
2.4 运行结果

3. 全部参考代码
from pyquery import PyQuery as pq
from lxml import etree
from bs4 import BeautifulSoup
import requests
url = 'https://www.zhihu.com/hot'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36',
'cookie':'知乎账号下请求头的cookie的值'
}
rsp2 = requests.get(url=url,headers=headers)
pq2 = pq(rsp2.text)
list1 = pq2('.HotList-list section .HotItem-content a')
for index,ele in enumerate(list1.items()):
print(index+1,ele.attr('title'),ele.attr('href'))
html2 = etree.HTML(rsp2.text)
list2 = html2.xpath('//*[@class="HotList-list"]/section/*[@class="HotItem-content"]/a')
for i in range(len(list2)):
ele = list2[i]
print(i+1,ele.xpath('./@title')[0],ele.xpath('./@href')[0])
html2 = BeautifulSoup(rsp2.text,'lxml')
list3 = html2.select('.HotList-list section .HotItem-content a')
for i in range(len(list3)):
ele = list3[i]
print(i,ele['title'],ele['href'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号