Python反爬:利用js逆向和woff文件爬取猫眼电影评分信息
 本文主要讲述利用Python爬虫抓取猫眼电影评分等数据。
本文主要讲述利用Python爬虫抓取猫眼电影评分等数据。
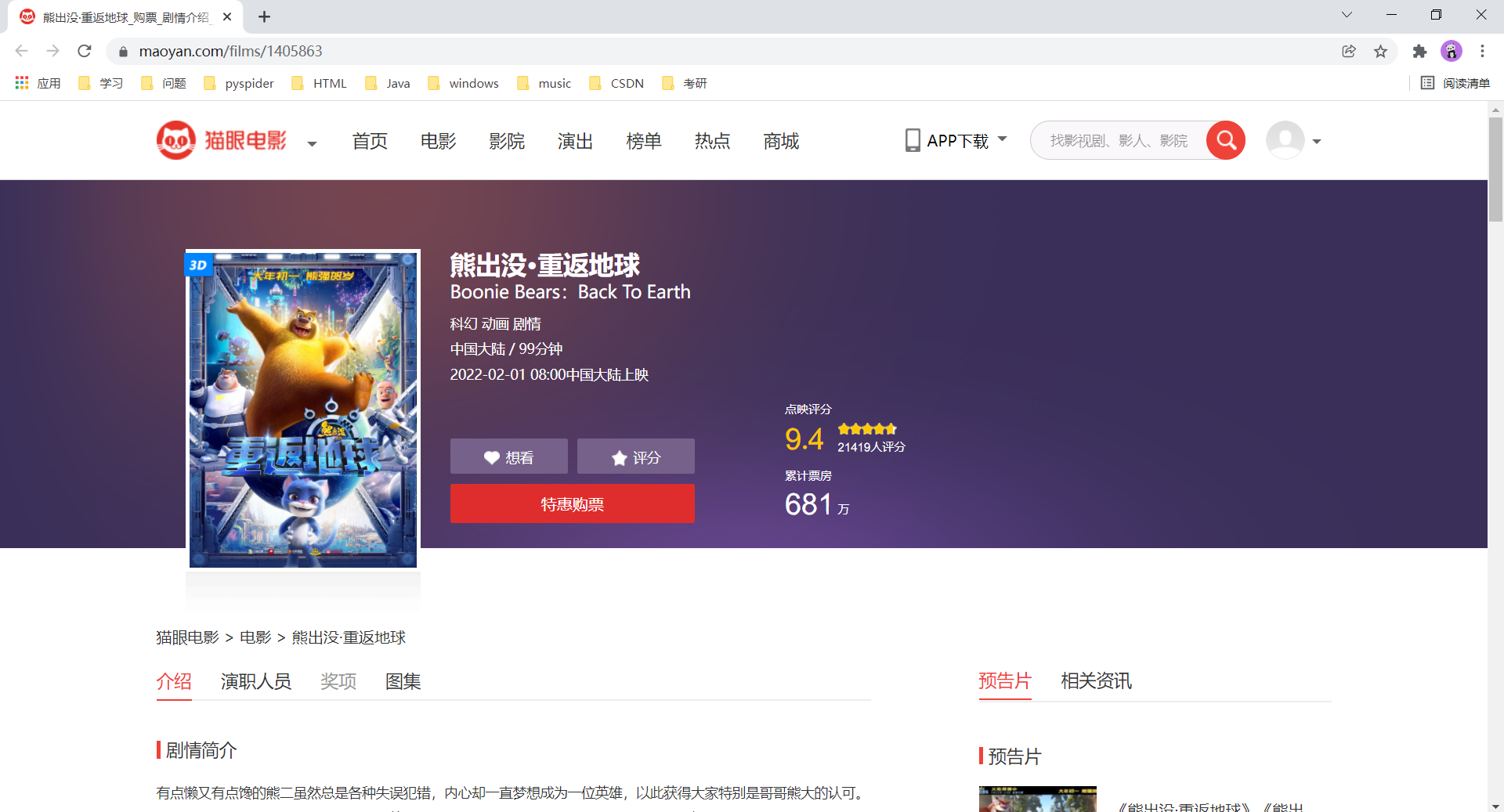
首先:看看运行结果效果如何!
1. 实现思路
小编基本实现思路如下:
-
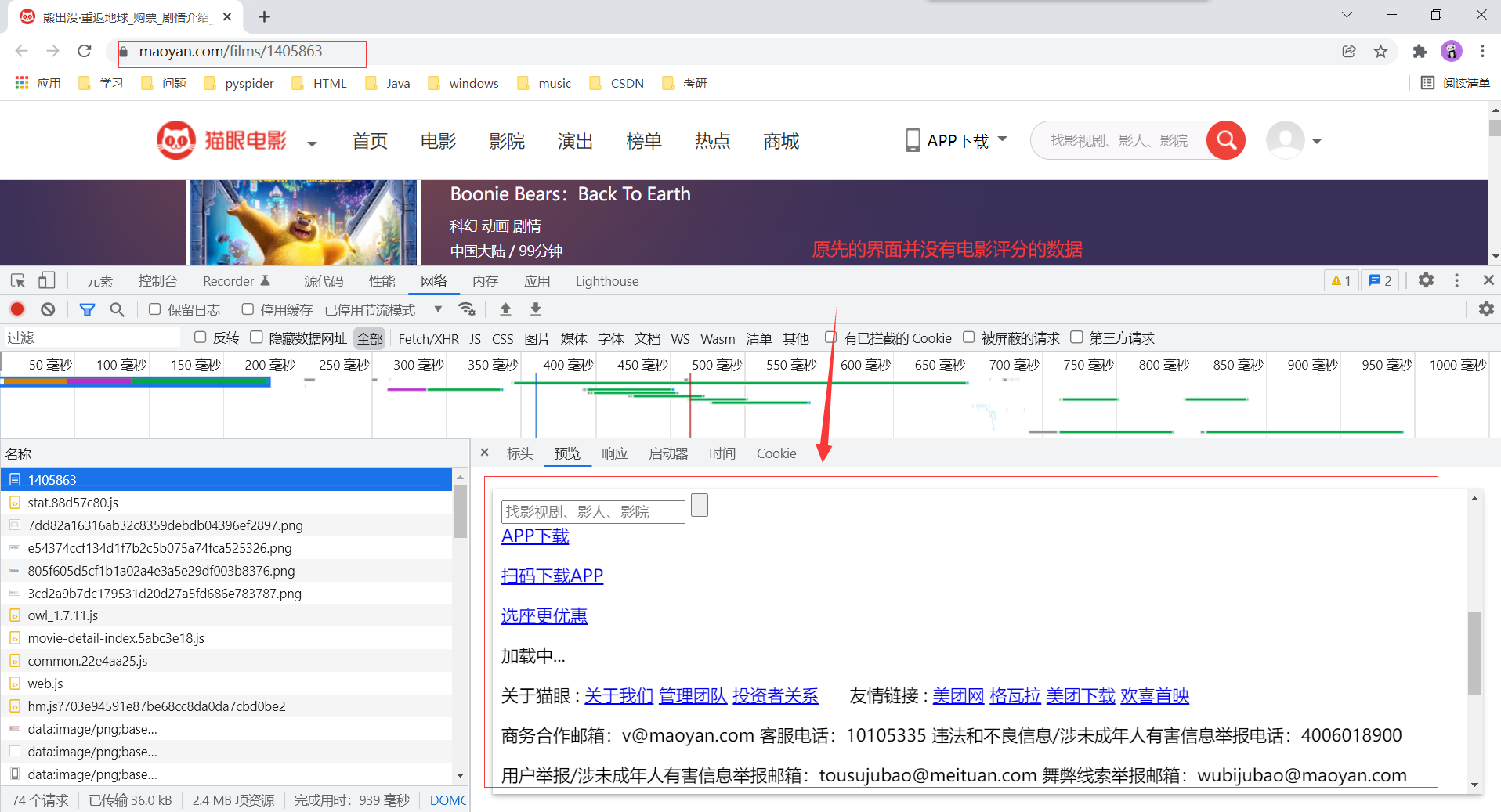
- 利用js逆向模拟请求得到电影评分的页面(就是猫眼电影的评分信息并不是我们上述看到的那个页面上,应该它的实现是在一个页面上插入另外一个页面上的一些信息)。
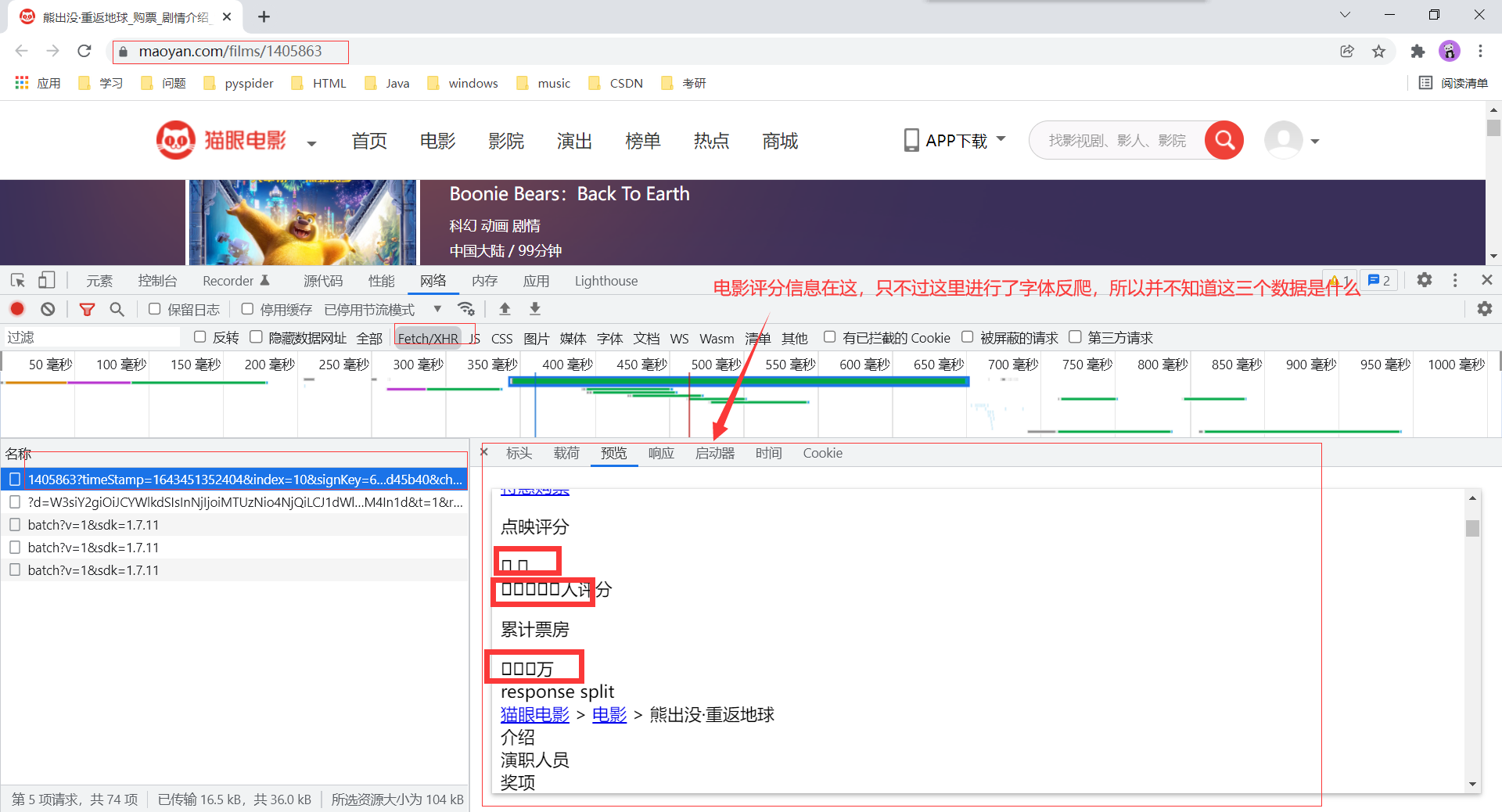
我们看一下上述这个网址的请求方式以及请求参数。
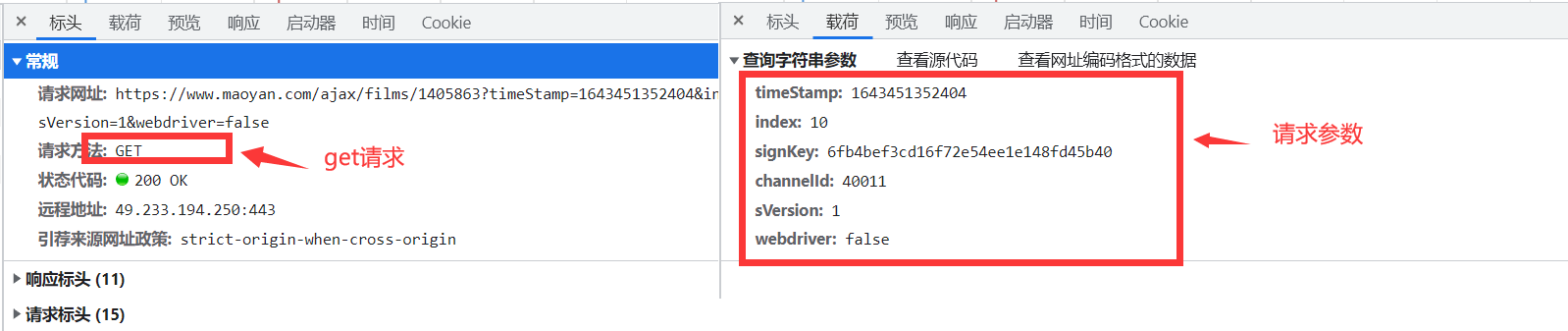
显然这个signKey 进行了加密处理。(下面请求第二点讲解怎样模拟这个请求)
- 2.通过上述模拟请求,我们最终可以得到这个评分数据,只不过看到评分数据是利用了字体加密,所以看到的是一系列 \u 开头的字符编码。如下:

第1点处理抓取评分信息之外,还需要得到这个字体的woff文件。
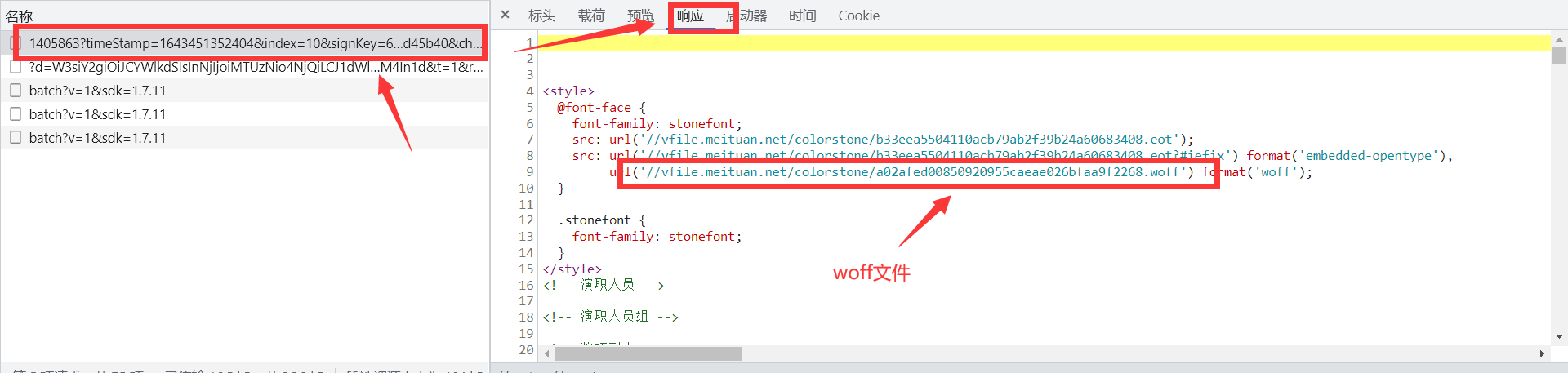
我们将这个文件的下载链接上传到这个网址上,网址链接为:https://font.qqe2.com/
我们可以看到如下结果:

我们仔细观察上述图片和 \u 开头的字符编码,可以发现如下:
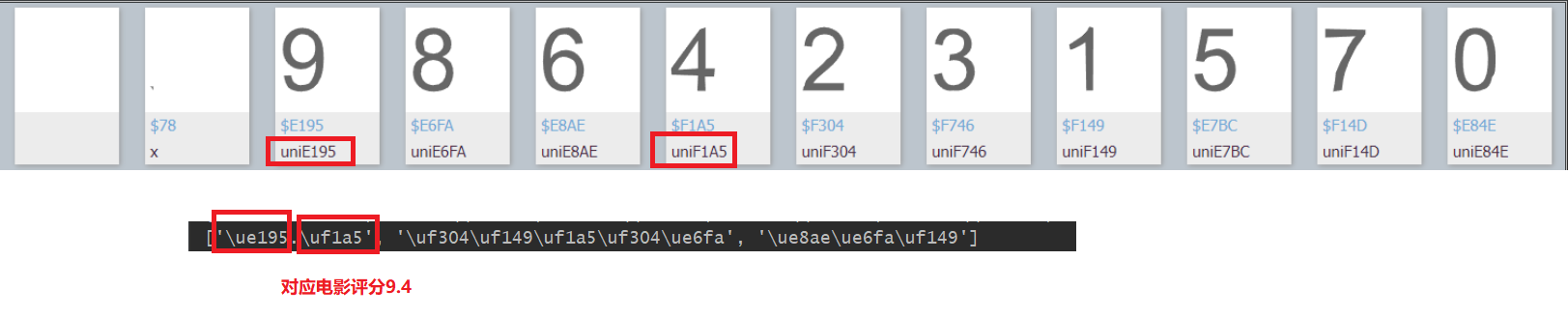
(接下来请看第3点讲解)
2. 利用js逆向模拟请求得到电影评分的页面
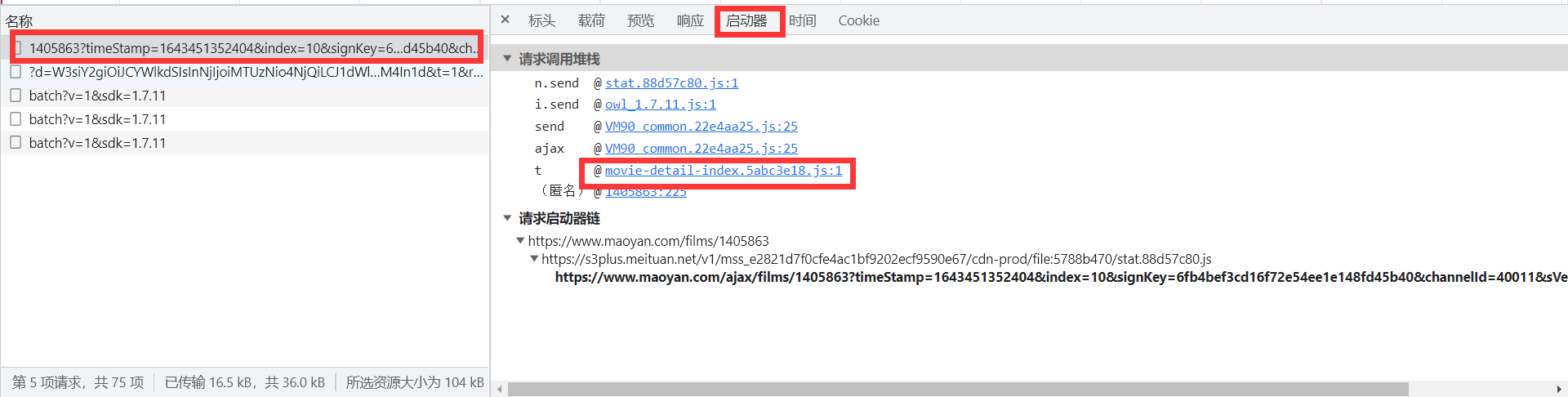
我们点击启动器下如图所示的链接,来到如下界面,对这个界面下的js代码进行断点和监听,如下:
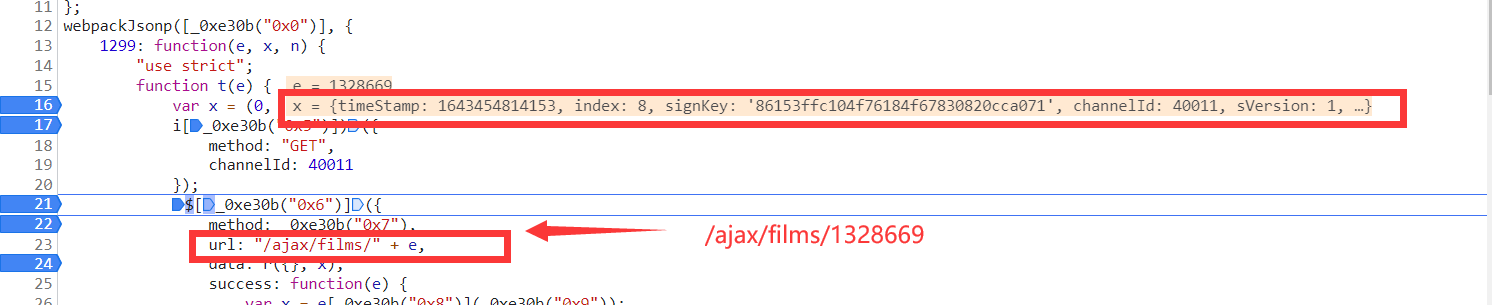
是不是发现了熟悉的身影,就是 x 变量里面的参数值是不是和小编在上述所说的get请求参数很像。
我们点击其中自定义方法i[_0xe30b("0x5")]),点击进入,然后打上断点,刷新界面之后继续监听,发现如下:
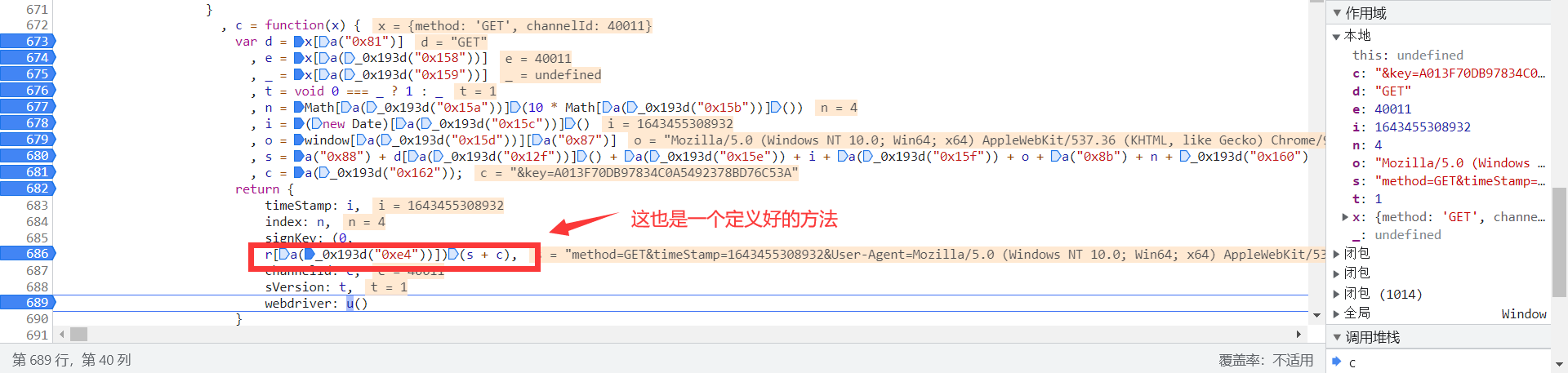
现在继续点击方法 r[a(_0x193d("0xe4"))] 进入,发现如下

其实方法 r[a(_0x193d("0xe4"))] 就是这个 x[_0x193d("0x6")] 方法,你可别看它们两的值不一样,但是 r[a(_0x193d("0xe4"))] 就是这个 x[_0x193d("0x6")] ,再也找不到第二个了。
接下来就要继续在这个方法下点击已经定义好的方法进入,然后断点,刷新和监听,重复动作,小编就不一一讲解了。
小编把本次程序中需要用到的js代码放到如下,可能和读者自己操作看到的一些js代码不一样哈!(改了一些,另外,就是猫眼电影网址那个js加密字段代码已经更新了)
var getMD5Sign = function (x) {
var c = x['method'],
e = x['channelId'],
_ = void 0 === e ? 40011 : e,
t = x['sVersion'],
n = x['type'],
a = void 0 === n ? "qs" : n,
i = Math['ceil'](10 * Math.random()),
d = (new Date)['getTime'](),
s = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36',
u = 'method=' + c + '&timeStamp=' + d + '&User-Agent=' + s + '&index=' + i + '&channelId=' + _ + '&sVersion=' + t;
f = '&key=A013F70DB97834C0A5492378BD76C53A';
return {
randomNum: i,
timeStamp: d,
md5sign: default2(u + f),
channelId: _,
sVersion: t,
params: {webdriver: false}
}
};
var default2 = function (x) {
if (void 0 === x || null === x)
throw new Error(x);
var _ = wordsToBytes(a(x));
return bytesToHex(_);
};
var _ff = function (x, c, e, _, t, n, a) {
var r = x + (c & e | ~c & _) + (t >>> 0) + a;
return (r << n | r >>> 32 - n) + c
};
var _gg = function (x, c, e, _, t, n, a) {
var r = x + (c & _ | e & ~_) + (t >>> 0) + a;
return (r << n | r >>> 32 - n) + c
};
var _hh = function (x, c, e, _, t, n, a) {
var r = x + (c ^ e ^ _) + (t >>> 0) + a;
return (r << n | r >>> 32 - n) + c
};
var _ii = function (x, c, e, _, t, n, a) {
var r = x + (e ^ (c | ~_)) + (t >>> 0) + a;
return (r << n | r >>> 32 - n) + c
};
var a = function (x) {
x = stringToBytes(x);
// x['constructor'] == String ? x = e && e['encoding'] === 'binary' ? stringToBytes(x) : stringToBytes(x) : t(x) ? x = Array.prototype.slice.call(x, 0) : Array['isArray'](x) || x.constructor === Uint8Array || (x = x['toString']());
for (var r = bytesToWords(x), i = 8 * x['length'], d = 1732584193, s = -271733879, o = -1732584194, u = 271733878, f = 0; f < r['length']; f++)
r[f] = 16711935 & (r[f] << 8 | r[f] >>> 24) | 4278255360 & (r[f] << 24 | r[f] >>> 8);
r[i >>> 5] |= 128 << i % 32,
r[14 + (i + 64 >>> 9 << 4)] = i;
for (var l = _ff, m = _gg, h = _hh, b = _ii, f = 0; f < r.length; f += 16) {
var y = d,
p = s,
L = o,
M = u;
d = l(d, s, o, u, r[f + 0], 7, -680876936),
u = l(u, d, s, o, r[f + 1], 12, -389564586),
o = l(o, u, d, s, r[f + 2], 17, 606105819),
s = l(s, o, u, d, r[f + 3], 22, -1044525330),
d = l(d, s, o, u, r[f + 4], 7, -176418897),
u = l(u, d, s, o, r[f + 5], 12, 1200080426),
o = l(o, u, d, s, r[f + 6], 17, -1473231341),
s = l(s, o, u, d, r[f + 7], 22, -45705983),
d = l(d, s, o, u, r[f + 8], 7, 1770035416),
u = l(u, d, s, o, r[f + 9], 12, -1958414417),
o = l(o, u, d, s, r[f + 10], 17, -42063),
s = l(s, o, u, d, r[f + 11], 22, -1990404162),
d = l(d, s, o, u, r[f + 12], 7, 1804603682),
u = l(u, d, s, o, r[f + 13], 12, -40341101),
o = l(o, u, d, s, r[f + 14], 17, -1502002290),
s = l(s, o, u, d, r[f + 15], 22, 1236535329),
d = m(d, s, o, u, r[f + 1], 5, -165796510),
u = m(u, d, s, o, r[f + 6], 9, -1069501632),
o = m(o, u, d, s, r[f + 11], 14, 643717713),
s = m(s, o, u, d, r[f + 0], 20, -373897302),
d = m(d, s, o, u, r[f + 5], 5, -701558691),
u = m(u, d, s, o, r[f + 10], 9, 38016083),
o = m(o, u, d, s, r[f + 15], 14, -660478335),
s = m(s, o, u, d, r[f + 4], 20, -405537848),
d = m(d, s, o, u, r[f + 9], 5, 568446438),
u = m(u, d, s, o, r[f + 14], 9, -1019803690),
o = m(o, u, d, s, r[f + 3], 14, -187363961),
s = m(s, o, u, d, r[f + 8], 20, 1163531501),
d = m(d, s, o, u, r[f + 13], 5, -1444681467),
u = m(u, d, s, o, r[f + 2], 9, -51403784),
o = m(o, u, d, s, r[f + 7], 14, 1735328473),
s = m(s, o, u, d, r[f + 12], 20, -1926607734),
d = h(d, s, o, u, r[f + 5], 4, -378558),
u = h(u, d, s, o, r[f + 8], 11, -2022574463),
o = h(o, u, d, s, r[f + 11], 16, 1839030562),
s = h(s, o, u, d, r[f + 14], 23, -35309556),
d = h(d, s, o, u, r[f + 1], 4, -1530992060),
u = h(u, d, s, o, r[f + 4], 11, 1272893353),
o = h(o, u, d, s, r[f + 7], 16, -155497632),
s = h(s, o, u, d, r[f + 10], 23, -1094730640),
d = h(d, s, o, u, r[f + 13], 4, 681279174),
u = h(u, d, s, o, r[f + 0], 11, -358537222),
o = h(o, u, d, s, r[f + 3], 16, -722521979),
s = h(s, o, u, d, r[f + 6], 23, 76029189),
d = h(d, s, o, u, r[f + 9], 4, -640364487),
u = h(u, d, s, o, r[f + 12], 11, -421815835),
o = h(o, u, d, s, r[f + 15], 16, 530742520),
s = h(s, o, u, d, r[f + 2], 23, -995338651),
d = b(d, s, o, u, r[f + 0], 6, -198630844),
u = b(u, d, s, o, r[f + 7], 10, 1126891415),
o = b(o, u, d, s, r[f + 14], 15, -1416354905),
s = b(s, o, u, d, r[f + 5], 21, -57434055),
d = b(d, s, o, u, r[f + 12], 6, 1700485571),
u = b(u, d, s, o, r[f + 3], 10, -1894986606),
o = b(o, u, d, s, r[f + 10], 15, -1051523),
s = b(s, o, u, d, r[f + 1], 21, -2054922799),
d = b(d, s, o, u, r[f + 8], 6, 1873313359),
u = b(u, d, s, o, r[f + 15], 10, -30611744),
o = b(o, u, d, s, r[f + 6], 15, -1560198380),
s = b(s, o, u, d, r[f + 13], 21, 1309151649),
d = b(d, s, o, u, r[f + 4], 6, -145523070),
u = b(u, d, s, o, r[f + 11], 10, -1120210379),
o = b(o, u, d, s, r[f + 2], 15, 718787259),
s = b(s, o, u, d, r[f + 9], 21, -343485551),
d = d + y >>> 0,
s = s + p >>> 0,
o = o + L >>> 0,
u = u + M >>> 0
}
return endian([d, s, o, u]);
};
var rotl = function (x, c) {
return x << c | x >>> 32 - c;
};
var rotr = function (x, c) {
return x << 32 - c | x >>> c;
};
var endian = function (x) {
if (x['constructor'] == Number)
return 16711935 & rotl(x, 8) | 4278255360 & rotl(x, 24);
for (var c = 0; c < x['length']; c++)
x[c] = endian(x[c]);
return x
};
var bytesToWords = function (x) {
for (var c = [], e = 0, _ = 0; e < x['length']; e++,
_ += 8)
c[_ >>> 5] |= x[e] << 24 - _ % 32;
return c
};
var wordsToBytes = function (x) {
for (var c = [], e = 0; e < 32 * x['length']; e += 8)
c['push'](x[e >>> 5] >>> 24 - e % 32 & 255);
return c
};
var stringToBytes = function (x) {
for (var c = [], e = 0; e < x.length; e++)
c['push'](255 & x.charCodeAt(e));
return c;
};
var bytesToHex = function (x) {
for (var c = [], e = 0; e < x.length; e++)
c['push']((x[e] >>> 4)['toString'](16)),
c['push']((15 & x[e])['toString'](16));
return c['join']("")
};
文件名:common.js
3. 利用pytesseract、PIL和cv2模块得到加密字符对应的原字符
这里主要运用模块pytesseract对如下图片进行识别,从而得到加密字段对应的原字段信息。当然需要下载tesseract.exe

为了提高识别的正确率,小编运用cv2对这些图片进行截取处理。
参考代码如下:
from PIL import Image
import pytesseract
import cv2
import time
img = cv2.imread(filename='./input.png')
imgInfo = img.shape
x_1 = 0
x_2 = 125
font_dict = {}
for i in range(12):
dst = img[:,x_1:x_2]
x_1 = x_2
x_2 += 125
dst2 = dst[6:100,15:120]
dst3 = dst[105:148,15:111]
cv2.imwrite(filename='1.png',img=dst2)
cv2.imwrite(filename='2.png',img=dst3)
time.sleep(1)
text2 = pytesseract.image_to_string(Image.open(fp='1.png'),
config='--psm 10 --oem 3 -c tessedit_char_whitelist=0123456789')
text3 = pytesseract.image_to_string(Image.open(fp='2.png'),lang='eng',config='--psm 6')
if text2.strip() != '':
text31 = text3.strip()
font_dict[text2.strip()] = (text31.split('\n')[0]).lower().replace('$',r'\u')
print(font_dict)
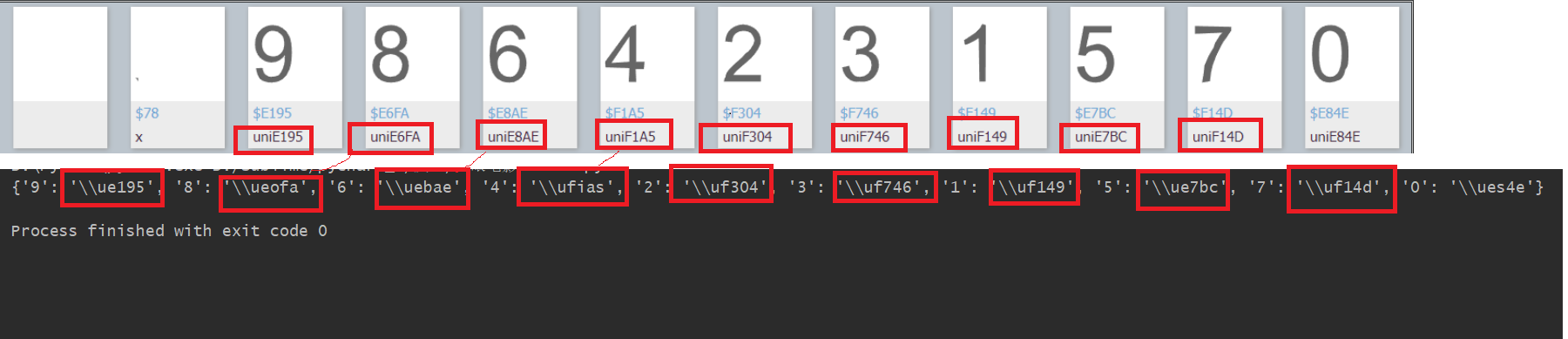
不过,这个识别的正确率还是有待提高的,不过我们可以通过其他一些代码进行处理,尽量提高它的正确度。
4. 最终实现代码
import requests
import re
import execjs
from selenium import webdriver
from lxml import etree
from PIL import Image, ImageGrab
import pytesseract
import time
import cv2
main_url = input('请输入猫眼电影网址:')
movie_id = re.findall('https://www.maoyan.com/films/(.*)', main_url)[0]
url = 'https://www.maoyan.com/ajax/films/%s' % (movie_id)
with open(file='./common.js', mode='r', encoding='utf-8') as f:
js = f.read()
ctx = execjs.compile(js) # 执行js代码
flag = {
'method': 'GET',
'channelId': 40011,
'sVersion': 1,
'type': 'object'
}
n = ctx.call('getMD5Sign', flag)
e = n['randomNum']
i = n['timeStamp']
o = n['md5sign']
c = n['channelId']
s = n['sVersion']
# _ = n['params']
params = {
'index': e,
'timeStamp': i,
'signKey': o,
'channelId': c,
'sVersion': s,
'webdriver': 'false'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
rsp = requests.get(url=url, params=params, headers=headers)
print('请求状态码为:', rsp.status_code)
font_dict = {}
infos = []
if len((rsp.text).strip()) == 0:
pass
else:
html = rsp.text
woff_href = re.findall("url('(.*?)') format('woff');", html)[0] # woff文件下载链接
woff_url = 'http:' + woff_href # woff文件的下载链接
html2 = etree.HTML(html)
infos = html2.xpath("//div[@class='movie-stats-container']//span[@class='stonefont']/text()") # 评分等信息
driver = webdriver.Chrome()
driver.get(url='https://font.qqe2.com/')
driver.implicitly_wait(15)
driver.maximize_window() # 最大窗口
ele = driver.find_elements_by_xpath("//button[@class='btn btn-flat btn-sm dropdown-toggle']")[0] # 导入按钮
ele.click() # 点击
ele2 = driver.find_element_by_xpath("//ul[@class='dropdown-menu']/li[@data-action='add-url']") # 点击从url上加载字体
ele2.click()
ele3 = driver.find_elements_by_xpath("//input[@class='form-control']")[1] # 输入框
ele3.send_keys(woff_url)
ele4 = driver.find_element_by_xpath("//button[@class='btn btn-flat btn-sm btn-confirm']")
ele4.click() # 确认按钮
time.sleep(5)
bbox = (236, 278, 1502 + 236, 164 + 278)
img = ImageGrab.grab(bbox)
img.save('input.png')
driver.close()
img = cv2.imread(filename='./input.png')
imgInfo = img.shape
x_1 = 0
x_2 = 125
for i in range(12):
dst = img[:, x_1:x_2]
x_1 = x_2
x_2 += 125
dst2 = dst[6:100, 15:120]
dst3 = dst[105:148, 10:111]
cv2.imwrite(filename='1.png', img=dst2)
cv2.imwrite(filename='2.png', img=dst3)
time.sleep(1)
text2 = pytesseract.image_to_string(Image.open(fp='1.png'),
config='--psm 10 --oem 3 -c tessedit_char_whitelist=0123456789')
text3 = pytesseract.image_to_string(Image.open(fp='2.png'),lang='eng',config='--psm 6')
if text2.strip() != '':
text31 = text3.strip()
font_dict[text2.strip()] = (text31.split('\n')[1]).lower().replace('uni', r'\u').replace('.','').replace(',','').replace('-','')
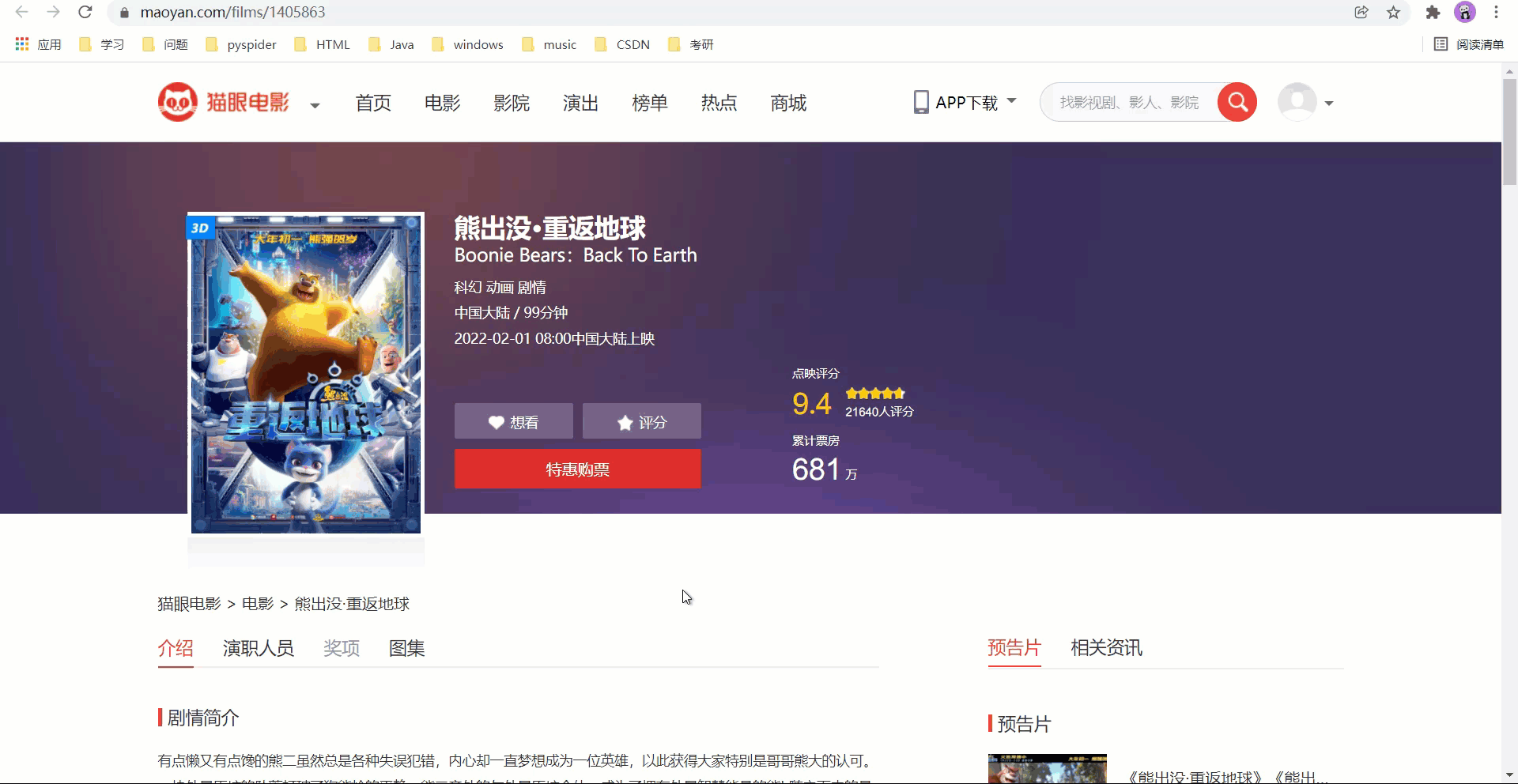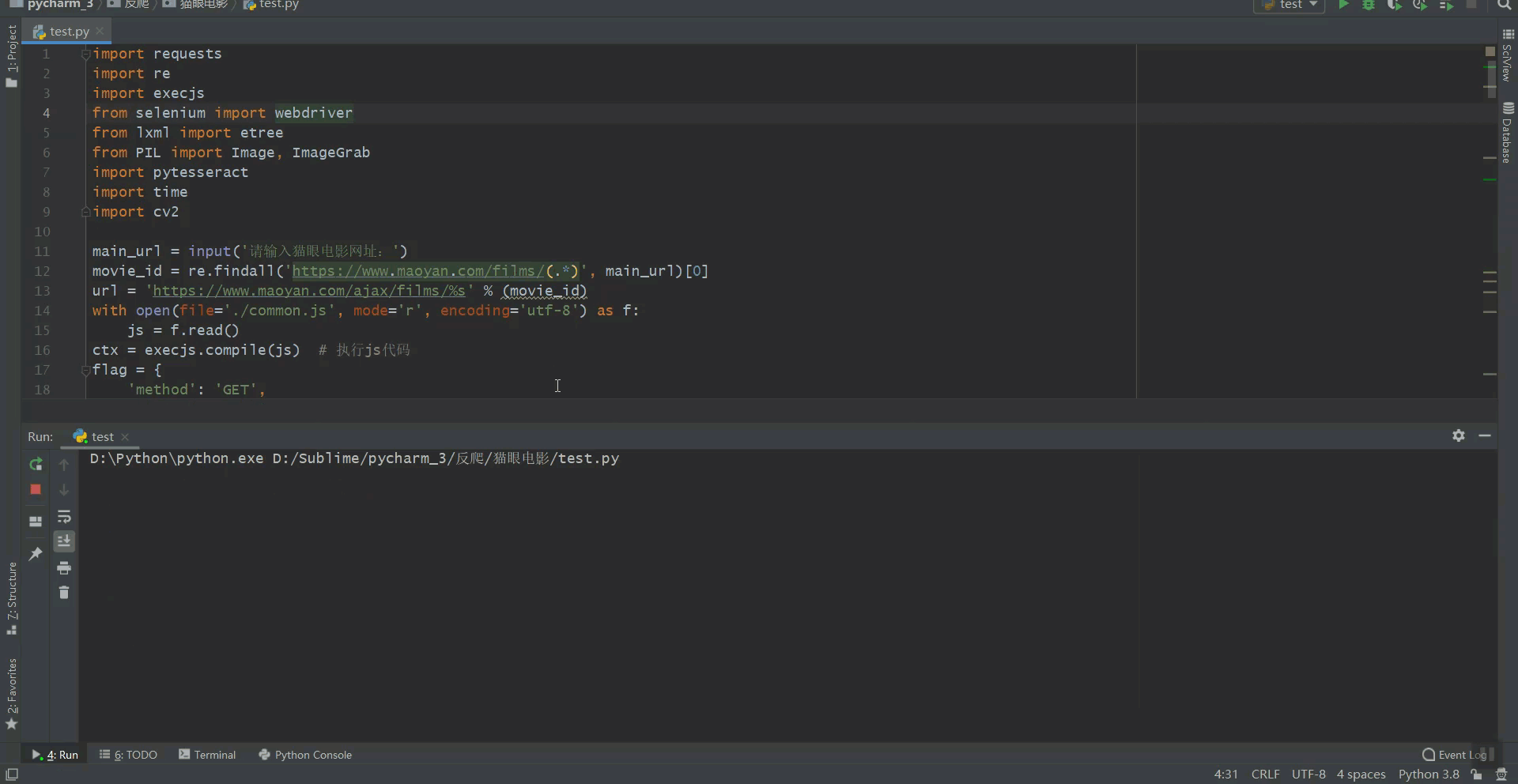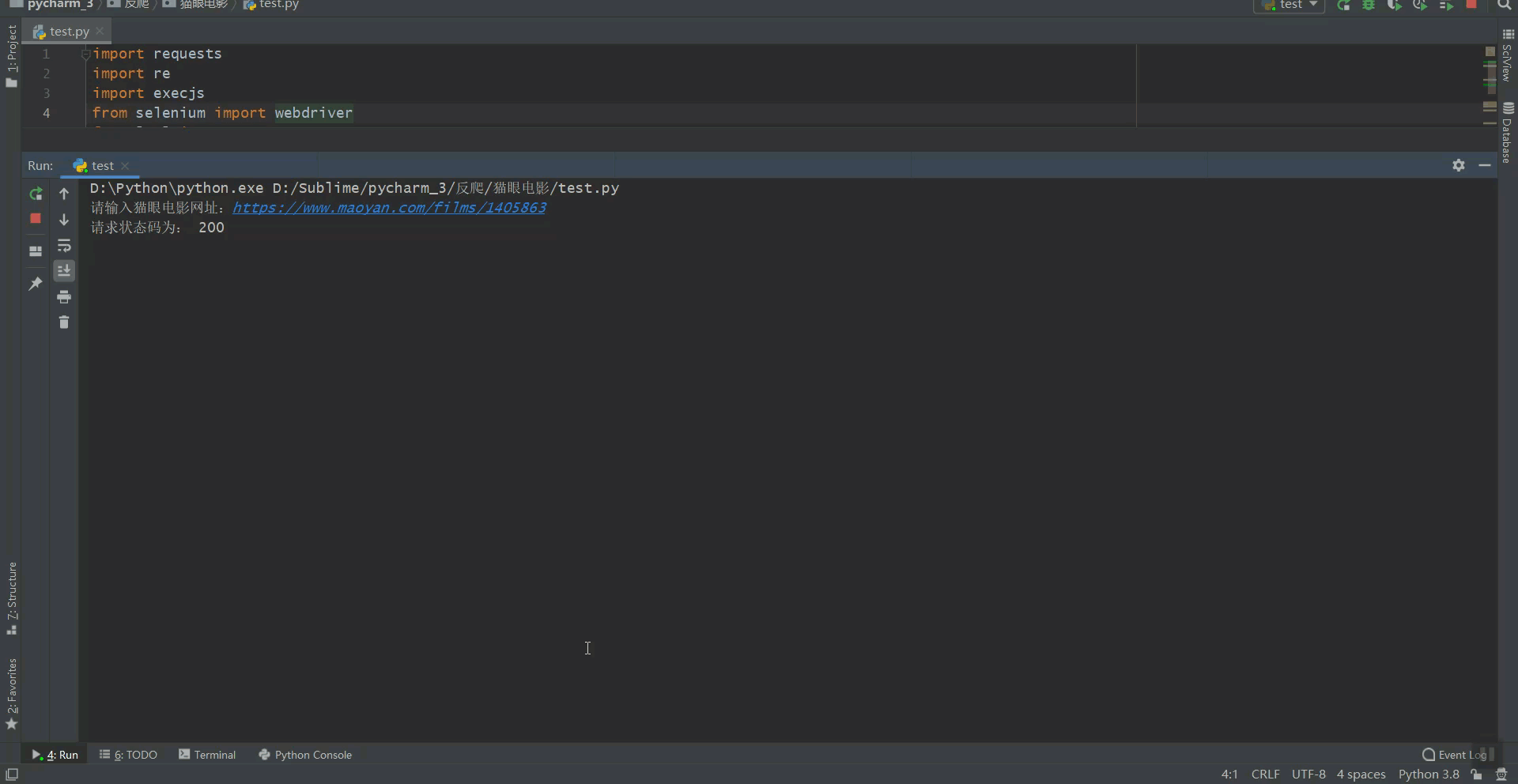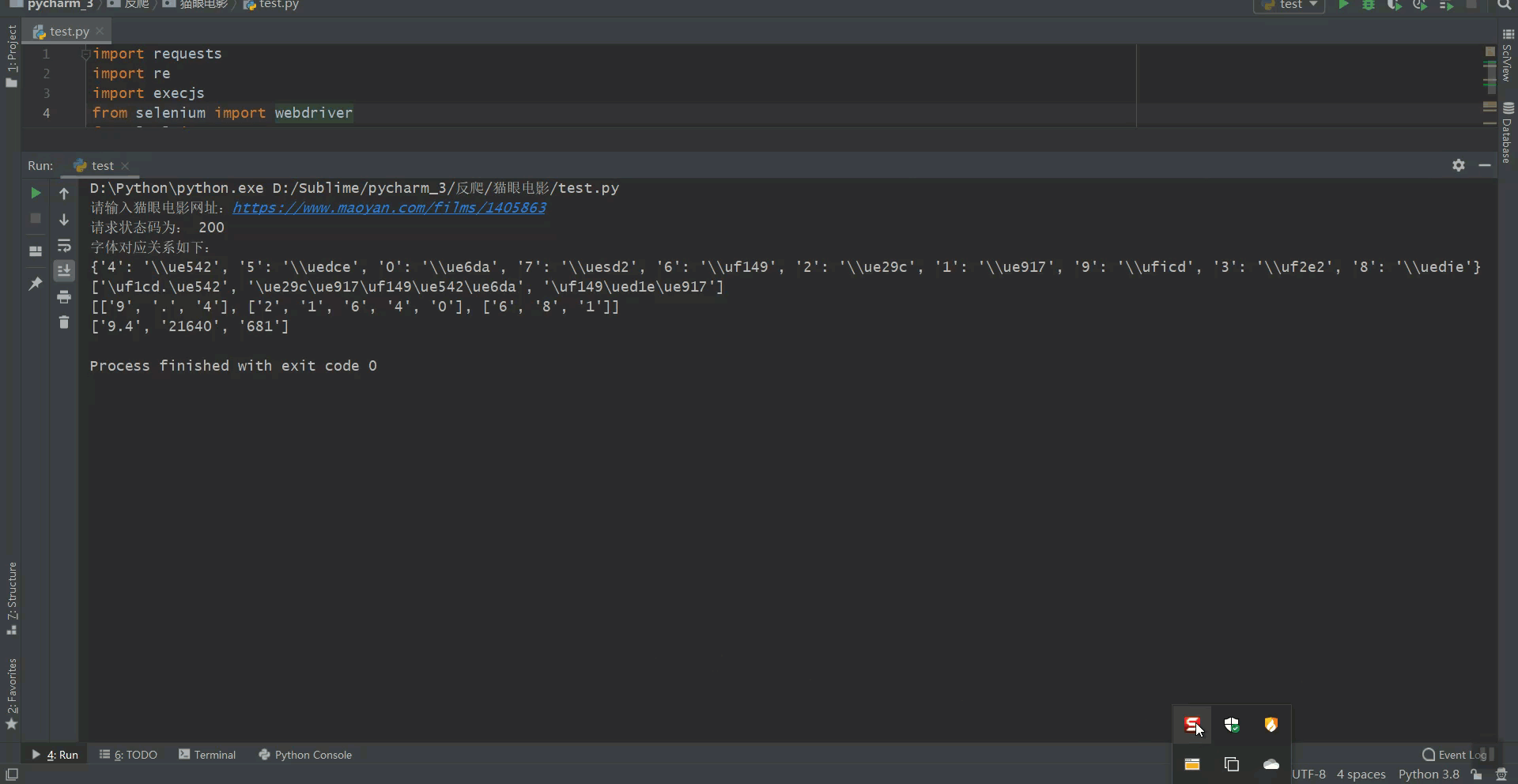
print('字体对应关系如下:')
print(font_dict)
print(infos)
mains_list = []
for i in range(len(infos)):
infos[i] = infos[i].encode('unicode_escape').decode('utf-8')
lists_u = []
index = 0
while index < len(infos[i])//6:
str_u = infos[i][index*6:(index+1)*6]
if '.' in str_u:
lists_u.append('.')
infos[i] = infos[i].replace('.','')
str_u = infos[i][index * 6:(index + 1) * 6]
lists_u.append(str_u)
else:
lists_u.append(str_u)
index += 1
mains_list.append(lists_u)
for i in range(len(mains_list)):
for j in range(len(mains_list[i])):
str_u2 = mains_list[i][j]
if str_u2 != '.':
bool_u = False
for key in font_dict:
str_u3 = font_dict[key]
if str_u3 == str_u2:
mains_list[i][j] = key
bool_u = True
if not bool_u:
for key in font_dict:
str_u3 = font_dict[key]
error = 0
for k in range(len(str_u3)):
if str_u3[k] != str_u2[k]:
if str_u3[k] == 's' and str_u2[k] == '5':
pass
else:
error += 1
if error == 0 or error ==1:
mains_list[i][j] = key
print(mains_list)
for i in range(len(mains_list)):
mains_list[i] = ''.join(mains_list[i])
print(mains_list)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号