Python爬虫:给我一个链接,快手视频随便下载
前言
讲一下,文明爬虫,从我做起(1.文章中的程序代码仅供学习,切莫用于商业活动,一经被相关人员发现,本小编概不负责!2.请在服务器闲时运行本程序代码,以免对服务器造成很大的负担.)

1. 实现原理
小编这里讲的视频都是快手上的长视频哈!链接为:快手长视频
我们随便点击其中的一个视频进入,按电脑键盘的F12键来到开发者模式,在开发者模式下按ctrl+F,输入:<video,可以找到这个视频的下载链接如下:
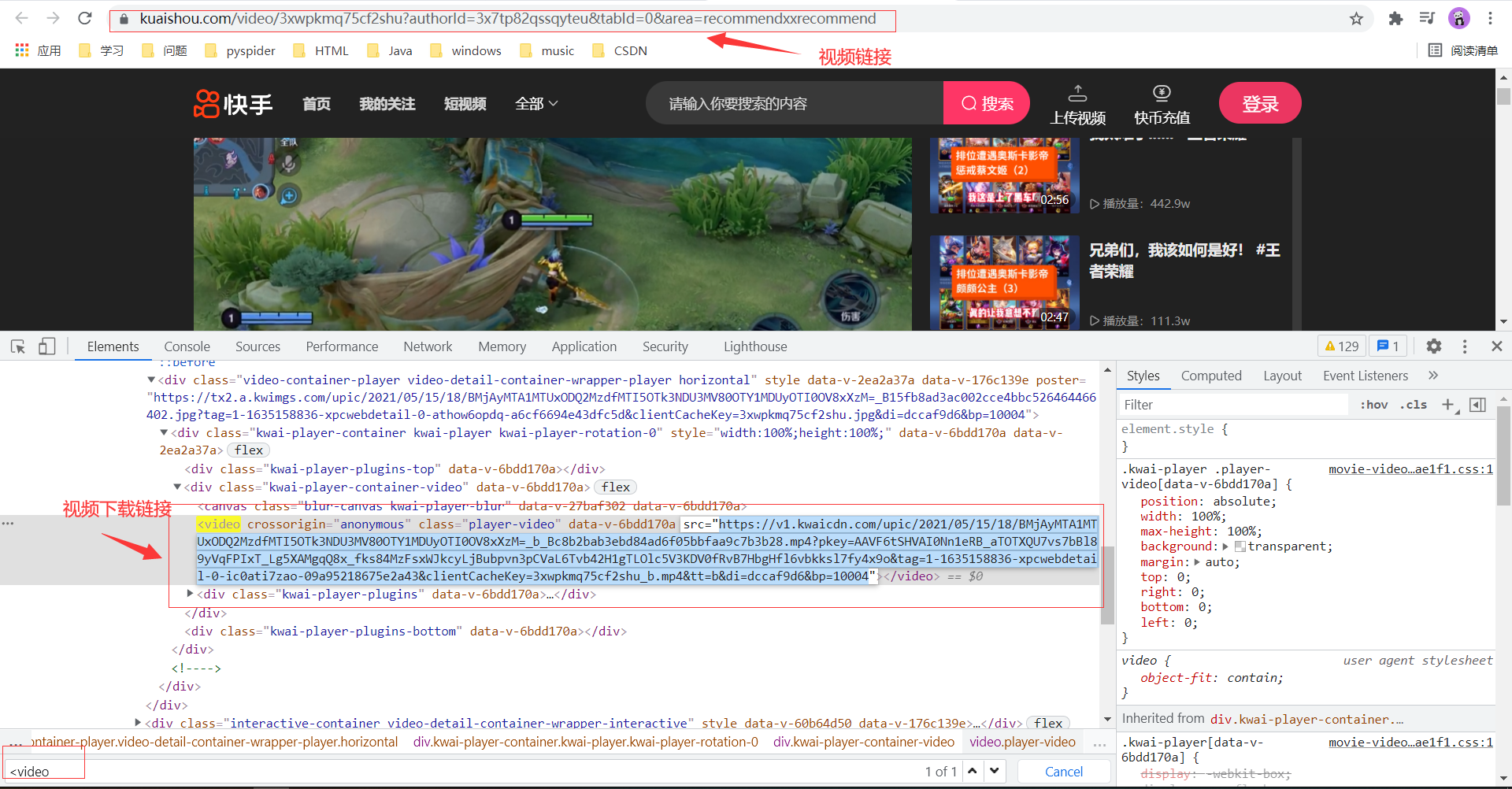

我们直接运用selenium这个模块,直接对这个页面解析简简单单就可以获取这个视频的下载链接了。
但是没有这么简单的哈!快手在这方面还是做的不错的,为了防止机器人,快手做了一个滑动窗口,如下:

代码如下:
from selenium import webdriver
driver=webdriver.Chrome()
driver.get(url='https://www.kuaishou.com/video/3xwpkmq75cf2shu?authorId=3x7tp82qssqyteu&tabId=0&area=recommendxxrecommend')
driver.implicitly_wait(5)
downloadUrl=driver.find_element_by_xpath("//video[@class='player-video']").get_attribute("src")
print(downloadUrl)
虽然我们可以通过添加一个while循环实现找到这个视频的下载链接哈!

但这是不是显得很繁琐呀!
后来想了一下,这个视频的下载链接可能是使用ajax请求从后台获取的,你还别说,还真的是这样的。
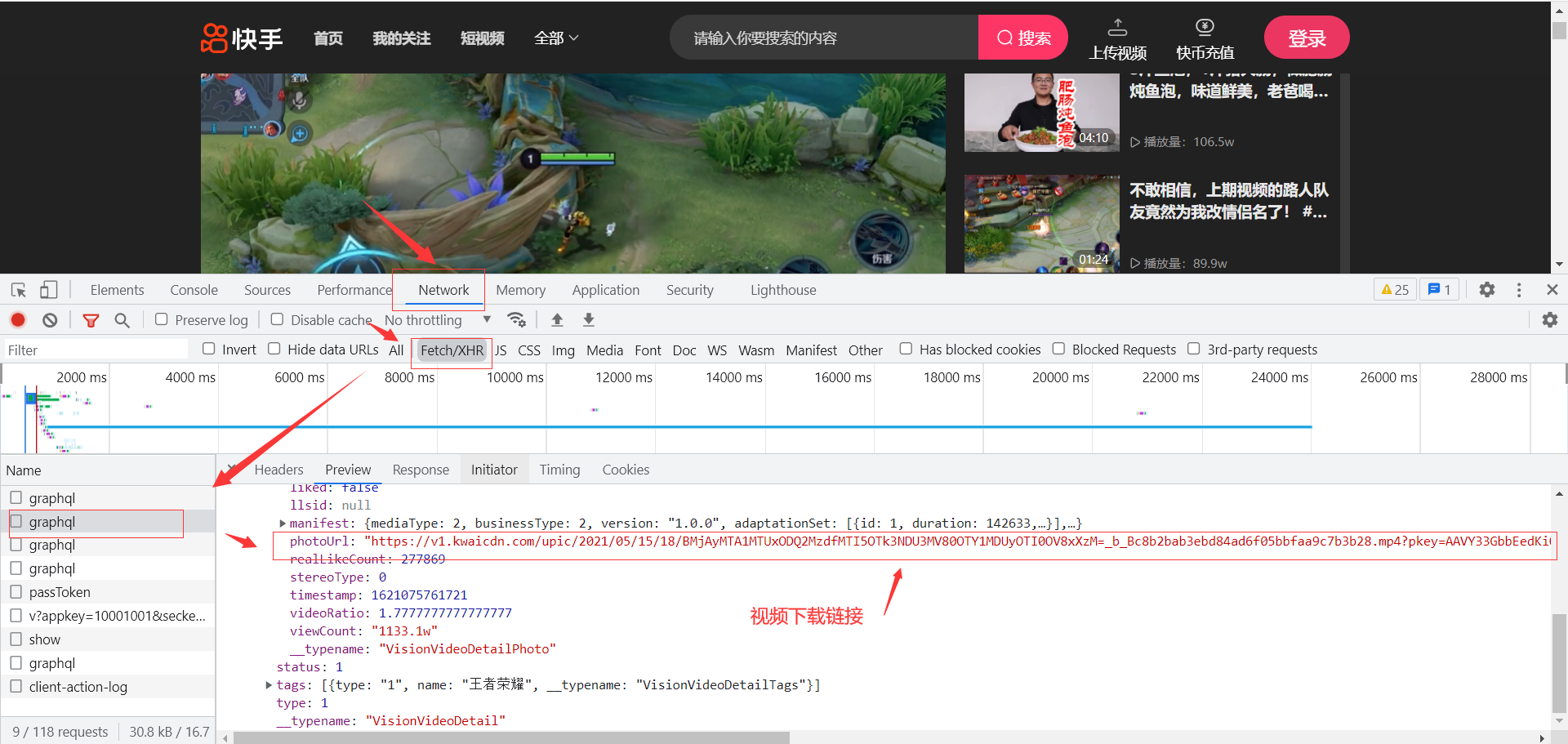
查看一下这个请求,发现是post的,请求参数如下:

经过多个视频的比较,发现只有variables下的字段不同,并且发现如下:
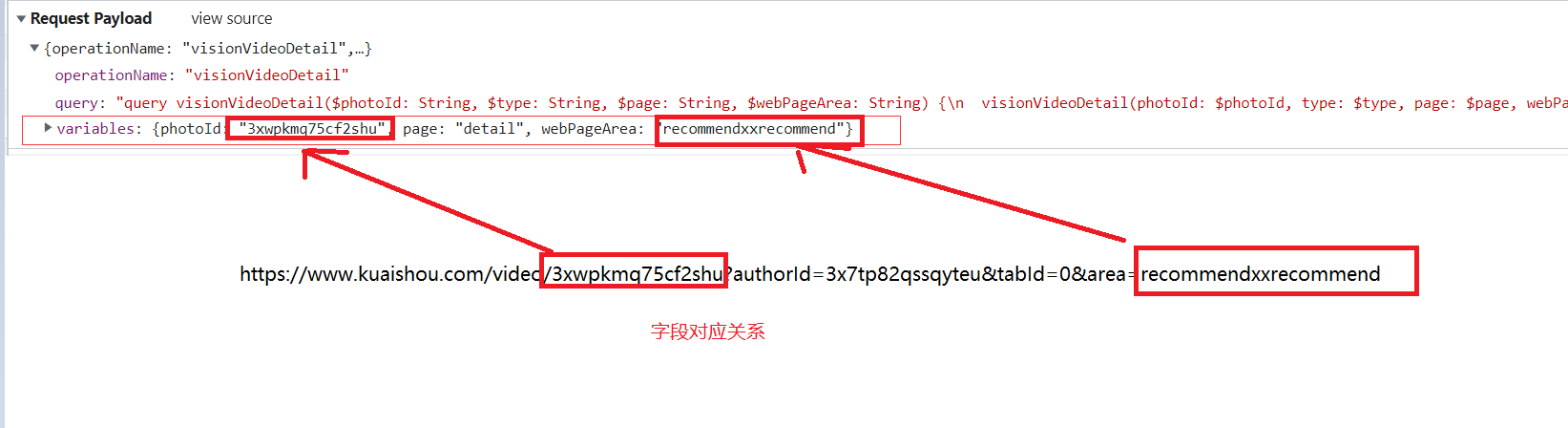
当然,有的视频链接他是没有area,相对应它的请求参数webPageArea也没有。我们可以通过使用正则表达式将上述两个参数值获取到,但是用代码发起请求时,发现虽然请求状态码为200,但是请求得到的数据却没有我们想要的视频下载链接。

cookie字段信息如下:
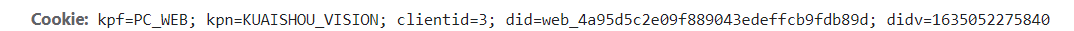
经过多个视频比较,这个cookie字段可以是固定的(除了did这个字段的值是随机生成的之外【随机生成的直接用固定即可】,其他都是固定的)。
2. 程序代码
代码如下:
import requests
from crawlers.userAgent import useragent
import json
import re
videoUrl=input("请输入视频的链接:")
# https://www.kuaishou.com/video/3xbszt6yravw739?authorId=3x45xripnn3tq5a&tabId=1&area=recommendxxfilm
photoId=re.findall(r"https://www.kuaishou.com/video/(.*)\?.*",videoUrl)[0]
try:
webPageArea=re.findall(r".*area=(.*)",videoUrl)[0]
except Exception as e:
print(e)
webPageArea=''
useragent = useragent()
url = 'https://www.kuaishou.com/graphql'
print(photoId,webPageArea)
headers = {
"user-agent": useragent.getUserAgent(), # 模拟浏览器访问
"content-type": "application/json", # 请求的参数类型为json数据
"Cookie": "kpf=PC_WEB; kpn=KUAISHOU_VISION; clientid=3; did=web_4a95d5c2e09f889043edeffcb9fdb89d; didv=1635052275840",
}
data =json.dumps({"operationName": "visionVideoDetail",
"variables": {"photoId": "%s"%(photoId), "page": "detail", "webPageArea": "{}".format(webPageArea)},
"query": "query visionVideoDetail($photoId: String, $type: String, $page: String, $webPageArea: String) {\n "
"visionVideoDetail(photoId: $photoId, type: $type, page: $page, webPageArea: $webPageArea) {\n "
"status\n type\n author {\n id\n name\n following\n headerUrl\n "
"__typename\n }\n photo {\n id\n duration\n caption\n likeCount\n "
"realLikeCount\n coverUrl\n photoUrl\n liked\n timestamp\n expTag\n "
"llsid\n viewCount\n videoRatio\n stereoType\n croppedPhotoUrl\n manifest {"
"\n mediaType\n businessType\n version\n adaptationSet {\n id\n "
" duration\n representation {\n id\n defaultSelect\n "
" backupUrl\n codecs\n url\n height\n width\n "
" avgBitrate\n maxBitrate\n m3u8Slice\n qualityType\n "
"qualityLabel\n frameRate\n featureP2sp\n hidden\n "
"disableAdaptive\n __typename\n }\n __typename\n }\n "
"__typename\n }\n __typename\n }\n tags {\n type\n name\n "
"__typename\n }\n commentLimit {\n canAddComment\n __typename\n }\n llsid\n "
"danmakuSwitch\n __typename\n }\n}\n"}) # 请求的data数据,json类型
rsp=requests.post(url=url, headers=headers, data=data)
print('响应的状态码为:',rsp.status_code)
infos=json.loads(rsp.text)
info=infos['data']['visionVideoDetail']['photo']
videoName=info['caption']
for str_i in ['?','、','╲','/','*','“','”','<','>','|']:
videoName=videoName.replace(str_i,'') # 文件重命名
print('视频的标题:',videoName)
downloadUrl=info['photoUrl']
print('视频的下载链接为:',downloadUrl)
headers={'user-agent':useragent.getUserAgent()}
rsp2=requests.get(url=downloadUrl,headers=headers)
with open(file="{}.mp4".format(videoName),mode="wb") as f:
f.write(rsp2.content)

