Python 应用爬虫下载酷狗音乐
应用爬虫下载酷狗音乐
首先我们需要进入到这个界面
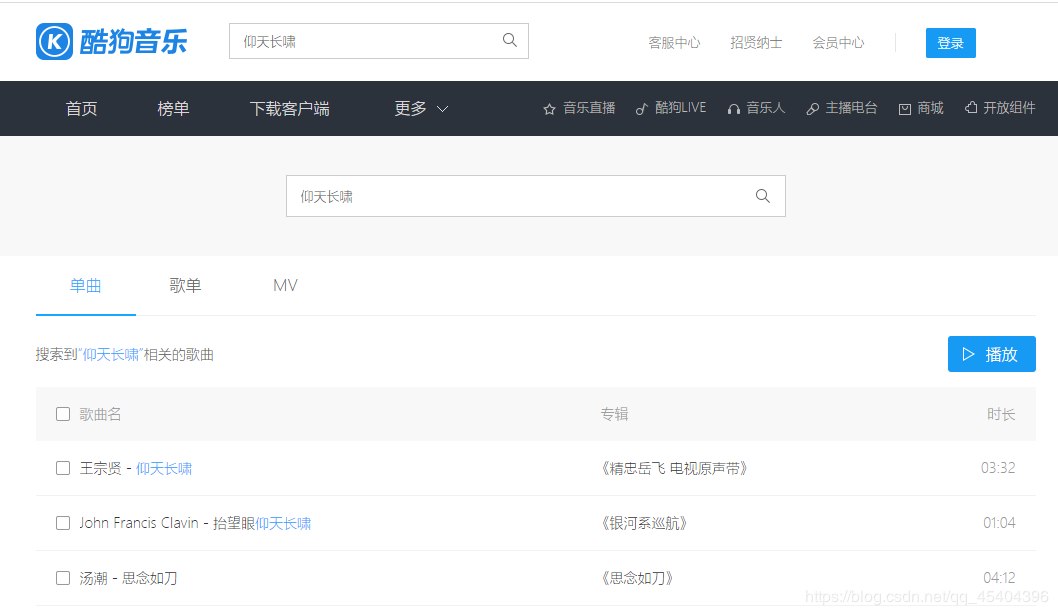
想要爬取这些歌曲链接,然而这个是一个假的网站,虽然单机右键进行检查能看到这些歌曲的链接,可进行爬取时,却爬取不到这些信息。
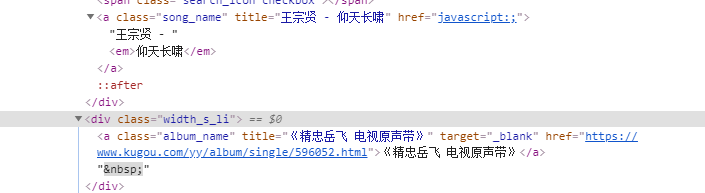
这个时候我们就应该换一种思路了,点击Network下的JS,如果没有什么信息,可按F5进行刷新。之后我们点击如下:
然后我们在点击Preview,可发现:

lists下面有我们需要的信息,可以通过这些信息重新组成一个网址:
https://www.kugou.com/song/#hash=(FileHash)&album_id=(AlbumID)
FileHash和AlbumID的值能在lists下面找到。
完成这个操作,点击进入这个组合的网址,就可以进入到这个界面了。
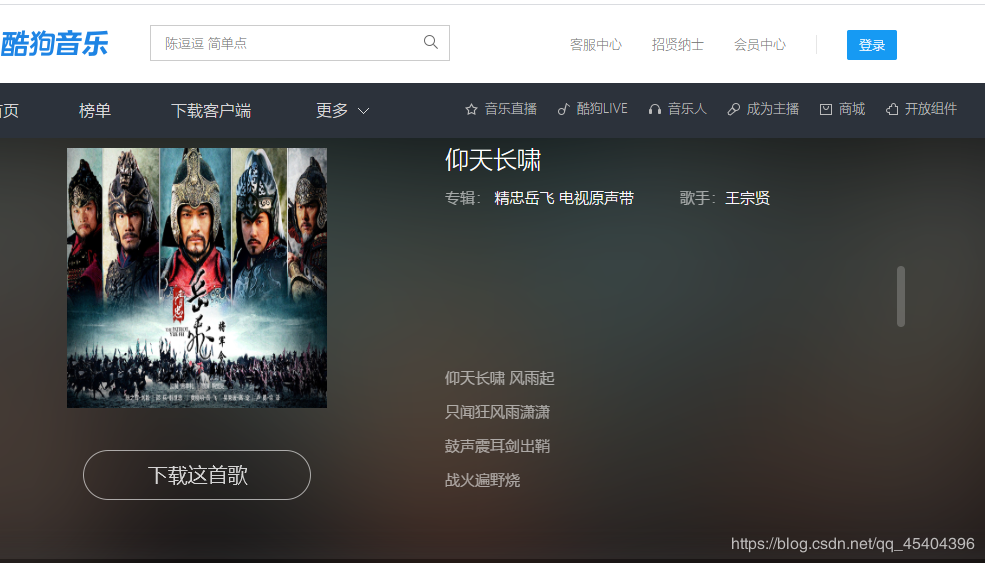
再单击右键进行检查,发现这里有这首歌的下载链接
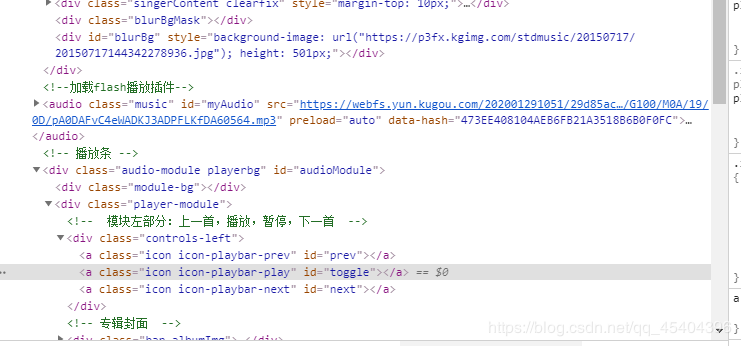
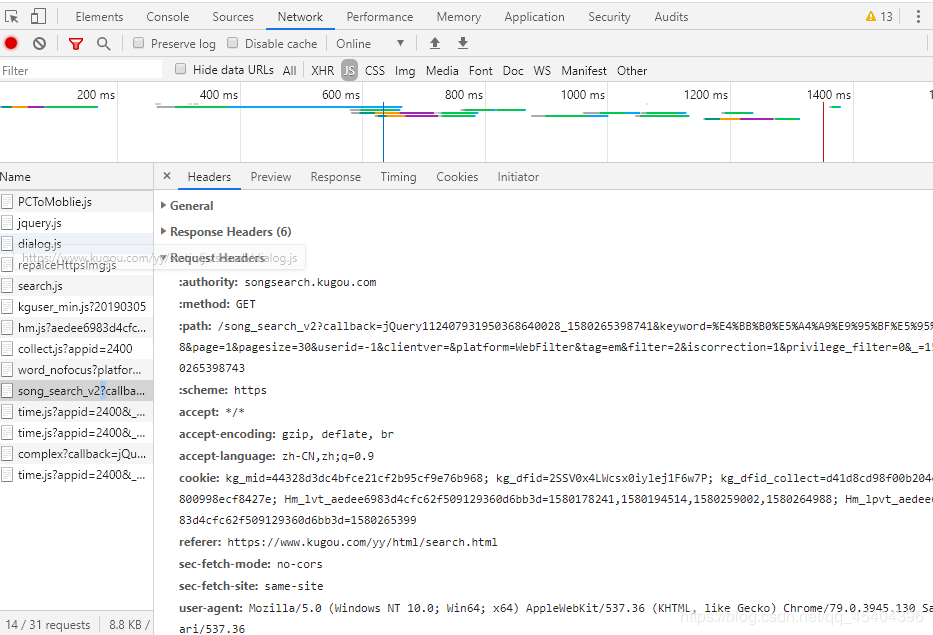
这个时候再进行爬取,发现其他信息都有,唯独没有这个下载链接,点击Network下面的JS,刷新发现有一个JS文件上有这个链接
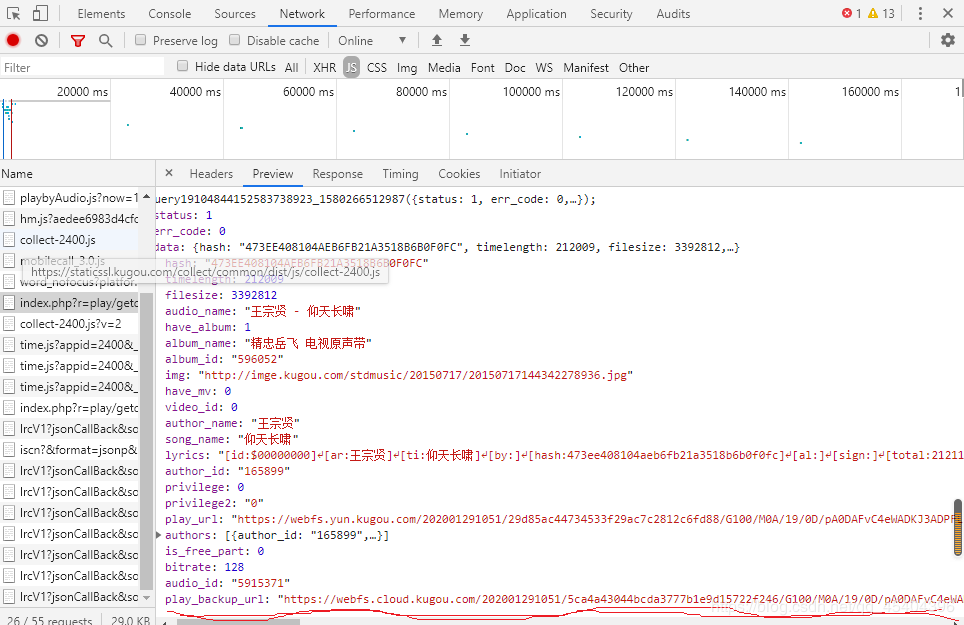
然后我们只需将这个网址进行组合即可https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19104844152583738923_1580266512987&hash=473EE408104AEB6FB21A3518B6B0F0FC&album_id=596052&dfid=2SSV0x4LWcsx0iylej1F6w7P&mid=44328d3dc4bfce21cf2b95cf9e76b968&platid=4&_=1580266512988
通过多次组合发现,这个网址只需hash、album_id、dfid、mid和platid就可以得到所需要的信息了,且dfif、mid和platid的值是不变的,而前面的两个变量的值在我说的第四幅图中可以找到。
完成这个之后,点击进入,就可以得到想要的信息了。、
代码代码如下:
from urllib.request import urlopen
import urllib.parse
import json # 导入json模块,为了使下载的js文件更容易得到所需的信息
import time
import sys
import os
# 导入sys和time模块是为了显示进度条
def Time_1(): # 进度条函数
for i in range(1,51):
sys.stdout.write('\r')
sys.stdout.write('{0}% |{1}'.format(int(i%51)*2,int(i%51)*'■'))
sys.stdout.flush()
time.sleep(0.125)
sys.stdout.write('\n')
def KuGou_music():
keyword=urllib.parse.urlencode({'keyword':input('请输入歌名:')})
keyword=keyword[keyword.find('=')+1:]
url='https://songsearch.kugou.com/song_search_v2?callback=jQuery1124042761514747027074_1580194546707&keyword='+keyword+'&page=1&pagesize=30&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1580194546709'
content=urlopen(url=url)
content=content.read().decode('utf-8')
str_1=content[content.find('(')+1:-2]
str_2=json.loads(str_1)
Music_Hash={}
Music_id={}
for dict_1 in str_2['data']['lists']:
Music_Hash[dict_1['FileName']]=dict_1['FileHash']
Music_id[dict_1['FileName']]=dict_1['AlbumID']
# print(dict_1)
list_music_1=[music for music in Music_Hash] # 匹配到的所有歌曲名 列表
list_music=[music for music in Music_Hash]
for i in range(len(list_music)):
if '- <em>' in list_music[i]:
list_music[i]=list_music[i].replace('- <em>','-')
if '</em>' in list_music[i]:
list_music[i]=list_music[i].replace('</em>','')
if '<em>' in list_music[i]:
list_music[i]=list_music[i].replace('<em>','')
# 使歌曲名称更加美观
# 如: < em > 战狼 < / em > - 断情笔 经过这个处理之后 战狼 - 断情笔
for i in range(len(list_music)):
print("{}-:{}".format(i+1,list_music[i]))
music_id_1=int(input('请输入你想下载的歌曲序号:'))
# 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=E77548A33D7AF84F727C32A786C107D0&album_id=542163&dfid=2SSV0x4LWcsx0iylej1F6w7P&mid=44328d3dc4bfce21cf2b95cf9e76b968&platid=4'
# 一个加载js文件的标椎式样网址
url='https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash='+Music_Hash[list_music_1[music_id_1-1]]+'&album_id='+Music_id[list_music_1[music_id_1-1]]+'&dfid=2SSV0x4LWcsx0iylej1F6w7P&mid=44328d3dc4bfce21cf2b95cf9e76b968&platid=4'
js_content=urlopen(url=url)
str_3=js_content.read().decode('utf-8') #所加载的js中的内容
dict_2=json.loads(str_3) # 将这个js格式转换成为字典格式
try:
music_href=dict_2['data']['play_backup_url'] #下载的歌曲网址
music_content=urlopen(url=music_href).read()
try:
os.mkdir('D:\酷狗音乐下载')
except Exception as e:
print(e,'但不要紧,程序仍然执行')
finally:
music_path='D:\酷狗音乐下载\\'+list_music[music_id_1-1]+'.mp3' # 歌曲下载路径
with open(music_path,'wb') as f:
print('正在下载当中...')
f.write(music_content)
Time_1()
print('{}.mp3下载成功!'.format(list_music[music_id_1-1]))
except:
print('对不起,没有该歌曲的版权!')
if __name__=='__main__':
print('------声明:本小程序仅供娱乐,切莫用于商业活动,一经发现,概不负责!-------')
KuGou_music()
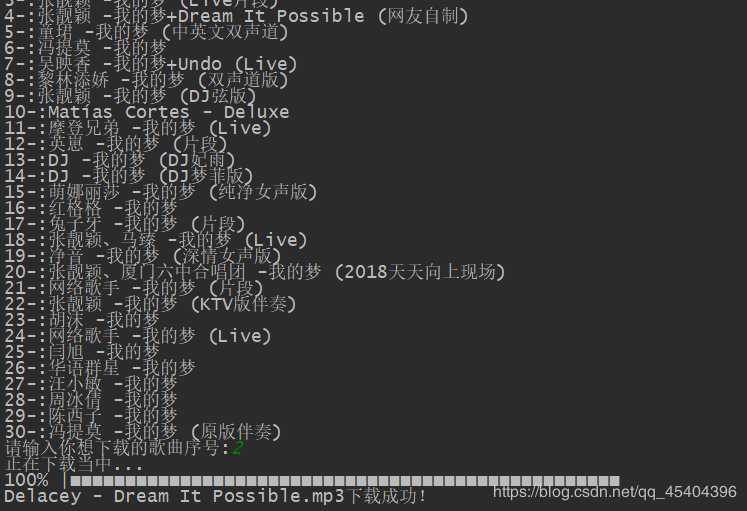
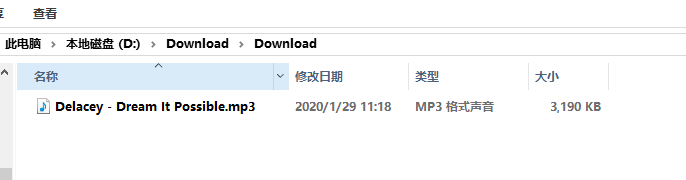
注意:代码中的那个下载路径必须是已经存在了的,否则会报错。
一些歌曲是下载不了的,如 你的名字 ,这个是付费歌曲,这个程序只能下载 酷狗音乐在网页上能播放的。
注意:这个代码仅供娱乐和学习,切莫用于商业目的,一经发现,概不负责!

