Kafka学习系列----- 生产者、分区、消费者的关系
问题引入
-
问题1 :什么是分区?
-
问题2 :分区的作用是什么?
-
问题3 :生产者和消费者分别是怎么分配的,分别对应有哪些策略?
什么是分区?
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
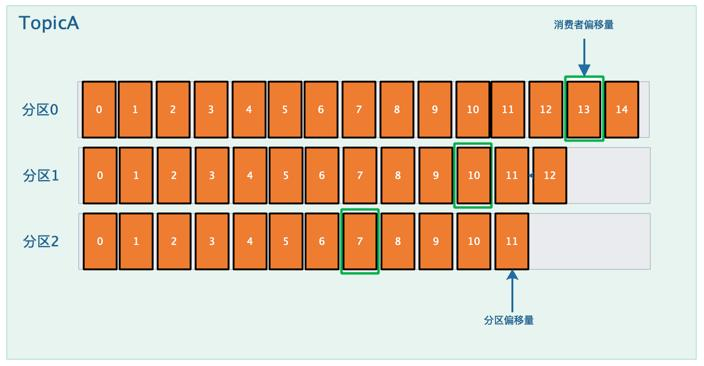
分区的作用是什么?
- 负载均衡
不同的partition 可以在不同的节点上,起到分摊负载的功能
- 水平扩展
对于突发流量等情况,水平扩展后,只要进行重新分配 分区,非常的方便。重新分配分区这款先埋个坑,后面再填。 造成rebalance的原因,rebalance的策略。。。
分区与生产者
生产者将消息投递到分区有没有规律?如果有,那么它是如何决定一条消息该投递到哪个分区的呢?
默认的分区策略
The default partitioning strategy:
- If a partition is specified in the record, use it
- If no partition is specified but a key is present choose a partition based on a hash of the key
- If no partition or key is present choose a partition in a round-robin fashion
默认的分区策略是:
- 如果在发消息的时候指定了分区,则消息投递到指定的分区
- 如果没有指定分区,但是消息的key不为空,则基于key的哈希值来选择一个分区
- 如果既没有指定分区,且消息的key也是空,则用轮询的方式选择一个分区
相关源码
// 源码 org.apache.kafka.clients.producer.internals.DefaultPartitioner
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// 消息的key也是空,则用轮询的方式选择一个分区
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// 没有可用的分区,给一个不可用的分区
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// 基于key的哈希值来选择一个分区 哈希算法 分区数取余
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
分区与消费者
有下面这几种情况:
情况一:消费者数量 <= 分区数数量
一个消费者负责多个分区去解决,一般可以设置消费者是 分区数的 n/2 倍, 比如说 有4 个 分区, 可以设置两个消费者,这两个消费者分别消费两个分区里面的消息,互不影响。
情况二: 消费者数量 > 分区数数量
出现这种情况,有一些消费者是多余的,一直接不到消息而处于空闲状态。
情况三: 分区数为 1 消费者数量 为 n
倘若,两个消费者负责同一个分区,那么就意味着两个消费者同时读取分区的消息,由于消费者自己可以控制读取消息的offset,就有可能C1才读到2,而C1读到1,C1还没处理完,
C2已经读到3了,则会造成很多浪费,因为这就相当于多线程读取同一个消息,会造成消息处理的重复,且不能保证消息的顺序,这就跟主动推送(push)无异。
消费者分区匹配策略
org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor
如果是自定义分配策略的话可以继承AbstractPartitionAssignor这个类,它默认有3个实现 也可以继承 自定义实现
- range
- roundrobin
- sticky
range
range策略对应的实现类是org.apache.kafka.clients.consumer.RangeAssignor,默认策略
步骤
1、range分配策略针对的是主题(PS:也就是说,这里所说的分区指的某个主题的分区,消费者值的是订阅这个主题的消费者组中的消费者实例)
2、首先,将分区按数字顺序排行序,消费者按消费者名称的字典序排好序
3、然后,用分区总数除以消费者总数。如果能够除尽,则皆大欢喜,平均分配;若除不尽,则位于排序前面的消费者将多负责一个分区
注意:上面的分配是针对 一个主题 里面的分区的策略
例如,假设有两个消费者C0和C1,两个主题t0和t1,并且每个主题有3个分区,分区的情况是这样的:
t0p0,t0p1,t0p2,t1p0,t1p1,t1p2
那么消费者C0和C1 分别消费哪些分区???
答案是
消费者C0 消费分区 t0p0,t0p1,t1p0,t1p1
消费者C1 消费分区 t0p2,t1p2
因为,对于主题t0,分配的结果是C0负责P0和P1,C1负责P2;对于主题t2,也是如此,综合起来就是这个结果
上代码
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
// 主题与消费者的映射
Map<String, List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<TopicPartition>());
for (Map.Entry<String, List<String>> topicEntry : consumersPerTopic.entrySet()) {
String topic = topicEntry.getKey(); // 主题
List<String> consumersForTopic = topicEntry.getValue(); // 消费者列表
// partitionsPerTopic表示主题和分区数的映射
// 获取主题下有多少个分区
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null)
continue;
// 消费者按字典序排序
Collections.sort(consumersForTopic);
// 分区数量除以消费者数量
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size();
// 取模,余数就是额外的分区
int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size();
List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
for (int i = 0, n = consumersForTopic.size(); i < n; i++) {
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
// 分配分区
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
return assignment;
}
roundrobin
轮询分配策略是基于所有可用的消费者和所有可用的分区的,与前面的range策略最大的不同就是它不再局限于某个主题
如果所有的消费者实例的订阅 主题数 都是相同的,那么这样最好了,可用统一分配,均衡分配
例如,假设有两个消费者C0和C1,两个主题t0和t1,每个主题有3个分区,分别是t0p0,t0p1,t0p2,t1p0,t1p1,t1p2
那么,最终分配的结果是这样的:
C0: [t0p0, t0p2, t1p1]
C1: [t0p1, t1p0, t1p2]
假设,组中在同一个消费者组里面,每个消费者订阅的主题不一样,分配过程仍然以轮询的方式考虑每个消费者实例,但是如果没有订阅主题,则跳过实例。当然,这样的话分配肯定不均衡。
同组意味着一个分区只能分配给组中的一个消费者。事实上,同组也可以不同订阅,这就是说虽然属于同一个组,但是它们订阅的主题可以是不一样的。
例如,假设有3个主题t0,t1,t2;其中,t0有1个分区p0,t1有2个分区p0和p1,t2有3个分区p0,p1和p2;有3个消费者C0,C1和C2;C0订阅t0,C1订阅t0和t1,C2订阅t0,t1和t2。
那么 消费者 C0,C1,C2 分别消费哪些分区 ???
首先,肯定是轮询的方式,其次,比如说有主题t0,t1,t2,它们分别有1,2,3个分区,也就是t0有1个分区,t1有2个分区,t2有3个分区;
有3个消费者分别从属于3个组,C0订阅t0,C1订阅t0和t1,C2订阅t0,t1,t2;
那么,按照轮询分配的话,
C0应该负责t0p0,C1应该负责t1p0,其余均由C2负责。
但是结果是
C0: [t0p0]
C1: [t1p0]
C2: [t1p1, t2p0, t2p1, t2p2]
这是因为,按照轮询t0p1由C0负责,t1p0由C1负责,由于同组,C2只能负责t1p1,由于只有C2订阅了t2,所以t2所有分区由C2负责,综合起来就是这个结果
sticky
sticky 翻译是黏性的 ,从 0.11 开始引入这种策略,主要特点有:
- 分区的分配要尽可能的均匀
- 分区的分配要尽可能和上次保持相同
举个例子:
三个消费者C0,C1,C2
四个主题: t0,t1,t2,t3 每个主题 有两个分区 p0,p1
也就是 t0p0,t0p1, t1p0,t1p1 t2p0,t2p1 ,t3p0,t3p1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号