『忘了再学』Shell流程控制 — 33、if条件判断语句(一)
什么是流程控制?
- 普通理解:Shell编写的程序是顺序执行的,也就是说第一命令先执行,然后接着执行第二条命令,然后再下一条,以此类推,而流程控制就是改变上面这种顺序执行的方式。
- 官方理解:流程控制语句用于控制程序的流程, 以实现程序的各种结构方式,即用来实现对程序流程的选择、循环、转向和返回等进行控制。
Shell中的流程控制语句分为:
if条件判断语句。case条件判断语句。for循环语句。while循环语句。until循环语句。
1、单分支if条件语句
单分支条件语句最为简单,就是只有一个判断条件,如果符合条件则执行某个程序,否则什么事情都不做。
语法如下:
if[ 条件判断式 ];then
程序
fi
单分支条件语句需要注意几个点:
if语句使用fi结尾,和一般语言使用大括号结尾不同。
[ 条件判断式 ]就是使用test命令进行判断,所以中括号和条件判断式之间必须有空格。
then后面跟符合条件之后执行的程序,可以放在[]之后,用;分割。也可以换行写入,就不需要
;了,比如单分支
if语句还可以这样写:if [ 条件判断式 ] then 程序 fi
示例:
需求:根分区使用率超过80%则报警。
# 1.获取根分区使用率
# 1.1 通过df命令查看Linux系统上的文件系统磁盘使用情况。
# df命令用于显示目前在Linux系统上文件系统磁盘使用情况的统计。
[root@localhost tmp]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 19G 2.1G 16G 12% /
tmpfs 491M 0 491M 0% /dev/shm
/dev/sda1 240M 34M 194M 15% /boot
# 1.2 把根分区的磁盘使用情况提取出来
[root@localhost tmp]# df -h | grep /dev/sda3
/dev/sda3 19G 2.1G 16G 12% /
# 1.3 然后用awk命令,进行列信息提取,提取第五列。
[root@localhost tmp]# df -h | grep /dev/sda3 | awk '{print $5}'
12%
# 1.4 截取前面的数字部分,方便后边判断使用。
# 以%作为分隔符,然后提取1列。
[root@localhost tmp]# df -h | grep /dev/sda3 | awk '{print $5}' | cut -d "%" -f 1
12
# 2.编写Shell程序
# 2.1 创建一个Shell文件if1.sh
[root@localhost tmp]# vim if1.sh
# 编写内容如下:
#!/bin/bash
# 把根分区使用率作为变量值赋予变量rate
# 把上面的命令以命令行的方式先敲一遍,确认能获取到我们需要的内容。
# 如果在Shell里面直接写,会有很大难度。
rate=$( df -h | grep /dev/sda3 | awk '{print $5}' | cut -d "%" -f 1 )
# 判断rate的值如果大于等于80,则执行then后的程序。
# 我们这里为了有演示效果,把输出调整为10.
if [ $rate -ge 10 ]
then
# 打印警告信息。在实际工作中,也可以向管理员发送邮件。
echo "Warning! /dev/sda3 is full !!!"
fi
# 上面的程序表示,如果根分区使用率超过80%则打印`Warning! /dev/sda3 is full !!!``,没有则什么都不做。
# 3. 给if1.sh文件赋予执行权限,并执行该脚本。
[root@localhost tmp]# chmod 755 if1.sh
[root@localhost tmp]# ./if1.sh
Warning! /dev/sda3 is full !!!
2、双分支if条件语句
语法格式:
if [ 条件判断式 ]
then
条件成立时,执行的程序
else
条件不成立时,执行的程序
fi
(1)示例1
我们写一个数据备份的例子,来看看双分支if条件语句。
创建文件if2.sh:
#!/bin/bash
# 需求:备份MySQL数据库
# 1.首先需要同步时间
# 因为我们的服务器上的时间可能会存在误差,
# 我们可以链接ntp时间服务器,来自动更新时间,
# 这样我们服务器上的时间就准确了,
# 下面一行命令是链接到亚洲的ntp时间服务器上,更新时间。
# 目的是保证所有服务器的时间是统一的。
ntpdate asia.pool.ntp.org &>/dev/null
# 提示:你也可以单独写一个脚本,专门用于时间同步。
# &>/dev/null:为把所有输出丢入垃圾箱(不想看到在何输出)
# &>:为无论正确输出还是错误输出,都输出到一个文件中。
# /dev/null类似是一个虚拟设备,或者是当成回收站,
# 任何信息丢进去,就会消失不见。
# 如果有不需要看的命令提示信息,就可以这样处理。
# 这是一个标准写法。
# 2.把当前系统时间按照“年月日”格式赋予变量date
# 默认的时间格式
# [root@localhost tmp]# date
# 2020年 10月 18日 星期日 10:28:27 CST
# 只取年月日,注意+和%之间不能有空格,否则命令会报错。
# [root@localhost tmp]# date +%y%m%d
# 201018
date=$(date +%y%m%d)
# 3.统计mysql数据库的大小,并把结果赋予size变量。
# 该数据主要是一个统计数据,没有多大作用,
# 只是为了写日志,告诉你今天备份的MySQL数据库的大小。
size=$(du -sh /var/1ib/mysql)
# 4.开始备份数据库
# 4.1 判断备份目录是否存在,是否为目录
if [ -d /tmp/dbbak ]
then
# 4.2如果判断为真,执行以下脚本
# dbinfo.txt:数据库备份说明文件,内容就是在某年某月的某一天,备份了多大的数据。
# 把当前日期写入文件
echo "Date:$date!" 〉 /tmp/dbbak/dbinfo.txt
# 把数据库大小写入文件
echo "Data size:$size" >> /tmp/dbbak/dbinfo.txt
# 4.3 进入到备份目录dbbak中
cd /tmp/dbbak
# 4.4 备份数据库
# 把数据库数据和备份说明文件进行打包压缩为mysql-lib-$date.tar.gz
# &>/dev/null:为把所有输出丢入垃圾箱(不想看到在何输出)
tar -zcf mysql-lib-$date.tar.gz /var/lib/mysql dbinfo.txt &>/dev/null
# 4.5 删除备份说明文件
rm -rf /tmp/dbbak/dbinfo.txt
else
# 4.6 如果判断为假,则建立备份目录
mkdir /tmp/dbbak
# 4.7 执行上边4.2到4.5的步骤
# 把日期和数据库大小保存到备份说明文件
echo "Date:$date!" 〉 /tmp/dbbak/dbinfo.txt
echo "Data size:$size" >> /tmp/dbbak/dbinfo.txt
# 压缩备份数据库与备份说明文件
cd /tmp/dbbak
tar -zcf mysql-lib-$date.tar.gz /var/lib/mysql dbinfo.txt &>/dev/null
# 删除备份说明文件
rm -rf /tmp/dbbak/dbinfo.txt
fi
说明:
这个数据库备份的方式不是很合理,主要是在备份数据库的那一行命令,如下:
tar -zcf mysql-lib-$date.tar.gz /var/1ib/mysql dbinfo.txt &>/dev/nul1
不合理的原因有:
- Shell程序中的备份使用压缩包的方式来处理的,把MySQL整个库和一个说明文件打包成一个压缩文件。这种方式是可以解决数据库备份的需求的,但是这种备份的方式,恢复起来会有一些问题。
在数据库恢复的时候,会要求环境(如MySQL的安装位置,MySQL的版本等)必须要和备份时的环境一样,才能够做到数据恢复。 - 这个处理方式只能够实现完全备份,也就是说如果有50G的数据,你备份一次,就要把这50G的数据全部备份一遍。
在实际工作中我们会用其他工具进行数据库的备份,如mysqldump。 - 还有我们之前说过,备份的核心原则是不要把所有鸡蛋放在同一个篮子里。而我们是把原始数据和备份数据放在同一个服务器的同一个硬盘中。那如果这个硬盘坏了,就没有数据可恢复了。
而我们在实际工作中,是通过可以网络备份的服务来处理,我们先按上面的方式进行备份,把数据库备份出来的文件通过网络的方式,发送给其他的服务器。
注意:这只是数据库备份的练习,并不能在工作直接使用,但是思路就是这个思路,这里注意一下。
(2)示例2
在实际工作当中,服务器上的服务经常会宕机,拿apache服务来举例,如果我们对服务器监控不好,就会造成服务器中服务中断了,而管理员却不知道的情况。发现后等到管理员的介入,也会有一定时间的延迟。这时我们就可以写一个脚本来监听本机的服务,如果服务停止或宕机了,可以自动重启这些服务。
我们就以apache服务来举例:
前提,我们通过RPM包的方式安装了apache服务,并启动,如下图:
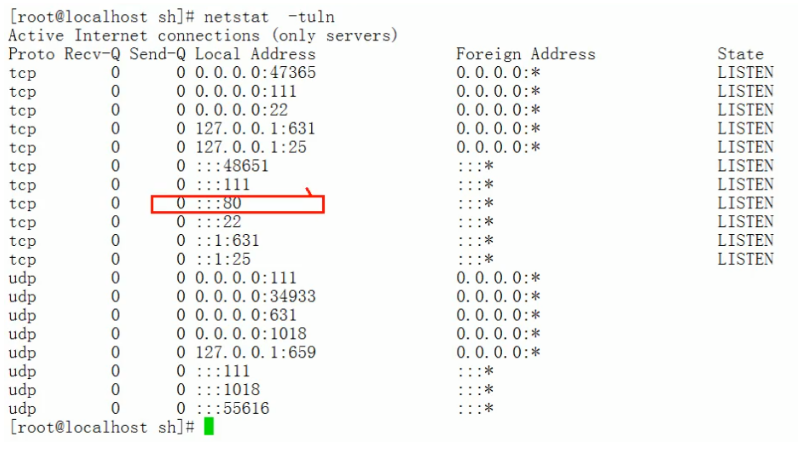
方式一:
分析该脚本该如何实现:
思路:把80端口截取出来,赋值到一个变量中,
判断该变量的值是否为80,是则记录日志,不是则执行启动apache服务。
开始编写:
创建文件if3.sh:
#!/bin/bash
# 判断apache服务是否启动,如果没有启动则自动启动。
# 1.把80端口截取出来,赋值到一个变量中
port=$(netstat -tuln | awk '{print $4}' | grep ":80$")
# 2.判断port变量是否为空
if [ "$port" == "" ]
then
# 为空则证明apache服务没有启动
# 发送邮件
echo "apache httpd is down,must restart!"
# 启动apache服务
/etc/rc.d/init.d/httpd start &>/deb/null
# 这里不建议使用service的方式启动apache服务,
# service启动服务是一种快捷方式,
# 有可能在脚本中会出问题,这里需要注意一下。
else
# 不为空则证明apache服务以启动
# 可以记录日志
echo "apache httpd is ok."
fi
注意:
不能通过
grep "80"命令来过滤数据,因为Shell中的正则表达式是包含匹配,像808、8080等这样的内容,都会被匹配出来。
使用该脚本:
- 执行
chmod 755 if3.sh命令,将if3.sh变成可执行文件。 - 执行
netstat -tuln,查看此时apache服务是否启动。
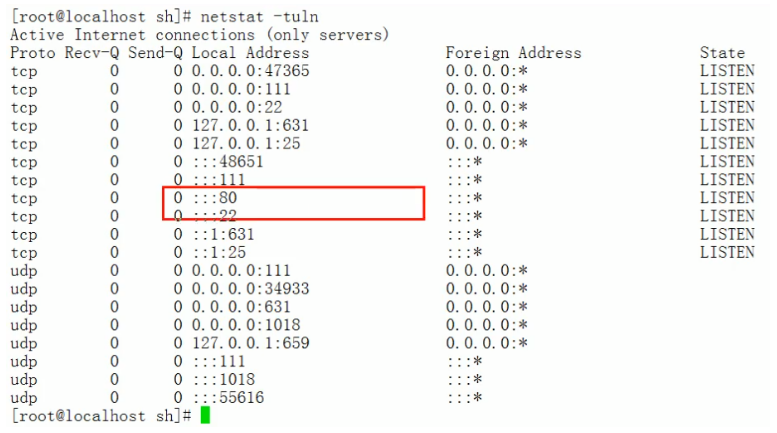
- 执行
./if3.sh命令,执行脚本文件,检查到apache服务是启动状态。

- 此时关掉
apache服务。

再查看一下80端口是否已关闭。
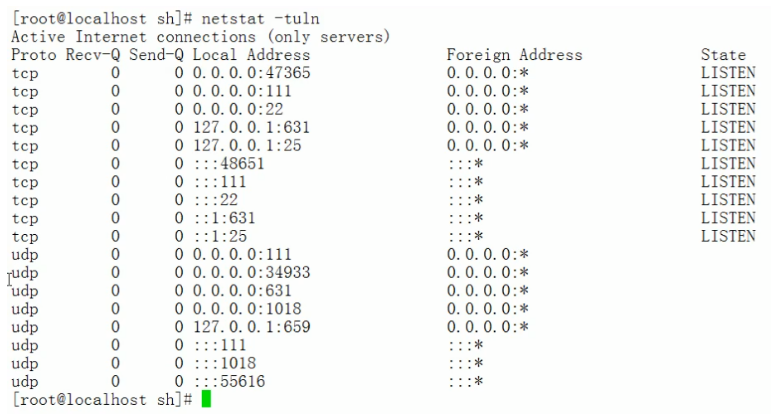
- 然后在执行
if3.sh脚本文件。

可以看到执行if3.sh脚本文件,发现apache服务没有启动,
该脚本会自动启动apache服务。 - 最后我们再查看一下
apache服务是否启动。
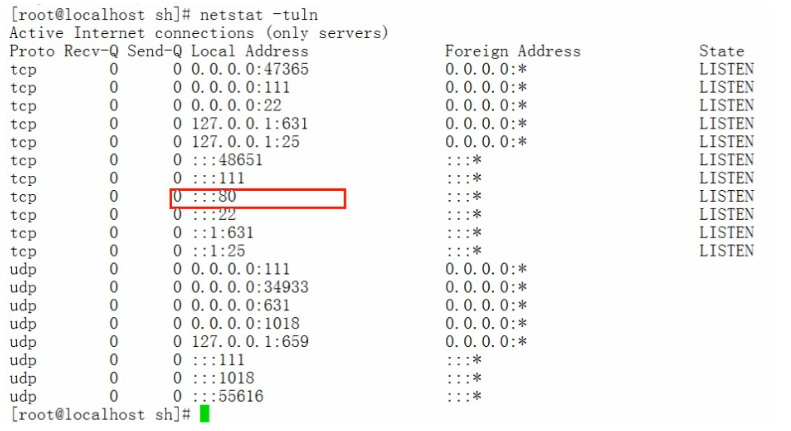
又重新启动了。
提示:
脚本执行过程中,发现服务未启动,会通知管理员,同时也可以通过命令直接把apache服务进行重新启动。而不需要管理员来了,才重启服务。只要管理员接收到通知服务器有问题,过来检查什么原因就可以了。
方式二:
上面实现的方式,基本能够实现检测apache服务的需求。
但是实际工作环境中,可能有种情况,比如apache服务正常,80端口也被开启,但是此时的访问人数过多,把apache服务直接挤爆了。也就是说进程在,端口也在(卡死),但是apache服务已经不应答了。这个时候我们还通过检查80端口的方式,我们是无法发现服务器中apache服务的问题的。
我们先学习一个命令:
nmap命令是端口扫描命令,命令格式如下:
[root@localhost ~]# nmap -sT 域名或 IP
选项:
-s:扫描。
-T:扫描所有开启的TCP端口。
nmap命令的原理是客户端(nmap)给一个服务器所有的端口发送信息,看都有那些端口回复信息,回复了证明该服务器上的端口上的程序正常。
唯一的问题是nmap命令扫描的时间比较长。
如果你的Linux系统中没有安装nmap命令,可以执行命令yum -y install nmap进行安装。
nmap命令来扫描本机的端口,执行结果如下:
[root@localhost tmp]# nmap -sT 192.168.37.128
Starting Nmap 5.51 ( http://nmap.org ) at 2020-10-19 00:18 CST
Nmap scan report for 192.168.37.128 (192.168.37.128)
Host is up (0.0019s latency).
Not shown: 998 closed ports
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http (apache的状态是open)
111/tcp open rpcbind
Nmap done: 1 IP address (1 host up) scanned in 0.16 seconds
知道了nmap命令的用法,我们在脚本中使用的命令就是为了截取http的状态,只要状态是“open”
就证明apache启动正常,否则证明apache服务启动错误。
开始编写脚本:
#!/bin/bash
# 判断apache服务是否启动,如果没有启动则自动启动
# 使用nmap命令扫描服务器,并截取apache服务的状态,赋予变量stat。
# 只有apache服务的进程名叫`http`
# 截取第二列是获取nmap扫描后的端口状态
stat=$(map -sT 192.168.37.128 | grep tcp | grep ssh | awk '{print $2}')
# 如果变量stat的值是“open”
if [ "$port"=="open" ]
then
# 则证明apache服务正常启动,在正常日志中写入一句话即可
echo "$(date) httpd is ok!" >> /tmp/autostart-acc.log
else
# 否则证明apache服务没有启动,自动启动apache服务
/etc/rc.d/init.d/httpd start &>/dev/null
# 并在错误日志中记录自动启动apche服务的时间
echo "$(date) restart httpd!!" >> /tmp/autostart-err.1og
fi
(当然实际工作中处理该类问题有监控服务器来进行监控,以上只是一个练习。)
