『无为则无心』Python函数 — 36、Python中的模块
1、模块介绍
(1)模块概念
Python 模块(Module),就是一个 Python 文件,以.py结尾的文件。文件中包含了 Python 对象定义和Python语句。模块能定义函数,类和变量,模块里也能包含可执行的代码。(模块就相当于Java中的工具类)
- 用直白的话说:模块化指将一个完整的程序分解为一个一个小的模块,通过将模块组合,来搭建出一个完整的程序。
- 换种方式说,不采用模块化,也就是统一将所有的代码编写到一个文件中。采用模块化,就是将程序功能分别编写到不同的文件中。
注意:
- 模块名要符号标识符的规范。
- 可以引入同一个模块多次,但是模块的实例只会创建一个。
import可以在程序的任意位置调用,但是一般情况下,import语句都会统一写在程序的开头。
(2)模块化的优点
- 方便开发,协同工作。
- 方便维护,功能文件清晰。
- 模块可以复用,可控制。
2、导入模块
(1)导入模块的方式
import 模块名from 模块名 import 功能名from 模块名 import *import 模块名 as 别名from 模块名 import 功能名 as 别名
(2)导入方式详解
1)import
- 语法
# 1. 导入模块:模块名就是python文件的名字,注意不要.py。 import 模块名 import 模块名1, 模块名2... # 支持但规范不推荐 # 2. 调用功能 模块名.功能名() - 体验
# 需求:math模块下sqrt() 开平方计算 # 导入模块,math是关于数学运算相关的模块 import math # 开平方 print(math.sqrt(9)) # 3.0
2)from ... import ...
- 语法
from 模块名 import 功能名1, 功能名2, 功能名3... - 体验
# 直接导入模块中的功能 from math import sqrt # 直接使用该功能,不需要书写模块名.功能 print(sqrt(9)) # 3.0
3)from ... import *
- 语法
from 模块名 import * - 体验
# 和上面(2)一样,只不过功能名变成了全部导入 from math import * print(sqrt(9)) # 3.0
该种方式会引入到模块中所有内容,一般不会使用。
因为这种方式引入模块的内容更多,没用到的功能也会一起引入。就相当于把一个模块中的所有内容赋值到当前Python文件中了。
如果遇到重名的方法或者变量的话,会产生覆盖,后边的会覆盖前边的。这个可以查看第4点。
4)as定义别名
为了提高工作效率,原有的模块名或者功能名不方便记忆或使用,我们就可以给模块名或者功能名定义别名。
模块名或者功能名定义了别名后,只能使用别名调用功能。同时应用该种特性可以避免模块中的属性或方法和当前文件中的属性和方法同名而产生的覆盖现象。
- 语法
# 模块定义别名 import 模块名 as 别名 # 功能定义别名 from 模块名 import 功能 as 别名 - 体验
# 需求: 运行后暂停2秒打印hello # 模块别名 import time as tt tt.sleep(2) print('hello') # 功能别名 from time import sleep as sl sl(2) print('hello')
3、制作模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。
自定义模块名必须要符合标识符命名规则。
(1)定义模块
新建一个Python文件,命名为my_module1.py,并定义testA函数。
# 需求:定义一个函数,求两个数的和
def testA(a, b):
print(a + b)
(2)测试模块(__main__变量)
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息.,例如,在my_module1.py文件中添加测试代码。
def testA(a, b):
print(a + b)
testA(1, 1)
此时,无论是当前文件,还是其他已经导入了该模块的文件,在运行的时候都会自动执行testA函数的调用。
解决办法如下:
def testA(a, b):
print(a + b)
# 只在当前文件中调用该函数,才执行的测试代码
# 也就是说这部分测试代码代码,只要当前文件作为主模块的运行时候才需要执行的代码
# 而当模块被其他模块引入时,是不需要执行的,
# 此时我们就必须要检查当前模块是否是主模块,如执行if __name__ == '__main__':
if __name__ == '__main__':
testA(1, 1)
说明:
在每一个模块内部都有一个__name__属性,__name__属性是一个系统变量,是模块的标识符。
通过这个属性可以获取到模块的名字。
如果__name__使用在Python文件自身模块文件中,__name__的值就为'__main__',又称之为主模块。
如果__name__不是在自身文件中被调用,则__name__的值为所在模块文件的真实文件名。
可以是用print(__name__)查看__name__的值。
在导入模块的文件中直接执行文件即可查看,不需要写任何代码,因为已经写在导入的模块文件中了。
(3)调用模块
# 导入自定义模块
import my_module1
# 调用模块中的功能
my_module1.testA(1, 1)
(4)注意事项
注意1
如果使用from ... import ...或from ... import *导入多个模块的时候,且模块内有同名功能。当调用这个同名功能的时候,调用到的是后面导入的模块的功能。
体验:
# 模块my_module1代码
def my_test(a, b):
print(a + b)
# 模块my_module2代码
def my_test(a, b):
print(a - b)
# 导入模块和调用功能代码
from my_module1 import my_test
from my_module2 import my_test
# my_test函数是模块2中的函数
my_test(1, 1)
注意2
在模块中在一个变量前添加了一个_,这个变量只能在模块内部访问,在通过import *引入时,不会引入_开头的变量。
# 模块my_module1代码
_c = 30
from my_module1 import *
print(_c) # 报错未定义
print(c) # 报错未定义
4、模块定位顺序
当导入一个模块,Python解析器对模块位置的搜索顺序是:
- 当前目录(就是当前Python文件所在的文件夹)
- 如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为
/usr/local/lib/python/。
模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
# sys.path
# 他是一个列表,列表中保存的是模块的搜索路径,这些路径我们不要随便去动
# ['C:\\Users\\lilichao\\Desktop\\resource\\course\\lesson_06\\code',
# 'C:\\dev\\python\\python36\\python36.zip',
# 'C:\\dev\\python\\python36\\DLLs',
# 'C:\\dev\\python\\python36\\lib',
# 'C:\\dev\\python\\python36',
# 'C:\\dev\\python\\python36\\lib\\site-packages']
# pprint.pprint(sys.path)
注意:
- 自己的文件名不要和已有模块名重复,否则导致原有的模块功能无法使用。
原因:Python解析器对模块位置的搜索顺序是由近及远。 - 使用
from 模块名 import 功能的时候,如果功能名字重复,调用到的是最后定义或导入的功能。- 也就是第三行和第四行导入的模块重名,则算第四行导入的。
- 如果导入的模块中的功能和文件中定义的方法重名,也是谁在后,算谁的,前者被覆盖。
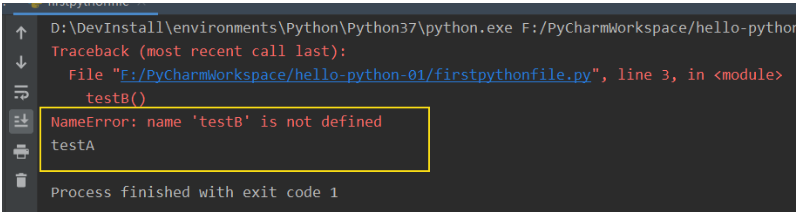
5、__all__
如果一个模块文件中有__all__变量,当使用from xxx import *导入时,只能导入这个列表中的元素(就是在这个列表里的功能)。
my_module1模块代码
__all__ = ['testA']
def testA():
print('testA')
def testB():
print('testB')
导入模块的文件代码
from my_module1 import *
testA()
testB()
输出结果: