Mysql的执行流程详解与主从同步原理
一. 介绍文章目录:
整篇文章将从以下四块进行讲解:
(1)Mysql的执行SQL的流程
(2)InnoDB的存储引擎的架构设计
(3)Mysql的Binlog日志
(4)Mysql的主从同步原理
二. Mysql的执行流程:
对于Mysql来说我们通常都会有多线程来连接Mysql,然后对于后台数据库进行增删改查的操作,因此对于一个发布在服务器上的项目来说,对于Mysql连接应该采用的是数据库连接池来完成,避免每一个用户来都产生新的连接从而导致性能下降。所以常规的sql执行流程如下图所示:
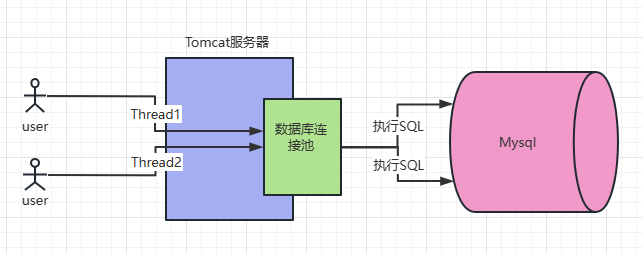
此时Mysql为了实时处理用户发送过来的网络请求,会专门分配一个监听器线程对于网络请求进行监听,并从网络连接请求当中读取与解析一条发送过来的sql语句。
那么此时问题就来了,到底是如何执行一条SQL语句的呐?
1)SQL接口:
Mysql内部会提供一个接口组件也就是SQL接口,在监听线程监听到有对应的客户发送响应的数据以后,会优先被SQL接口获取到
2)SQL查询解析器:
Mysql中会根据语法分析器以及词法分析器,等众多的解析器对于Mysql的SQL语句进行解析
3)SQL查询优化器:
注意Mysql通过解析器解析完SQL语句之后会知道到底如何执行该SQL,此时他并不会直接交付给执行器进行执行,中间会夹杂一步叫作SQL查询优化器,这个优化器是用来优化SQL语句,使得SQL语句的执行效率更加高,我们给定一个例子来看:
select id,username from user where id = 1;
此条SQL语句会被划分成为好多种解析的方式,例如其中的两种:
- 第一种:首先查询出所有的user表的信息,保留id和username然后再在这整个表中获取到id=1的用户信息
- 第二种:首先查询id=1的用户,然后将id=1用户的id和username1给查询出来
我们很容易就会发现其实第二种的查询方案会更加的优化,查询的效率更高。
经过以上几步我们会得到SQL执行流程的几个重要步骤,接下来用图进行梳理一下:
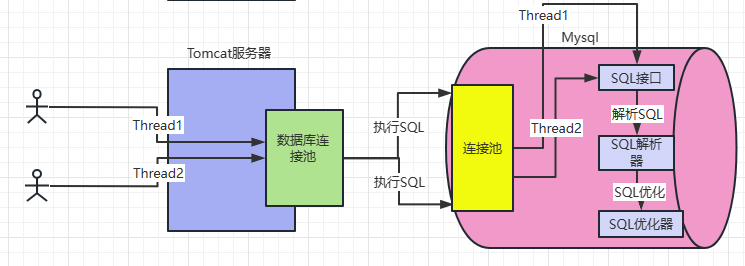
注意对于Mysql来说其本身也是编程语言所开发,因此整个程序的数据加载流程要么是在内存中要么是在磁盘文件当中,因此此时我们就需要介绍Mysql又一重要的概念就是存储引擎
,我们将它单独拿出一节来讲:
三. InnoDB的存储引擎的架构设计:
3.1 执行器:
在介绍InnoDB存储引擎之前我们需要了解执行器的概念。在Mysql中执行完SQL的查询优化器之后会通过一个组件来调用存储引擎,这就是执行器。执行器会根据优化器选择的执行方案去调用存储引擎的接口按照一定的顺序和步骤把SQL语句执行。
3.2 InnoDb存储引擎的架构设计:
这其中会涉及到日志相关的操作,因此我们以一条实际的案例出发来介绍:
update users set age = 26 where id = 26;
首先以图示来介绍粗略的执行流程:
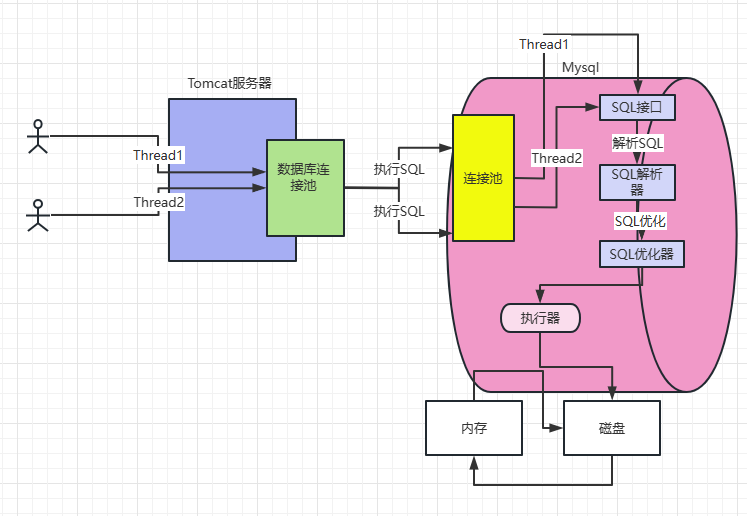
3.2.1 InnoDB重要的内存结构,缓冲池:
今天第一个闪亮登场的重要组件是:缓冲池(Buffer Pool)。缓冲池是InnoDB存储引擎中放在内存里的一个组件,这里面会缓存很多的数据,以便于以后在查询的时候,如果内存缓冲池里有数据,就可以不用去查磁盘了,以减少对于磁盘IO的操作,因为我们知道磁盘IO是很耗性能的操作。
因此当我们执行上一个案例的SQL的update操作时,我们并不是直接进行的磁盘IO操作的,而是先查看这条操作的数据是否在缓冲池当中,如果不在话就会到磁盘当中加载对应的数据到内存的缓冲池里面来,并且对于这行记录的update操作我们会加上独占锁。
3.2.2 Mysql中的undolog日志:
对于事务来说,事务的执行有成功通时也有失败。而失败时候数据会产生回滚的操作,我们需要将数据回滚到原始的位置,因此我们就需要有一个东西来记录原始的数据,此时就是undolog:
我们来看一下内存的主要结构:
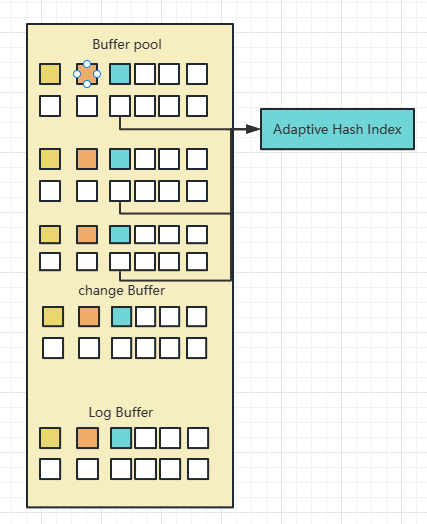
我们需要考虑我们可能要回滚数据的旧值,因此我们将旧值写入到undolog日志当中,此时的undolog存储于内存当中。
3.2.3 更新buffer pool中的缓存数据:
此时我们将缓存当中的数据进行更新,这是更新完的数据叫作脏数据,因为缓存的数据与内存中还不一致。
3.2.4 redolog日志:
注意为了避免数据库中缓存与内存数据不一致的情况,我们引入了redolog日志,所谓的redolog日志就是记录下你对于哪一行数据做了响应的操作。 此时就会分成以下两种情况
(1)事务未提交,Mysql数据库崩溃了
我们都知道,InnoDB存储引擎是支持事务的,其实在数据库中,哪怕执行一条SQL语句,其实也可以是一个独立的事务,只有当我们提交事务之后,SQL语句才算执行结束。
到目前为止,我们仅是将新数据写入redo日志中,其实还没有提交事务,那么如果此时MySQL崩溃,必然导致内存里Buffer Pool中的修改过的数据都丢失,同时你写入Redo Log Buffer中的redo日志也会丢失,但是回想一下此时丢失重要吗?其实是不要紧的,因为你一条更新语句,没提交事务,就代表没执行成功,仍然是保持着数据的一致性。因为此时MySQL宕机虽然导致内存里的数据都丢失了,但是你会发现,磁盘上的数据依然还停留在原样子。
(2)提交事务将redolog写回磁盘当中保证数据一致性:
此时提交事务就是要把redo日志从redo log buffer里刷入到磁盘文件当中去,注意从内存数据写回到磁盘当中时候并不是直接写入,而是写写入磁盘文件系统的缓存当中,在刷入磁盘,这就会引入刷盘时机的概念,有以下几种刷盘策略:
innodb_flush_log_at_trx_commit=0
表示每隔一秒把redo log buffer刷到磁盘文件系统中(os cache)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。
innodb_flush_log_at_trx_commit=1
表示在每次事务提交的时候,都会把redo log buffer刷到磁盘文件系统中(os cache)去,并立刻调用文件系统的“flush”操作将缓存刷新到磁盘上去。
innodb_flush_log_at_trx_commit=2
表示在每次事务提交的时候会把redo log buffer刷到磁盘文件系统中(os cache)去,但并不会立即刷写到磁盘,每隔1s 将os cache中的数据刷新到磁盘。
(3)当事务提交之后可能处于一个状态,Buffer pool与redo日志中都是更新后的新值,而磁盘是旧值,此时mysql崩溃会丢失数据吗?
答案是不会,因为在mysql重启之后可以根据redo日志恢复之前所做的修改。
四. Mysql的binlog:
4.1 Mysql binlog简介:
- 实际上我们之前说的redo log,是一种偏向物理性质的重做日志,因为他里面记录的是类似这样的东西,“对哪个数据页中的什么记录,做了个什么修改”。而且redo log本身是属于InnoDB存储引擎独有的一个东西
- 而binlog叫做归档日志,里面记录的是偏向于逻辑性的日志,类似于“对users表中的id=2的这一行数据做了更新操作,更新以后的值是什么”。binlog不是InnoDB存储引擎特有的日志文件,是属于mysql server自己的日志文件
4.2 Mysql binlog作用:
- 利用binlog日志恢复数据库数据
- 主从架构当中通过binlog进行数据的同步操作
- 可以利用binlog中信息进行审计
4.3 binlog也会参与事务的整个流程:
接着上一讲讲到,在我们提交事务的时候,会把redo log日志写入磁盘文件中去。但是其实在提交事务的时候,我们同时还会把这次更新对应的binlog日志写入到磁盘文件中去。例如下图会介绍粗略的流程:
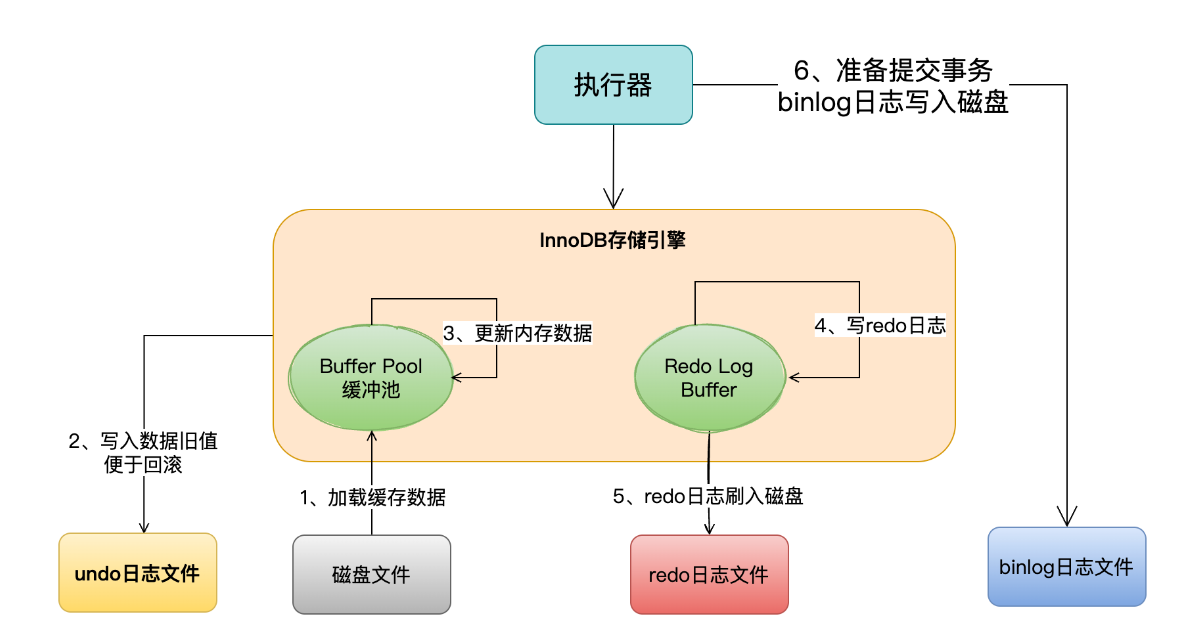
注意Mysql内部的执行器其实干的事特别的多:
1.会负责跟InnoDb进行交互,将磁盘文件加载进BUffer pool当中
2.写入undolog日志,更新Buffer pool里的数据
3.写入redo日志
4.写binlog
其实对于上述图中的1,2,3,4是执行语句时候干的事情,而5,6就是提交事务时候干的事情了。
4.4 binlog与redolog结合完成事务的提交:
当我们把binlog写入磁盘文件之后,接着就会完成最终的事务提交,此时会把本次更新对应的binlog文件名称和这次更新的binlog日志在文件里的位置,都写入到redo log日志文件里去,同时在redo log日志文件里写入一个commit标记。
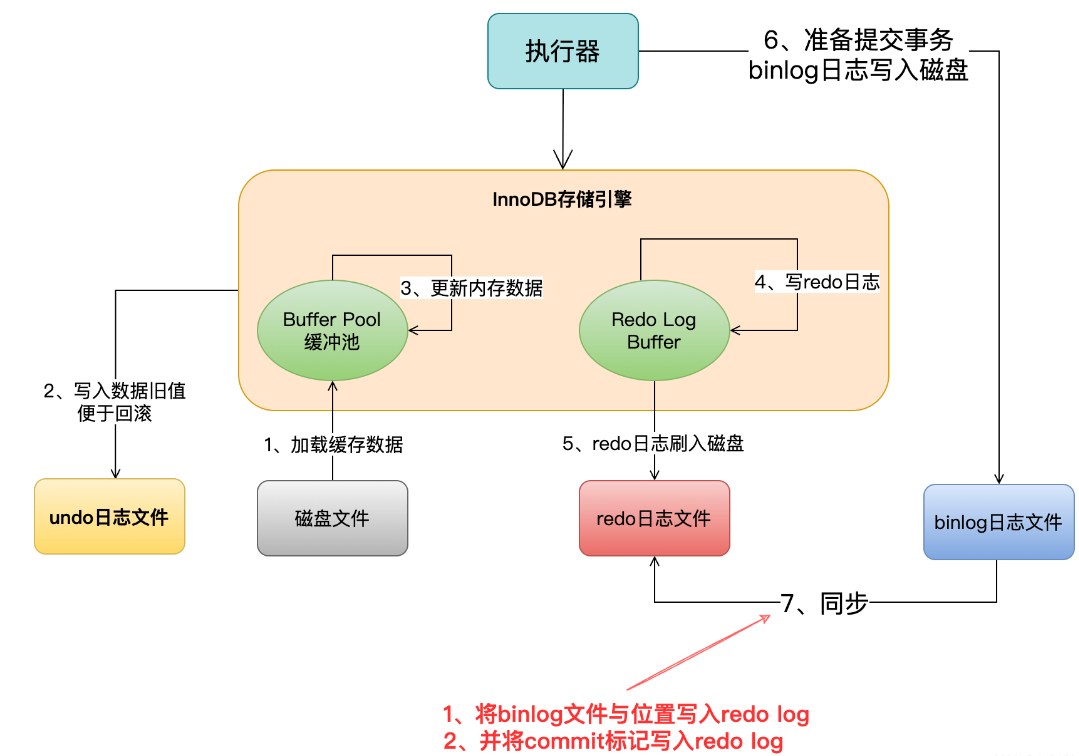
有同学会疑问为什么要在最后加入commit标识,有什么作用?不加行不行?
我们来举个例子,假设我们在提交事务的时候,一共有上图中的5、6、7三个步骤,必须是三个步骤都执行完毕,才算是提交了事务。那么在我们刚完成步骤5的时候,也就是redo log刚刷入磁盘文件的时候,mysql宕机了,此时怎么办?
这个时候因为没有最终的事务commit标记在redo日志里,所以此次事务可以判定为不成功。不会说redo日志文件里有这次更新的日志,但是binlog日志文件里没有这次更新的日志,不会出现数据不一致的问题。
如果要是完成步骤6的时候,也就是binlog写入磁盘了,此时mysql宕机了,怎么办?
同理,因为没有redo log中的最终commit标记,因此此时事务提交也是失败的。
必须是在redo log中写入最终的事务commit标记了,然后此时事务提交成功,而且redo log里有本次更新对应的日志,binlog里也有本次更新对应的日志 ,redo log和binlog完全是一致的。
4.5 最后就是使用后台IO线程随即将内存更新后的脏数据刷回磁盘。
4.6 介绍以下binlog几种类型:
为最后一节的主从复制原理做准备
(1)statement:会将对数据库操作的sql语句写入到binlog中。
(2)row:会将每一条数据的变化写入到binlog中。
(3)mixed:statement与row的混合。Mysql决定什么时候写statement格式的,什么时候写row格式
的binlog。
五.Mysql主从复制的原理:
(1)master上的写操作:
当master上的数据发生改变的时候,该事件(insert、update、delete)变化会按照顺序写入到binlog中。
(2)binlog dump线程:
当slave连接到master的时候,master机器会为slave开启binlog dump线程。当master 的 binlog发生变化的时候,binlog dump线程会通知slave,并将相应的binlog内容发送给slave。
(3)在slave机器上的操作:
当主从同步开启的时候,slave上会创建2个线程:
- I/O线程。该线程连接到master机器,master机器上的binlog dump线程会将binlog的内容发送给该I/O线程。该I/O线程接收到binlog内容后,再将内容写入到本地的relay log。
- SQL线程。该线程读取I/O线程写入的relay log。并且根据relay log的内容对slave数据库做相应的操作。
主要参考博客:https://blog.csdn.net/zht245648124/article/details/126907307



