1.Pandas数据结构
- Series :是一种类似于一维数组的对象,由一组数据以及一组与之相关的数据标签(即索引)组成。
- DataFrame :是一个表格型的数据结构,既有行索引又有列索引的一种数据结构.
2.外部导入数据
格式 :
pd.read_excel(r"D:\Data-Science\share\data\pandas_train.xlsx",encoding = "gbk",engine='python',sep = " ")
导入SQL :
import pymysql
sql_cmd = "SELECT * FROM memberinfo"
db = pymysql.connect(host = "X.X.X.X",
user = "XXX",
password = "*******",
db = "XXX" ,
charset = "utf8")
# host:数据库地址/本机使用localhost
# user:用户名
# password:密码
# db:数据库名
# charset:数据库编码,一般为UTF-8
#注:如果用户名或密码中包含特殊符号@、%等符号时,需要修改密码方可链接
df = pd.read_sql(sql_cmd, db)
总结:
同样数量的数据,导入excel格式是导入csv格式的10倍,所以尽量将表转为csv以后进行处理
3.数据熟悉
|
head(N)
|
输出前N行 , 默认5行
|
|
shape
|
输出(行数, 列数)
|
|
info()
|
输出表相关信息
|
|
describe()
|
输出数值型数据的count,中位数,min,max,mean等
|
4.数据预处理
4.1.删除缺失值
dropna() 默认删除含有缺失值得行
参数:
how="all" 删除全为缺失值的行
4.2.填充缺失值
fillna()
#fillna()和dropna()默认会返回一个替换后的新对象,不改变源数据,这个时候将替换后的数据赋值给新的表,如果要改变源数据,通过传入inplace=True进行更改
# 以字典的形式指明要填充的列名
5.重复值处理
对于重复值我们一般是进行删除处理,使用的方法是drop_duplicates()
#subset表示按哪列/几列进行去重
#keep=first表示保留保留第一个,=last表示保留最后一个,=False表示删除所有重复值,默认是first
#inplace表示是否更改源数据
6.异常值处理
- 最常用的处理方式就是删除。
- 把异常值当作缺失值来填充。
- 把异常值当作特殊情况,研究异常值出现的原因。
|
类型
|
说明
|
|
int
|
整型数,即整数
|
|
float
|
浮点数,即含有小数点
|
|
object
|
python对象类型,用O表示
|
|
string_
|
字符串类型,经常用S表示,S10表示长度为10的字符串
|
|
unicode_
|
固定长度的unicode类型,跟字符串定义方式一样,经常用U表示
|
7 索引设置
7.1 为无索引表设置索引
df.columns = ["技能","周数"]
df.index = ['第一', '第二', '第三', '第四']
7.2 重新设置索引
#设置单一索引
df112.set_index("用户编号").head()
#设置层次化索引
df64=df112.set_index(["家庭成员","好坏客户"])
7.3 重命名索引
#利用rename的方法对行/列名进行重命名
columns={"用户编号":"用户编号-测试",
"好坏客户":"好坏客户-测试"}
index={0:"zero",
1:"one"}
df112.rename(columns=columns,index=index).head()
7.4 重置索引
reset_index(level=None, drop=False, inplace=False)
level 参数用来指定要将层次化索引的第几级别转化为 columns,第一个索引为 0 级,第二个索引为 1 级,默认为全部索引,即默认把索引全部转化为 columns。
drop参数用来指定是否将原索引删掉,即不作为一个新的columns,默认为False, 即不删除原索引。
inplace 参数用来指定是否修改原数据表。
8 数据选择
普通索引: 通过传入列名选择数据. (行和列有区别 , 行用到loc)
位置索引: iloc 方法
8.1 列选择
#获取某一列,其实就是一个Series
df["家庭成员"].head()
#获取特定的某几列
df[["用户编号","年龄"]].head()
# 选择某几列,如第一列和第三列
df.iloc[:,[0,2]].head()
# 选择连续的某几列,如第一列到第三列
df.iloc[:,[0:2]].head()
8.2 行选择
# 选择某行/某几行
df521.loc[["零","二"]]
#利用位置索引第一行和第三行
df521.iloc[[0,2]]
#利用位置索引第一行到第三行
df521.iloc[0:2]
8.2.1筛选满足条件的行
df112[(df112["用户编号"]>10)|(df112["年龄"]<25)]
8.3 列行同时选择
df[df["QADays"]<5]["GoodsID"]
df521.loc[["零","一"],["用户编号","年龄"]]
df521.iloc[[0,1],[0,2]]
df112[df112["用户编号"]<5][["用户编号","年龄"]]
df521.iloc[0:2,0:3]
#交叉索引用到ix
df521.ix[0:3,["用户编号","年龄"]]
9.数值操作
9.1 数值替换replace()
#针对全表一对一进行替换
import numpy as np
df112.replace(np.NaN,0).head()
#针对全表多对一进行替换
df112.replace([0,1],"替换值").head()
#针对全表多对多替换
df112.replace({1:"是",0:"否"}).head()
#针对某列进行替换,且不更改源数据 ,参数inplace = True/False
df112["好坏客户"].replace({1:"是",0:"否"},inplace=False).head()
9.2数值排序sort_values()
#按某列进行升序, 默认升序即 ascending = True , 按照某一列 by=["年龄"]
#缺失值默认放在后面 , 可改为前面即: na_position="first"
df112.sort_values(by=["年龄"]).head()
#按某几列进行升序排列
#先按第一列进行升序,如果第二列有重复值,则再按第二列进行降序
df112.sort_values(by=["用户编号","年龄"],ascending=[True,False]).head()
9.3数值排名rank()
|
method
|
说明
|
|
"average"
|
这种处理方式与Excel中RANK.AVG一致
|
|
"first"
|
按值在所有的待排列数据中出现的先后顺序排名
|
|
"min"
|
这种处理方式与Excel中RANK.EQ一致
|
|
"max"
|
与min相对应,取重复值对应的最大排名
|
rank(ascending,method)
#默认 method = average
df["成交量"].rank()
9.4 数值删除drop()
#删除一列/多列
df112.drop(columns=["用户编号","年龄"]).head()
#删除一列/多列,对于直接传入列名需要 传入参数axis=1 , 而0表示删除行
df112.drop(["用户编号","年龄"],axis=1).head()
#同样需要传入inplace=True才可以改变原始数据
#根据行索引删除行
df112.drop([0,1],axis=0).head()
df112.drop(df112.index[[0,1]]).head()
9.5数值计数value_counts()
#各类别占比 normalize = True
df112["好坏客户"].value_counts(normalize = True)
9.6唯一值获取unique()
df112["年龄"].unique()
9.7数值查找isin()
df112["好坏客户"].isin([0,1])
9.8区间切分cut() 和 qcut()
#自定义切分
bins=[0,100,1000,10000,150000]
pd.cut(df112["用户编号"],bins).unique()
#等量切分 如5等分
pd.qcut(df112["用户编号"],5).unique()
9.9 插入新的行或列insert()
df112.insert(3,"插入-测试",data)#表示在第4列插入一列名为"插入-测试"的数据data
#方法二,在最后一列后面插入一列
df112["新插入一列"] = data
9.10行列互换 T
#转置
df12.T.T
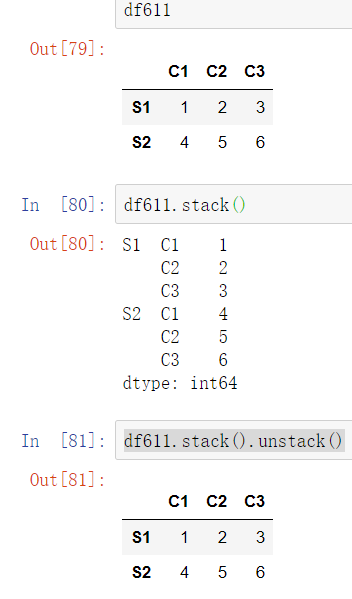
9.11索引重塑stack()
![]()
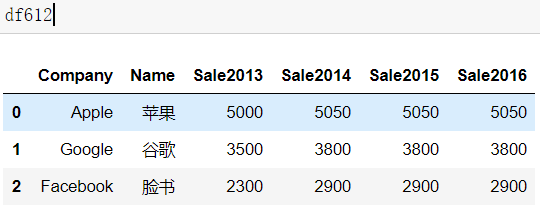
9.12长宽表转换
![]()
>>df612.melt(id_vars = ["Company","Name"],
var_name = "Year",
value_name = "Sale")
-----------------------
Company Name Year Sale
0 Apple 苹果 Sale2013 5000
1 Google 谷歌 Sale2013 3500
2 Facebook 脸书 Sale2013 2300
3 Apple 苹果 Sale2014 5050
4 Google 谷歌 Sale2014 3800
5 Facebook 脸书 Sale2014 2900
6 Apple 苹果 Sale2015 5050
7 Google 谷歌 Sale2015 3800
8 Facebook 脸书 Sale2015 2900
9 Apple 苹果 Sale2016 5050
10 Google 谷歌 Sale2016 3800
11 Facebook 脸书 Sale2016 2900
id_vars 参数用于指明宽表转换到长表时保持不变的列,
var_name 参数示原来的列索引转化为“行索引”以后对应的列名,
value_name 表示新索引对应的值的列名。
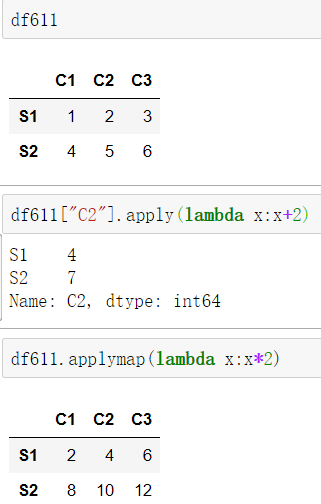
9.13 apply()和applymap() 函数
df611.applymap(lambda x:x*2)
df611["C2"].apply(lambda x:x+2)
![]()
10 数据运算
10.1 算术运算
+ - * /
10.2 比较运算
< > = !=
10.3 汇总运算
|
函数
|
说明
|
|
count
|
非NA值得数量
|
|
mean
|
平均值
|
|
sum
|
求和
|
|
max
|
求最大值
|
|
min
|
求最小值
|
|
median
|
中位数
|
|
mode
|
求众数
|
|
var
|
方差
|
|
std
|
标准差
|
|
quantile
|
求分位数
|
|
corr
|
相关系数
|
#两变量的相关系数
df112["年龄"].corr(df112["月收入"])
out : 0.03771565421103959
#相关系数矩阵
df112.corr()
11时间函数
11.1 datetime和time的区别
time是基于系统层面的一些操作,datetime 基于time进行了封装,提供了更多实用的函数。
11.2 datetime
>>from datetime import datetime
>>now = datetime.now()
#时间元组
out : datetime.datetime(2019, 8, 12, 19, 57, 31, 214668)
# 年,月,日,星期
>> now.year now.month now.day now.weekday()
# 日期的年份、全年的周数、本周第几天:(2019, 33, 1)
>> now.isocalendar()
11.3 time
>>import time
#获取时间长格式
>>time.localtime()
out: time.struct_time(tm_year=2019, tm_mon=8, tm_mday=12, tm_hour=20, tm_min=6, tm_sec=46, tm_wday=0, tm_yday=224, tm_isdst=0)
#时间戳
>>time.time()
out: 1565611051.3792284
11.7 格式化时间
strptime()是将时间格式的时间转化为某些自定义的格式,具体的格式有以下:
#字符串转为time
s_time = '2019-01-03 08:57:21'
time.strptime(s_time,"%Y-%m-%d %H:%M:%S")
#字符串转为datetime
datetime.strptime(s_time,"%Y-%m-%d %H:%M:%S")
|
代码
|
说明
|
|
%H
|
小时(24小时制)[00,23]
|
|
%I
|
小时(12小时)[01,12]
|
|
%M
|
2位数的分[00,59]
|
|
%S
|
秒[00,61]
|
|
%w
|
用整数表示星期几,从0开始
|
|
%U
|
每年的第几周,周日被认为是每周第一天
|
|
%W
|
每年的第几周,周一被认为是每周第一天
|
|
%F
|
%Y-%m-%d的简写形式,例如2018-04-18
|
|
%D
|
%m/%d/%y的简写形式,例如04/18/2018
|
strftime是将时间格式的时间转化为某些自定义的格式,具体的格式有以下:
#time转化为字符串
time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
#datetime转化为字符串
datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
代码
|
说明
|
|
%H
|
小时(24小时制)[00,23]
|
|
%I
|
小时(12小时)[01,12]
|
|
%M
|
2位数的分[00,59]
|
|
%S
|
秒[00,61]
|
|
%w
|
用整数表示星期几,从0开始
|
|
%U
|
每年的第几周,周日被认为是每周第一天
|
|
%W
|
每年的第几周,周一被认为是每周第一天
|
|
%F
|
%Y-%m-%d的简写形式,例如2018-04-18
|
|
%D
|
%m/%d/%y的简写形式,例如04/18/2018
|
11.4 时间索引
import pandas as pd
import numpy as np
index = pd.DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04', '2018-01-05', '2018-02-06', '2018-02-07', '2018-02-08',
'2018-02-09', '2018-02-10'])
data = pd.DataFrame(np.arange(1,11),columns = ["num"],index = index)
#时间索引pandas.datatimeindex()用处
#获取2018年的数据
data["2018"]
#获取2018年1月1到1月3的数据
data["2018-01-01":"2018-01-03"]
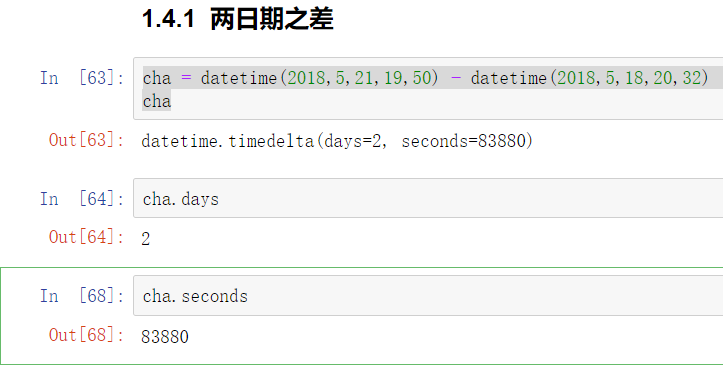
11.5 日期之差
![]()
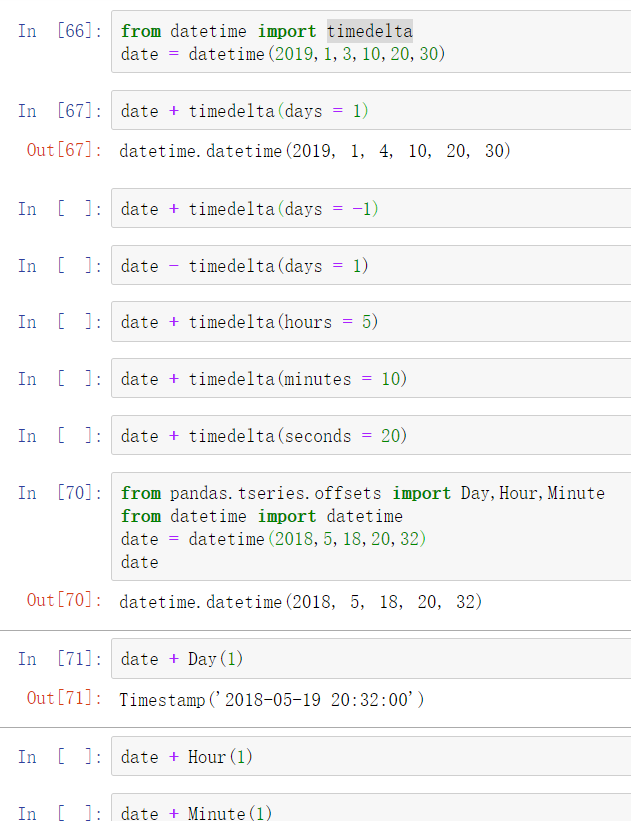
11.6 时间偏移
12 数据分组/透视
12.1 分组键时列名
# 分组键是多个列
groupby(["区域","客户分类"])
#获取某列的分组结果
df2.groupby(["区域","是否省会"])["7月销量"].sum()
12.2 aggregate方法
除了常规的加减乘除计数之外,还可以自定义函数,并通过aggregate或agg方法传入即可。
#不同列做不同的聚合运算
df2.groupby("客户分类").aggregate({"用户ID":"count","7月销量":"sum","8月销量":"sum"})
#针对相同的列做不同的聚合运算
df2.groupby(["区域"])["7月销量"].aggregate(["count","sum"])
#该函数是针对每个分组内的数进行计算的
def zidingyi(arr):
return arr.sum()
df2.groupby(["区域","是否省会"])["7月销量"].agg(zidingyi)
#参数: 以无索引形式返回聚合数据
as_index=False
12.3 数据透视表 pivot_table()
pd.pivot_table(data,values=["7月销量","8月销量"],index=["区域","客户分类"],columns="是否省会",aggfunc="sum", fill_value=0,margins=True,margins_name="总计")
参数:
-
- 缺失值填充: fill_value 默认为Nan
- 合计: margins 默认关闭
- 合计名: margins_name
13 多表联结
13.1 横向联结(列联结)
merge(table1,table2,...)
参数:
-
- on # 用on来指定连接键 ,默认以公共列
- how # 联结方式 inner outer right left
- suffixes #重复列名处理
13.2 纵向联结(行联结)
concat()
参数:
-
- ignore_index #忽略索引
- drop_duplicates() #重置数据处理
14 结果导出
14.1 Excel单个sheet
#无穷值处理
df2.to_excel(excel_writer = r"D:\Data-Science\share\data\测试文档.xlsx",sheet_name = "这是sheet名",index = False,columns = ["学号","班级"],encoding = "utf-8",na_rep = 0,inf_rep = 0)
参数:
-
- na_rep #缺失值处理
- inf_rep #无穷值处理
14.2 Excel多个sheet
#声明一个读写对象
#excelpath为文件要存放的路径
excelpath = "D:/Data-Science/share/data/多文件报表.xlsx"
writer = pd.ExcelWriter(excelpath,engine = "xlsxwriter")
df1 = t2.reset_index()
df2 = t1.reset_index()
df3 = t11.reset_index()
#分别将表df1、df2、df3写入excel中的sheet1、sheet2、sheet3
#并命名为表1、表2、表3
df1.to_excel(writer,sheet_name = "表1")
df2.to_excel(writer,sheet_name = "表2")
df3.to_excel(writer,sheet_name = "表3")
#保存读写的内容
writer.sav
14.3 导出 CVS
#设置分割符,多列, 编码, 设置索引
df2.to_csv(r"D:\Data-Science\share\data\测试.csv",index = False,columns = ["学号","班级"],encoding = "gbk",sep = ",")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号