
NLP(十一):sentence_BERT
一、引言
https://zhuanlan.zhihu.com/p/351678987
在自然语言处理NLP中,文本分类、聚类、表示学习、向量化、语义相似度或者说是文本相似度等等都有非常重要的应用价值。这些任务都是为了能从复杂的文本中,通过采用ML/DL的方法,学习到本文深层次的语义表示,从而更好地服务于下游任务(分类、聚类、相似度等)。这里笔者将这些统一概括为智能语义计算。
二、具体应用场景
- 文本语义向量化:文本语义嵌入,通过D L模型的学习,将文本隐含语义由数字向量表示出来,提供给其他任务进行训练或计算。
- 语义相似度:如智能客服回答,客户的一个新问题是否与已知问题在语义空间上相似或接近,是否能够用已知问题的答案,对客户进行回复。
- 文本聚类:如一批无标签的文本进行归类。
- 文本复述:给定一个文本查找与它表述相同的版本,例如简化句子的表述。
- 双文本挖掘:在语料库中查找平行句子对的过程,例如翻译。
- 语义搜索:寻找语义相似相近的文本。
- 语义检索并排序:寻找语义相近的前K个文本(召回),并对这K个文本再进行语义相似度排序。
- 双文本评分及分类:通过模型计算一对文本的评分(文档与摘要是否匹配、不同语言翻译是否正确)或分类。
本文我们将主要关注于语义相似度Semantic Textual Similarity这个子任务,对比相关模型,并在有应用价值的数据上进行实验。
三、双塔SBERT模型的介绍
塔式结构在深度学习模型中是比较常见的,比较著名的是微软的DSSM(Deep Structured Semantic Models )基于深度网络的语义模型,其结构如下。
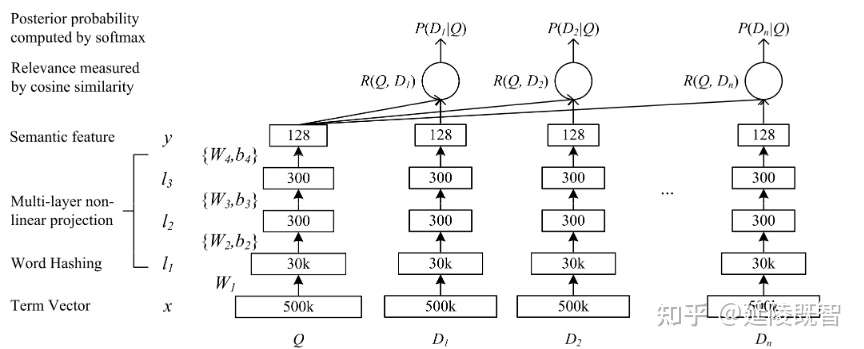
我对dssm模型的理解,该模型通过一层一层堆叠的网络提取隐含语义。通过semantic特征向量(128维)的两两余弦计算,得到各文本之间的相似度R(q, d)。最后优化相似度与样本的距离。其中128维的semantic feature,即为通过该模型学习到的对应文本的隐含语义。
而SBert与dssm思想上比较类似,都是通过独立的子模块进行高维信息抽取,通过各文本特征向量的余弦距离,来表征文本语义相似度。 Bert(Bidirectional Encoder Representation from Transformers)及其变种在NLP中大杀四方,不多介绍了。sbert结构图如下。
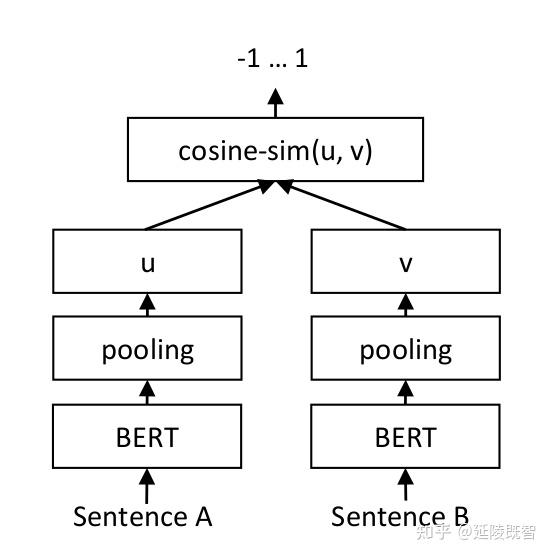 SBERT模型结构图
SBERT模型结构图
semantic feature(上图的U、V)在实际生产上非常有意义,它能够预先通过sbert计算得到。然后,通过向量搜索引擎处理这些向量,检索到最相似语义的文本。这种方式能非常快速实现海量相似文本的查询、排序,而无需再进行高延迟的模型预测。类似的,推荐系统也是预先学习到用户、商品的表征向量,从而进行召回、排序、推荐等任务。
四、模型实验
采用sentence-transformer库进行模型搭建与实验。该框架提供了一种简便的方法来计算句子和段落的向量表示(也称为句子嵌入)。这些模型基于诸如BERT / RoBERTa / XLM-RoBERTa等模型,并且经过专门调整以优化向量表示,以使具有相似含义的句子在向量空间中接近。
实验数据
数据集为QA_corpus,训练数据10w条,验证集和测试集均为1w条。实例如下:
[('为什么我无法看到额度', '为什么开通了却没有额度', 0),
('为啥换不了', '为两次还都提示失败呢', 0),
('借了钱,但还没有通过,可以取消吗?', '可否取消', 1),
('为什么我申请额度输入密码就一直是那个页面', '为什么要输入支付密码来验证', 0),
('今天借 明天还款可以?', '今天借明天还要手续费吗', 0),
('你好!今下午咱没有扣我款?', '你好 今天怎么没有扣款呢', 1),
('所借的钱是否可以提现?', '该笔借款可以提现吗!', 1),
('不是邀请的客人就不能借款吗', '一般什么样得人会受邀请', 0),
('人脸失别不了,开不了户', '我输入的资料都是正确的,为什么总说不符开户失败?', 0),
('一天利息好多钱', '1万利息一天是5元是吗', 1)]
1、实验代码


# 先安装sentence_transformers
from sentence_transformers import SentenceTransformer
# Define the model. Either from scratch of by loading a pre-trained model
model = SentenceTransformer('distiluse-base-multilingual-cased')
# distiluse-base-multilingual-cased 蒸馏得到的,官方预训练好的模型
# 加载数据集
def load_data(filename):
D = []
with open(filename, encoding='utf-8') as f:
for l in f:
try:
text1, text2, label = l.strip().split(',')
D.append((text1, text2, int(label)))
except ValueError:
_
return D
train_data = load_data('text_matching/input/train.csv')
valid_data = load_data('text_matching/input/dev.csv')
test_data = load_data('text_matching/input/test.csv')
from sentence_transformers import SentenceTransformer, SentencesDataset
from sentence_transformers import InputExample, evaluation, losses
from torch.utils.data import DataLoader
# Define your train examples.
train_datas = []
for i in train_data:
train_datas.append(InputExample(texts=[i[0], i[1]], label=float(i[2])))
# Define your evaluation examples
sentences1,sentences2,scores = [],[],[]
for i in valid_data:
sentences1.append(i[0])
sentences2.append(i[1])
scores.append(float(i[2]))
evaluator = evaluation.EmbeddingSimilarityEvaluator(sentences1, sentences2, scores)
# Define your train dataset, the dataloader and the train loss
train_dataset = SentencesDataset(train_datas, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=16)
train_loss = losses.CosineSimilarityLoss(model)
# Define your train dataset, the dataloader and the train loss
train_dataset = SentencesDataset(train_datas, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=16)
train_loss = losses.CosineSimilarityLoss(model)
# Tune the model
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=3, warmup_steps=100,
evaluator=evaluator, evaluation_steps=200, output_path='./two_albert_similarity_model')
2、向量相似度的测评:
# Define your evaluation examples
sentences1,sentences2,scores = [],[],[]
for i in test_data:
sentences1.append(i[0])
sentences2.append(i[1])
scores.append(float(i[2]))
evaluator = evaluation.EmbeddingSimilarityEvaluator(sentences1, sentences2, scores)
model.evaluate(evaluator)
>>> 0.68723840499831
3、模型准确度的测评:
''' Evaluate a model based on the similarity of the embeddings by calculating the accuracy of identifying similar and dissimilar sentences. The metrics are the cosine similarity as well as euclidean and Manhattan distance The returned score is the accuracy with a specified metric. ''' evaluator = evaluation.BinaryClassificationEvaluator(sentences1, sentences2, scores) model.evaluate(evaluator)
>>> 0.8906211331111515
4、测试模型获取向量
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('./two_albert_similarity_model')
# Sentences are encoded by calling model.encode()
emb1 = model.encode('什么情况导致评估不过')
emb2 = model.encode("个人信用怎么评估出来的")
print(emb1)
print(emb2)
cos_sim = util.pytorch_cos_sim(emb1, emb2)
print("Cosine-Similarity:", cos_sim)
emb1:[ 2.98918579e-02 -1.61327735e-01 -2.11362451e-01 -8.07176754e-02 8.48087892e-02 -1.54550061e-01 -1.11961491e-01 -7.36757461e-03 。。。 -1.64973773e-02 -6.62902296e-02 7.76088312e-02 -5.86621352e-02]
emb2:[-0.00474379 0.01176221 -0.12961781 0.03897651 -0.08082788 0.02274037 -0.01527447 -0.03132218 0.04967966 -0.11125126 0.03260884 -0.08910057。。。 0.04023521 0.07583613 -0.01950659 -0.04246246 0.03055439 0.0451214] Cosine-Similarity: tensor([[-0.0515]])
5、模型向量召回
from tqdm import tqdm
import numpy as np
import faiss # make faiss available
ALL = []
for i in tqdm(test_data):
ALL.append(i[0])
ALL.append(i[1])
ALL = list(set(ALL))
DT = model.encode(ALL)
DT = np.array(DT, dtype=np.float32)
# https://waltyou.github.io/Faiss-Introduce/
index = faiss.IndexFlatL2(DT[0].shape[0]) # build the index
print(index.is_trained)
index.add(DT) # add vectors to the index
print(index.ntotal)
6、查询最相似的文本
k = 10 # we want to see 10 nearest neighbors aim = 220 D, I = index.search(DT[aim:aim+1], k) # sanity check print(I) print(D) print([ALL[i]for i in I[0]])
[[ 220 4284 3830 2112 1748 639 5625 6062 1515 1396]]
[[0. 0.04789903 0.04982989 0.07678283 0.08252098 0.08306326
0.08532818 0.11053496 0.11116458 0.11140325]]
['4500元一天要多少息', '借一万一天利息多少钱', '万元日利息多少', '代五万元,一天的息是多少', '一万元的日息是多少?', '一万元每天多少钱利息', '1千元日息是多少', '一天利息好多钱', '10000块日利息是多少', '借1万一天多少钱利息啊']
7、先获取特征再查询最相似的文本
query = [model.encode('1万元的每天利息是多少')]
query = np.array(query, dtype=np.float32)
D, I = index.search(query, 10) # sanity check
print(I)
print(D)
print([ALL[i]for i in I[0]])
[[3170 1476 639 2112 1826 3193 1396 4332 5360 1748]]
[[0.03987426 0.05244656 0.05858241 0.05872107 0.07376505 0.08907703
0.0905426 0.09842405 0.10062639 0.10626719]]
['20000每天利息多少', '1万元日利息多少', '一万元每天多少钱利息', '代五万元,一天的息是多少', '1万元日息是多少啊!', '100000元一天的利息是5000吗', '借1万一天多少钱利息啊', '借一万八,那一天是多少利息', '28000的日息是多少', '一万元的日息是多少?']
五、与其他模型的对比
| 模型 | loss | acc |
|---|---|---|
| DSSM | 0.7613157 | 0.6864 |
| ConvNet | 0.6872447 | 0.6977 |
| ESIM | 0.55444807 | 0.736 |
| ABCNN | 0.5771452 | 0.7503 |
| BiMPM | 0.4852 | 0.764 |
| DIIN | 0.48298636 | 0.7694 |
| DRCN | 0.6549849 | 0.7811 |
| SBERT(distiluse-base-multilingual-cased) | 0.6872384 | 0.8906 - 0.91 |
SBERT模型的准确率提升很多。
其他模型代码参考 terrifyzhao/text_matching
六、更先进的模型
Bert-flow
Keyword-BERT
七、参考材料
SentenceTransformers Documentationwww.sbert.net terrifyzhao/text_matching 文本匹配模型
terrifyzhao/text_matching 文本匹配模型
八、具体代码
from sentence_transformers import SentenceTransformer, SentencesDataset
from sentence_transformers import InputExample, evaluation, losses
from torch.utils.data import DataLoader
import pandas as pd
from tqdm import tqdm
model = SentenceTransformer('distiluse-base-multilingual-cased')
train_data = pd.read_csv(r"train.csv", sep="\t")
train_data.sample(frac=1)
val_data = pd.read_csv(r"val.csv", sep="\t")
val_data.sample(frac=1)
test_data = pd.read_csv(r"test.csv", sep="\t")
def get_input():
train_datas = []
_y = train_data["y"]
_s1 = train_data["s1"]
_s2 = train_data["s2"]
for s1, s2, l in tqdm(zip(_s1, _s2, _y)):
train_datas.append(InputExample(texts=[s1, s2], label=float(l)))
return train_datas
train_datas = get_input()
def eval_examples():
sentences1, sentences2, scores = [], [], []
for s1, s2, l in tqdm(zip(val_data["s1"], val_data["s2"], val_data["y"])):
sentences1.append(s1)
sentences2.append(s2)
scores.append(float(l))
return sentences1, sentences2, scores
sentences1, sentences2, scores = eval_examples()
# Define your train dataset, the dataloader and the train loss
train_dataset = SentencesDataset(train_datas, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=64)
train_loss = losses.CosineSimilarityLoss(model)
evaluator = evaluation.BinaryClassificationEvaluator(sentences1, sentences2, scores)
# Tune the model
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=50, warmup_steps=100,
evaluator=evaluator, evaluation_steps=300, output_path='./two_albert_similarity_model')
model.evaluate(evaluator)
# Define your evaluation examples
def test_examples():
sentences1, sentences2, scores = [], [], []
for s1, s2, l in tqdm(zip(test_data["s1"], test_data["s2"], test_data["y"])):
sentences1.append(s1)
sentences2.append(s2)
scores.append(float(l))
return sentences1, sentences2, scores
sentences1, sentences2, scores = test_examples()
evaluator = evaluation.EmbeddingSimilarityEvaluator(sentences1, sentences2, scores)
print(model.evaluate(evaluator))
evaluator = evaluation.BinaryClassificationEvaluator(sentences1, sentences2, scores)
print(model.evaluate(evaluator))


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】
2020-09-04 springboot+vue 权限管理系统