
谈谈调用腾讯云【OCR-通用印刷体识别】Api踩的坑
一、写在前面
最近做项目需要用到识别图片中文字的功能,本来用的Tesseract这个写的,不过效果不是很理想。
随后上网搜了一下OCR接口,就准备使用腾讯云、百度的OCR接口试一下效果。不过这个腾讯云OCR就折腾了一天!
二、OCR-通用印刷体识别
首先附上文档地址:OCR-通用印刷体识别。
1、通用OCR简介
通用OCR技术提供图片整体文字的检测和识别服务,返回文字框位置与文字内容。支持多场景、任意版面下整图文字的识别,以及中英文、字母、数字的识别。被广泛应用于印刷文档识别、广告图文字识别、街景店招识别、菜单识别、视频标题识别、互联网头像文字识别等。
2、接口url地址
http://recognition.image.myqcloud.com/ocr/general
3、请求包header
接口采用http协议,支持指定图片URL和上传本地图片文件两种方式。
所有请求都要求含有下列的头部信息:
Host、Content-Length、Content-Type、Authorization
三、示例
1、使用 url 的请求包
POST /ocr/general HTTP/1.1
Authorization: FCHXdPTEwMDAwMzc5Jms9QUtJRGVRZDBrRU1yM2J4ZjhRckJi==
Host: recognition.image.myqcloud.com
Content-Length: 187
Content-Type: application/json
{
"appid":"123456",
"bucket":"test",
"url":"http://test-123456.image.myqcloud.com/test.jpg"
}
这个url是万象优图中图片的url地址。

看到这种格式,心里大概有数了,开始敲代码。
2、具体实现
HttpClient client = new HttpClient();
var para = new
{
appid = "123456",
bucket = "test",
url = "http://test-123456.image.myqcloud.com/test.jpg"
};
var jsonPara = JsonConvert.SerializeObject(para);
StringContent content = new StringContent(jsonPara);
content.Headers.ContentType = new MediaTypeHeaderValue("application/json");
content.Headers.ContentLength = jsonPara.Length;
content.Headers.Add("Host", "recognition.image.myqcloud.com");
content.Headers.Add("Authorization", aut);
var taskHrm = client.PostAsync(postUrl, content);
taskHrm.Wait();
var taskStr = taskHrm.Result.Content.ReadAsStringAsync();
taskStr.Wait();
var result = taskStr.Result;
F5运行,结果报错了:
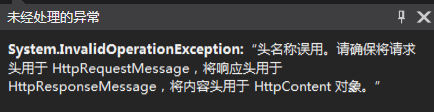
这个错误的原因为:Host和Authorization不能这样添加到Headers中。于是乎我自作聪明的把它们放到参数中了:
var para = new
{
appid = "123456",
bucket = "test",
url = "http://test-123456.image.myqcloud.com/test.jpg",
Host = "recognition.image.myqcloud.com",
Authorization = aut
};
这样运行代码是没有报错,不过后台返回“has no sign or sign is empty”,没有签名。
再回头看看参数要求,Host和Authorization必须添加在请求包Header中。于是百度一下,如何使用Httpclient设置Authorization。最终解决方案如下:
client.DefaultRequestHeaders.Host = "recognition.image.myqcloud.com";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Basic", aut);
成功运行!
但是项目中使用url的几率毕竟少,基本上都是上传一张本地图片,然后识别出来文字。
下面来看一下识别一张本地图片。
3、使用 image 的请求包
POST /ocr/general HTTP/1.1 Authorization: FCHXdPTEwMDAwMzc5Jms9QUtJRGVRZDBrRU1yM2J4ZjhRckJi== Host: recognition.image.myqcloud.com Content-Length: 735 Content-Type: multipart/form-data;boundary=--------------acebdf13572468 ----------------acebdf13572468 Content-Disposition: form-data; name="appid"; 123456 ----------------acebdf13572468 Content-Disposition: form-data; name="bucket"; test ----------------acebdf13572468 Content-Disposition: form-data; name="image"; filename="test.jpg" Content-Type: image/jpeg xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx ----------------acebdf13572468--
说实话看到这种格式,一开始真是一脸懵逼,前面几个参数还好,后面这一大串不知道怎么传递过去,后来百度了一下,这种格式符合RFC 2045协议。
具体解释一下:
第5行:声明Content Type类型,并定义边界字符串。边界符可以自定义,不过最好是用破折号等数据中一般不会出现的字符;
第6、9、13以及18行是换行,传递的时候使用‘\r\n';
第7、11以及15行是‘--’加上第5行的boundary即边界字符串。这里要注意是一定要加上前面的连字符‘--’,我开始没注意写的是和boundary一样,结果一直报错。
第8、10、12、14就是传递的Key_Value类型的数据。“appid”和“bucket”就是要传递的key,而“123456”以及“test”就是分别对应的value。
第16、17行代表另外一个数据,key是image,filename是“test.jpg”。
最后两行就是结束了。注意最后一行是boundary加上‘--’。
弄清楚是什么意思了,就可以开始写代码了。这里我们用WebRequest,至于为什么不用HttpClient,研究ing。不知哪位仁兄使用HttpClient写过,请不吝赐教。
4、具体实现
要识别的图片如下:

HttpWebRequest webReq = (HttpWebRequest)WebRequest.Create(new Uri(postUrl));
Stream memStream = new MemoryStream();
webReq.Method = "POST";
string boundary = "--------------" + DateTime.Now.Ticks.ToString("x");// 边界符
webReq.ContentType = "multipart/form-data; boundary=" + boundary;
接下来是一个换行符,对应第6行:
byte[] enter = Encoding.ASCII.GetBytes("\r\n"); //换行
memStream.Write(enter, 0, enter.Length);
传递key_value的时候格式都是一样,于是我们写在一个循环里面:
Dictionary<string, string> dic = new Dictionary<string, string>()
{
{"appid","1255710379"} ,
{"bucket","test1"}
};
//写入文本字段
string inputPartHeaderFormat = "--" + boundary + "\r\n" + "Content-Disposition:form-data;name=\"{0}\";" + "\r\n\r\n{1}\r\n";
foreach (var kv in dic)
{
string inputPartHeader = string.Format(inputPartHeaderFormat, kv.Key, kv.Value);
var inputPartHeaderBytes = Encoding.ASCII.GetBytes(inputPartHeader);
memStream.Write(inputPartHeaderBytes, 0, inputPartHeaderBytes.Length);
}
接着该写入image了,这里我们在bin/debug里面有一张名为1.jpg的图片(即为上面的图片)。
var fileStream = new FileStream("1.jpg", FileMode.Open, FileAccess.Read);
// 写入文件
string imagePartHeader = "--" + boundary + "\r\n" +
"Content-Disposition: form-data; name=\"{0}\"; filename=\"{1}\"\r\n" +
"Content-Type: image/jpeg\r\n\r\n";
var header = string.Format(imagePartHeader, "image", "1.jpg");
var headerbytes = Encoding.UTF8.GetBytes(header);
memStream.Write(headerbytes, 0, headerbytes.Length);
var buffer = new byte[1024];
int bytesRead;
while ((bytesRead = fileStream.Read(buffer, 0, buffer.Length)) != 0)
{
memStream.Write(buffer, 0, bytesRead);
}
最后就是结束符了:
// 最后的结束符
byte[] endBoundary = Encoding.ASCII.GetBytes("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" + "\r\n" + boundary + "--\r\n");
memStream.Write(endBoundary, 0, endBoundary.Length);
接下来设置其他Header参数:
webReq.ContentLength = memStream.Length; webReq.Headers.Add(HttpRequestHeader.Authorization, aut); webReq.Host = "recognition.image.myqcloud.com";
这里需要注意的一点是设置Host值的时候不能使用
webReq.Headers.Add(HttpRequestHeader.Host, "recognition.image.myqcloud.com");
这个方法,否则会有异常。
var requestStream = webReq.GetRequestStream(); memStream.Position = 0; memStream.CopyTo(requestStream); HttpWebResponse response = (HttpWebResponse)webReq.GetResponse(); StreamReader sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8); var ret = sr.ReadToEnd(); sr.Close(); response.Close(); requestStream.Close(); memStream.Close();
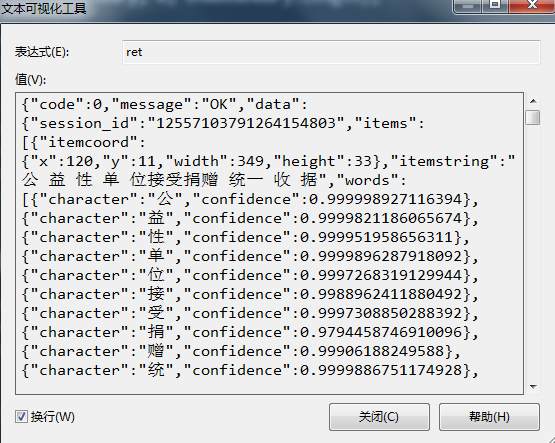
完美运行!识别结果如下:
四、需要注意的点
1、计算Authorization授权签名
签名分为多次有效签名和单次有效签名。它们拼接成的签名串格式为:
a=[appid]&b=[bucket]&k=[SecretID]&e=[expiredTime]&t=[currentTime]&r=[rand]&u=[userid]&f=[fileid]
具体每个字段的含义请参见官方文档:签名和鉴权文档
需要注意的有两点:
1、使用 HMAC-SHA1 算法对请求进行加密;
2、签名串需要使用 Base64 编码(首先对orignal使用HMAC-SHA1算法进行签名,然后将orignal附加到签名结果的末尾,再进行Base64编码,得到最终的sign)。
/// <summary>
/// HMAC-SHA1加密算法
/// </summary>
/// <param name="secret_key">密钥</param>
/// <param name="orignalStr">源文</param>
/// <returns></returns>
public static string HmacSha1Sign(string secret_key, string orignalStr)
{
var hmacsha1 = new HMACSHA1(Encoding.UTF8.GetBytes(secret_key));
var orignalBytes = Encoding.UTF8.GetBytes(orignalStr);
var hashBytes = hmacsha1.ComputeHash(orignalBytes);
List<byte> bytes = new List<byte>();
bytes.AddRange(hashBytes);
bytes.AddRange(orignalBytes);
return Convert.ToBase64String(bytes.ToArray());
}
2、一些其他需要注意的
1、文中使用的appid、bucket、secret_id、secret_key需要注册万象优图后,才能得到。至于如何得到,文档中说的很清楚,有详细的步骤。
2、在设置Header参数时,Content_Length和Host可以不用设置。
五、最后
希望你在调用腾讯云-OCR通用印刷体识别Api的时候可以少走些弯路,少踩一些坑。当然了这些可能算不上坑,可能是个人一些基础知识没掌握。不管怎么样,如果你在使用OCR的时候,本文对你有一点帮助,那它就发挥了应有的作用。
本文的源代码有兴趣的可以下载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号