个人项目-WC (java实现)
一、Github地址:https://github.com/734635746/WC
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 1130 | 970 |
| · Analysis | · 需求分析 | 100 | 80 |
| · Design Spec | · 生成设计文档 | 40 | 50 |
| · Design Review | · 设计复审 | 40 | 60 |
| · Coding Standard | · 代码规范 | 20 | 30 |
| · Design | · 具体设计 | 80 | 60 |
| · Coding | · 具体编码 | 700 | 600 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 60 |
| Reporting | 报告 | 120 | 130 |
| · Test Report | · 测试报告 | 60 | 50 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 40 |
| 合计 | 1280 | 1130 |
三、解题思路
在仔细阅读完项目的需求后,我发现了整个项目的流程主要就是接收具体的参数对指定的文件进行具体的操作。
1.文件操作对象的设计
由于对文件的处理是通过不同的参数来实现不同的处理、而且这些不同的操作基本是只依赖于处理参数和文件路径。我首先想到的是采用多态的思想,将这些不同的操作封装成不同的处理类并且让这些处理类实现同一个接口(FileProcessor)、这样做可以通过接口调用公共方法而实现不同的处理行为、提高了代码的可扩展性。
2.简单工厂模式
如果直接通过new的方式来创建文件处理对象那么将会使代码冗余、不易浏览与维护。所以我采用了简单工厂模式,通过具体的操作参数(-a、-l、-w、-c)去工厂获取对应的文件处理对象进行处理。由于采用了简单工厂设计模式了,所以外界只管通过参数来获取对象,而不用关心对象的具体创建,利于整个软件体系结构的优化。
3. 处理结果的返回
一开始我想直接将处理的结果通过字符串的方式返回。但感觉有些违反了对修改开放-对扩展开放的原则,如果以后的返回的信息多样化了之后,代码将会很难修改。所以我将处理返回结果设计成一个类(FileResult).将需要返回的内容作为属性封装在对象中返回。再之后,我考虑到文件的处理并不一定成功还需要返回错误对象。所以我设计一个错误返回类(ErrorResult),同时让处理结果类和错误返回类实现接口(result)。便于结果的统一处理。
4. 错误类型的枚举
考虑到程序的可读性以及后期的扩展性,设计了一个错误类型的枚举(ErrorTypeEnum),用于枚举程序中有可能出现的错误,并且在错误返回类中支持了错误类型枚举。提高的程序的可读性。
5. 递归处理的实现
到这里实现的还是对于当个指定文件的处理。对于实现处理多个文件的功能来说、递归是个好的思想。将“-s”作为第一个参数可以开启递归处理。对于用户输入的目录/文件,首先将会根据处理参数(-a、-l、-w、-c)去工厂获取对应的文件处理对象,然后调用递归处理器(RecursiveProcessor)来递归地获取目录下的所有文件路径,再通过刚才获取的文件处理对象进行批量处理,返回一个处理结果的列表。
6.通配符的支持
程序可以通过“-s”参数配合实现通配符匹配文件的功能。具体实现思路是判断用于输入的文件url是否含有“*”、"?",如果有将进行通配符匹配。
首先截取url的目录部分通过递归处理获取目录下的所有文件类型的url, 然后通过一个工具函数将含有通配符的文件名转成一个正则表达式。最后采用Pattern类进行模式匹配,将匹配的文件路径进行处理放回处理结果集。
8. 图形界面
图形界面的设计比较简单,就是通过设计一个JFrame通过jFileChooser控件选择文件进行处理,再将处理结果显示在TextArea控件上,底层还是调用工厂来获取处理对象进行处理。
8. 主类
主类主要是负责接收处理参数调用不同的文件处理对象进行处理然后接收处理结果进行显示。
总体来说这次项目的完成还是比较顺利,但是代码还是有一定的冗余性可以继续进行优化。最主要就是在开始编码之前要先设计好大概的处理流程以及模块划分。使用学过的知识来优化代码,尽量降低代码的耦合性,提高代码的可读性、可扩展性和易修改性。
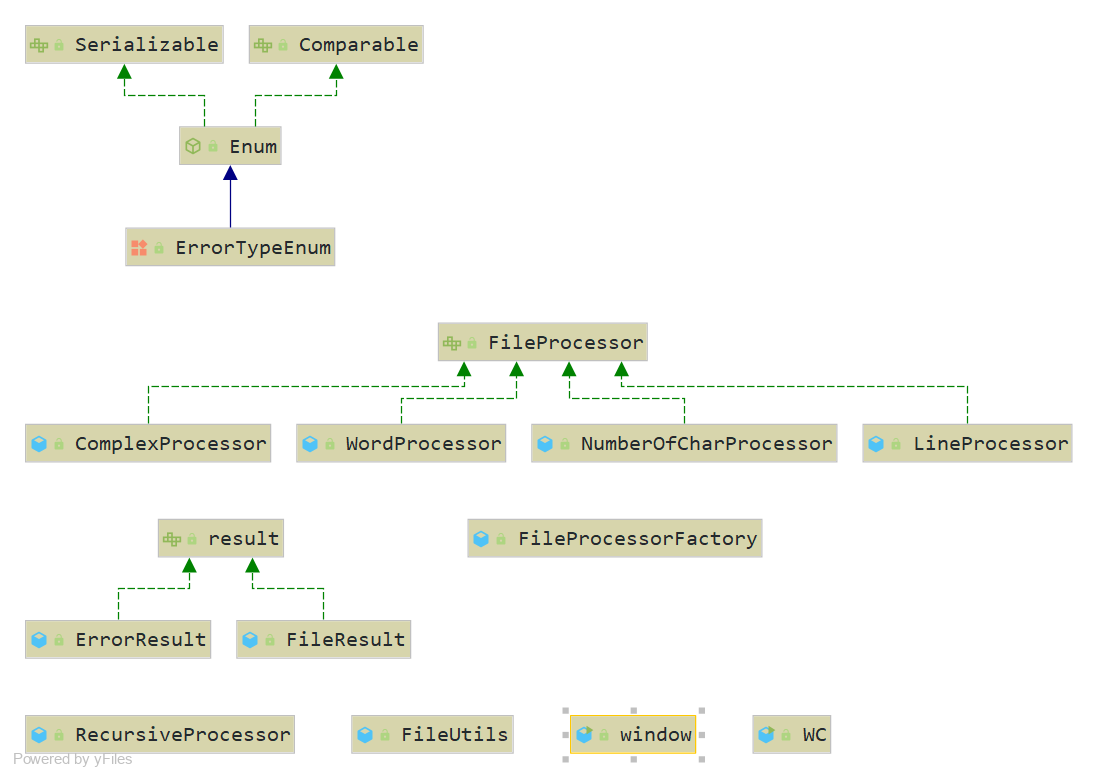
四、设计实现过程
代码主要分成个 主类、错误枚举、 处理结果类 、处理工厂及其处理类 、工具类、图形界面类 六个部分
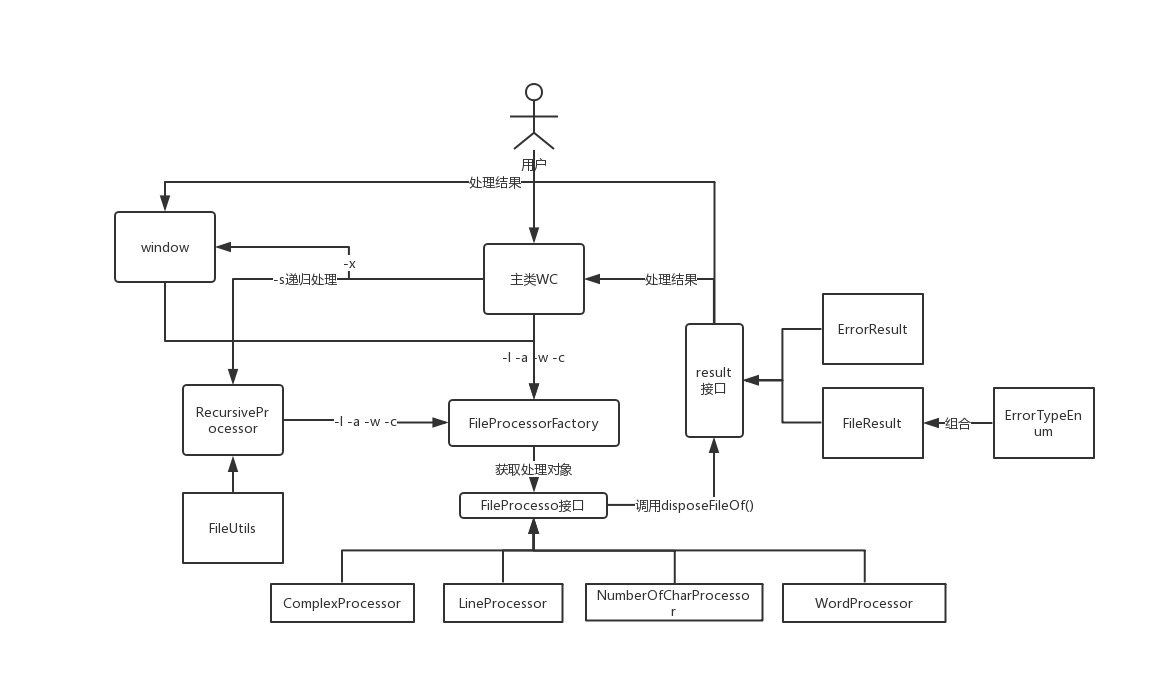
主要调用流程:
五、测试运行
测试文件包括:一个空文件、一个只有一个字符的文件、一个只有一个单词的文件、一个标准的java源文件、一个多目录嵌套的文件
5.1 测试非递归的功能(-l、-a、-w 、-c)
@org.junit.Test
public void testFunction_2() throws IOException {
String url = "F:\\file\\k.txt";
String[] params= new String[]{"-a","-l","-w","c"};
for (String param : params) {
testOneProcessor(url,param);
}
}
private void testOneProcessor(String url, String param) throws IOException {
FileProcessor processor = FileProcessorFactory.getFileProcessorOf(param);
result result = processor.disposeFileOf(url);
result.showResult();
}
5.1.1 测试空文件
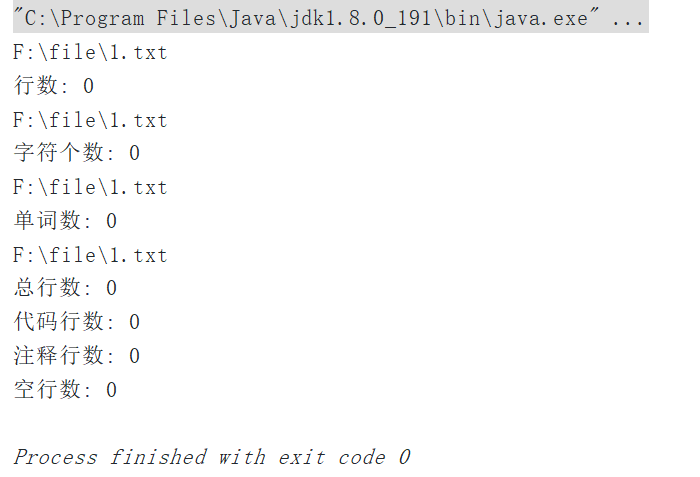
5.1.2 测试一个只有一个字符的文件

5.1.3 测试一个只有一个单词的文件

5.1.4 测试标准java源文件

5.1.5 测试不存在的文件

5.2 测试非递归的功能(-s -a/-w/-l/-c)
5.2.1 测试多目录嵌套的文件
@org.junit.Test
public void test() throws IOException {
String url = "F:\\file\\k.txt";
String[] params= new String[]{"-a","-l","-w","c"};
for (String param : params) {
testRecursive(url,param);
}
}
private void testRecursive(String url, String param) throws IOException {
FileProcessor processor = FileProcessorFactory.getFileProcessorOf(param);
RecursiveProcessor processor1 = new RecursiveProcessor(processor, url);
List<result> result = processor1.getDisposeResult();
for (com.lyb.bean.result result1 : result) {
result1.showResult();
}
}




5.2.2 测试多目录嵌套的文件配合通配符?
@org.junit.Test public void testFunction2() throws IOException { String url = "F:\\file\\?.txt"; FileProcessor processor = FileProcessorFactory.getFileProcessorOf("-a"); RecursiveProcessor processor1 = new RecursiveProcessor(processor, url); List<result> result = processor1.getDisposeResult(); for (com.lyb.bean.result result1 : result) { result1.showResult(); } }

5.3 测试图形化功能(-x)
![]()
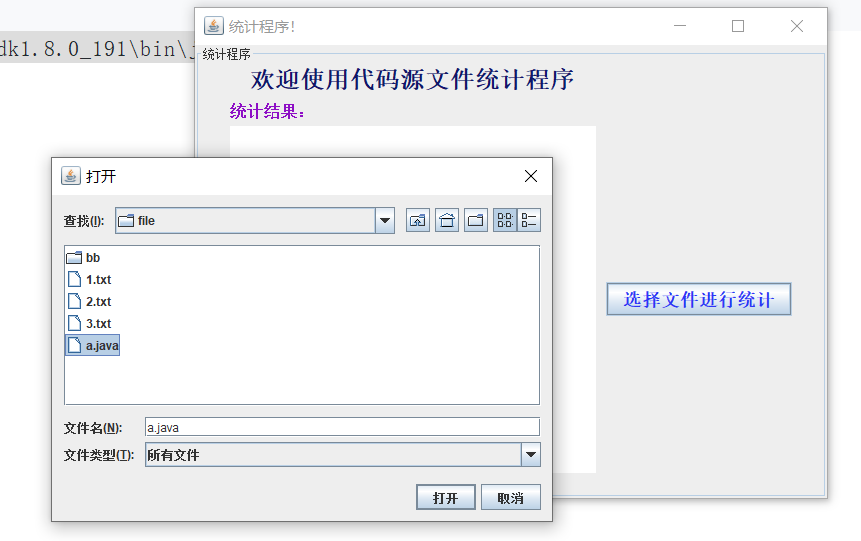
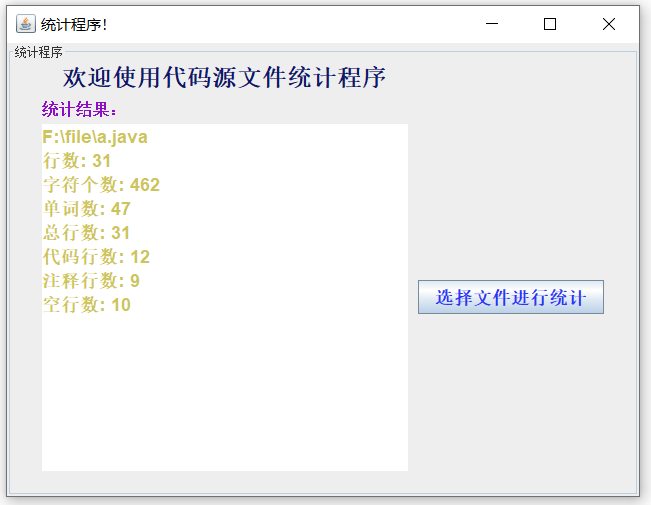
经过验证所有处理结果与预期结果一致
代码覆盖率:

由于图形化界面的测试是单独测试而不是在单测中进行,所以代码覆盖率中图形界面的代码覆盖率为0。也由于这样,所以一些在图形界面中使用的api没有覆盖到。
六、项目总结
本次项目选用java作为开发语言、maven作为构建工具、junit做单元测试、jacoco做代码覆盖率检查插件。
遵循一定的代码开发规范、努力使用面向对象的思想解决问题。运用软件工程的方法努力写出较为规范的代码、尽量降低模块的耦合度。但是还是存在不足,代码的冗余度还是比较高。总体来说这是一个比较好的练手项目,即复习了java中的IO流使用,也学着运用软件工程的思想来规范开发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号