
Hive初识
楔子
Hive是什么?
- 基于Hadoop的数据仓库查询引擎,而Hadoop正是在廉价的硬件基础上为数据的存储和处理提供了大规模的横向扩展和容错能力.
- 可以很方便的进行数据汇总,即席查询和大规模的数据分析
- 提供类似SQL的HQL供用户进行数据的查询和分析操作
- 支持自定义函数的查询操作
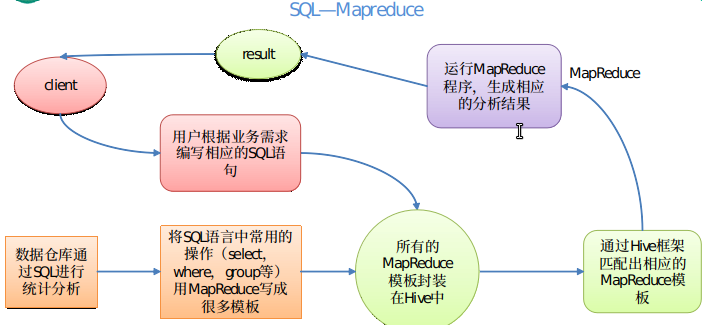
Hive不是什么?
- 不是关系型数据库
- 不为OLTP而设计
- 不是实时查询和行级的更新语言(针对HQL来说)
Hive特点
- Schema存储在关系型数据库,数据存储在HDFS
- 为OLAP而生
- 提供类似SQL的HQL查询语言
- 易上手,快速,分布式且可扩展
Hive本质
将HQL转换成MapReduce程序提交至Yarn进行查询
Hive的优缺点
优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免了去写MapReduce,减少开发人员的学习成本
- Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点
- HQL表达能力有限
- 迭代算法无法表达
- 不擅长数据挖掘
- HQL效率较低
- 生成的MapReduce作业通常不够智能化
- 提交较为困难,粒度较粗
架构

CLI
对Hive进行操作的客户端,目前支持的有hive shell,JDBC,WEB UI
元数据
存储Schema元信息,指对数据库,表,函数等对象的定义,一般存储在特定的关系数据库中,如MySQl,Postgresql,在生产环境中不会使用Hive自身提供的Derby作为元信息的存储
MapReduce
将HQL转换成MapReduce程序,提交至Yarn执行
驱动器
(1) 解析器:将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误
(2) 编译器:将AST编译生成逻辑执行计划
(3) 优化器:对编译器生成的逻辑计划进行优化
(4) 执行器:把逻辑执行计划转换成可以运行的物理计划,对于Hive来说,就是MR/Spark。
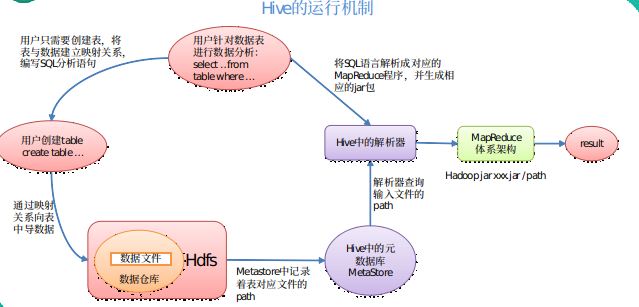
总结:Hive通过给用户提供的一系列交互接口,接收到用户的指令(HQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口
与数据库的差异
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性.
查询语言
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发
数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中.
数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少。因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候已经确定。而数据库中的数据通常是需要经常进行修改,因此可以使用INSERT INTO … VALUES 添加数据,使用 UPDATE … SET修改数据.
索引
Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询.
执行
Hive中大多数查询的执行是通过Hadoop提供的MapReduce来实现,而数据库通常使用自身支持的多种查询引擎进行数据的实时查询.
执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势.
可扩展性
由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的(世界上最大的Hadoop 集群在 Yahoo!,2009年的规模在4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有100台左右.
数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小.

