Elasticsearch 01简单入门 以及 Head 插件安装
简介
Lucene 是什么?
Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。Lucene 只是一个库,想要发挥出强大作用,需要使用Java将其集成到应用中。Lucene非常复杂,需要深入了解检索相关知识理解它是如何工作的。
Elasticsearch 是什么?
Elasticsearch 是一个基于 Apache Lucene 的开源搜索引擎。
Elasticsearch 是使用Java编写并使用Lucene来建立索引并实现搜索功能。它的目的是通过简单连贯的RestFul API 让全文搜索变得简单来隐藏Lucene的复杂性。
Elasticsearch 不仅仅是Lucene和全文搜索引擎,它还提供:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 实时分析的分布式搜索引擎
- 可以拓展到上百台服务器(集群),处理PB级结构化或非结构化数据
Elasticsearch 中涉及到的重要概念
-
接近实时(NRT)
Elasticsearch 是一个接近实时的搜索平台。 -
集群(cluster)
Elasticsearch 支持集群部署,一个集群就是由一个或多个节点组织在一起,它们共同持有整个数据,并一起提供索引和搜索功能。 一个集群由一个唯一的名字标识,默认“elasticsearch” -
节点(node)
一个节点是集群中的一个服务器,作为集群的一部分, 一一个节点也是由一个名字来标识,默认是一个随机的漫威漫画角色的名字。一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入“elasticsearch”集群中。
-
索引(index)
一个索引就是一个拥有几分相似特征的文档的集合。类似于关系型数据库(Mysql)中Database的概念。一个索引由一个名字来标识(
必须全小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字 -
类型(type)
在一个索引中,可以定义一种或多种类型。一个类型是索引的一个逻辑上的分类/分区。通常会为具有一组共同字段的文档定义一个类型。类似于关系型数据库(Mysql)中的Table 的概念。 -
文档(document)
一个文档是一个可被索引的基础信息单元。文档以 JSON 格式来标识。
在一个index/type里,只要想,可以存储任意多的文档。文档必须被索引/赋予一个索引的type。文档类似于关系型数据库中的一条记录 -
分片和复制(shard & replicas)
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有10亿文档的索引占据了1TB的磁盘空间,单个节点没这么大的空间;或者单个节点处理搜索请求,相应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,这些份叫做分片(shard)。 当创建一个索引的时候,可以指定想要分片的数量。每个分片本身也是一个功能完善并且独立的索引,这个索引可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面原因:
- 允许水平分割,拓展内容容量
- 允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,完全由Elasticsearch管理。对于用户来说是透明的。
副本指的是分片的副本,是shard的复制
复制之所以重要,主要有两个原因:
- 再shard/node失败的时候,它提供高可用性。正因为如此,复制的shard绝不会跟原始shard在同一个节点上
- 拓展搜索量/吞吐量,因为搜索可以在所有的复制上并行运行
总结:每个索引可以被分成多个分片。 一个索引也可以被复制0次或多次。 一旦复制了,每个索引就有了主分片和复制分片。 分片和复制的数量可以在创建索引的时候指定。
在索引创建之后,可以在任何时候动态地改变复制数量,但不能改变分片的数量。小结
- node 是一台服务器,表示集群中的节点
- document 表示索引记录
- 一个index中不建议定义多个type
- 一个index可以有多个shard,每个shard可以有0个或多个副本
- original shard(原始分片)的复制成为副本shard,简称 shard
- 主分片和副本绝不会在同一个节点上
- 分片的好处主要有两个:1.突破单台服务器的硬件限制;2.可以并行操作,从而提高性能和吞吐量(跟kafka类似)
- 副本的好处主要在有两个:1.提供高可用; 2.并行提升性能和吞吐量
- 一个索引包含一个或多个分片,索引记录(文档)数据存储在这些shard中,且一个文档只会存在于一个分片中
- 每个shard都是一个独立的功能完善的“index”,意思是它可以独立处理索引/搜索请求
下载
下载
# 创建目录
$ mkdir -p /work/programs/elasticsearch
$ cd /work/programs/elasticsearch# 下载
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.7.2.tar.gz
编辑配置
$ vi config/elasticsearch.yml
修改配置如下:
network.host:0.0.0.0 :实现内网可访问。
启动
注意 :需要使用非Root账号启动。
# 解压
$ tar -zxvf elasticsearch-6.7.2.tar.gz
$ cd elasticsearch-6.7.2
# 启动。通过 -d 参数,表示后台运行。
$ bin/elasticsearch -d
可以通过 logs/elasticsearch.log 查看启动日志。
注意: 如果使用云服务器,要开放端口,才能公网IP访问
测试:
访问: http://112.74.186.224:9200/
{
"name" : "rrpUhc6",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "7yQXN3VDRSikmUOh-fhXJA",
"version" : {
"number" : "6.7.2",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "56c6e48",
"build_date" : "2019-04-29T09:05:50.290371Z",
"build_snapshot" : false,
"lucene_version" : "7.7.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
安装ik分词器插件
以安装ik分词器为例
在 https://github.com/medcl/elasticsearch-analysis-ik/releases 中,提供了各个 elasticsearch-analysis-ik 插件版本。要注意,一定和 Elasticsearch 版本一致。
#cd到elasticsearch目录下 下载
$ wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.7.2/elasticsearch-analysis-ik-6.7.2.zip
# 需要解压到 plugins/ik/ 目录下
$ unzip elasticsearch-analysis-ik-6.5.0.zip -d plugins/ik/
# 查找 ES 进程,并关闭它
$ ps -ef | grep elastic
$ kill 2382 # 假设我们找到的 ES 进程号为 2382 。
# 启动 ES 进程
$ bin/elasticsearch -d
# 测试ik分词器
# ik_max_word 模式
$ curl -X POST \
http://localhost:9200/_analyze \
-H 'content-type: application/json' \
-d '{
"analyzer": "ik_max_word",
"text": "百事可乐"
}'
# ik_smart 模式
$ curl -X POST \
http://localhost:9200/_analyze \
-H 'content-type: application/json' \
-d '{
"analyzer": "ik_smart",
"text": "百事可乐"
}'
安装 elasticsearch-head
elasticsearch-head 需要node环境支持
安装node环境,这边假设已经安装完成
[lyk@iZwz99hfh1ddgd1z6q5u3mZ elasticsearch-6.7.2]$ node -v
v10.24.0
[lyk@iZwz99hfh1ddgd1z6q5u3mZ elasticsearch-6.7.2]$ npm -v
6.14.11
从github下载elasticsearch-head 并解压
我这边解压到了 head-master文件夹;
wget https://github.com/mobz/elasticsearch-head/archive/master.zip
unzip master.zip
npm 安装阿里镜像 提速
[root@iZwz99hfh1ddgd1z6q5u3mZ head-master]# npm install cnpm -g --registry=https://registry.npm.taobao.org
安装head 所需的包
[root@iZwz99hfh1ddgd1z6q5u3mZ head-master]# cnpm install
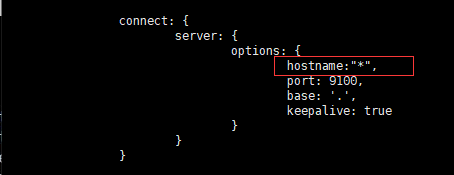
修改 Gruntfile.js文件
[root@iZwz99hfh1ddgd1z6q5u3mZ head-master]# vi Gruntfile.js
启动head插件
[root@iZwz99hfh1ddgd1z6q5u3mZ head-master]# npm run start
> elasticsearch-head@0.0.0 start /work/programs/elasticsearch/head-master
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
修改 elasticsearch-head 默认连接地址
[root@iZwz99hfh1ddgd1z6q5u3mZ head-master]# cd _site/
[root@iZwz99hfh1ddgd1z6q5u3mZ _site]# vi app.js

连接会有跨域问题,需要解决跨域
在 elasicsearch.yml文件末尾加跨域配置
#允许跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
启动 head 服务
[lyk@iZwz99hfh1ddgd1z6q5u3mZ head-master]$ cd node_modules/grunt/bin/
[lyk@iZwz99hfh1ddgd1z6q5u3mZ bin]$ ./grunt server &
[1] 1331
[lyk@iZwz99hfh1ddgd1z6q5u3mZ bin]$ Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
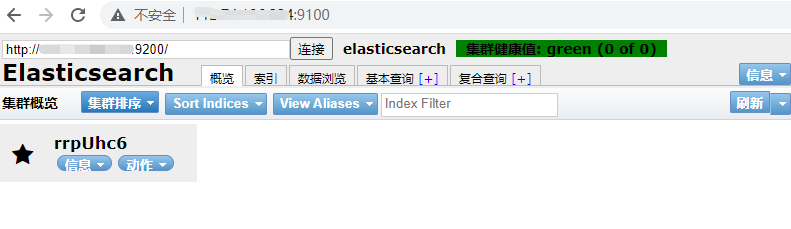
集群健康值描述
- 绿色:最健康的状态,代表所有的分片包括备份都可用
- 黄色:基本的分片可用,但是备份不可用(也可能是没有备份)
- 红色:部分的分片可用
- 灰色: 未连接到elasticsearch服务
本文由博客一文多发平台 OpenWrite 发布!

