数据采集第二次作业
目录
链接:(https://gitee.com/liu-ying0902/liuying012/tree/master/第二次作业)
作业①
要求
在中国气象网(http://www.weather.com.cn)给定城市集的 7 日天气预报,并保存在数据库中。
输出信息
Gitee 文件夹链接
一、实验
1. 思路
-
创建数据库:
WeatherDB类在 SQLite 数据库中创建了一张名为weathers的表,用于存储城市天气信息。表的字段包括城市名(wCity)、日期(wDate)、天气状况(wWeather)和温度(wTemp)。这张表的主键是城市名和日期的组合,保证同一天同一个城市的信息不会重复插入。 -
爬取天气信息:
WeatherForecast类负责爬取指定城市的天气信息。城市对应的代码在self.cityCode中预先定义。利用urllib发送请求,并通过BeautifulSoup解析返回的 HTML 页面。它会从页面中提取天气的日期、状况和温度,并将这些数据插入数据库。 -
插入数据:
天气信息通过WeatherDB类的insert方法插入到数据库中。如果数据插入发生冲突(比如同一天同一城市已经存在数据),则会捕获异常并输出错误信息。 -
处理多个城市:
process方法接受一个城市列表,遍历每个城市,调用forecastCity方法抓取天气数据,并在每次城市数据爬取完成后将数据存入数据库。 -
显示数据:
数据库中的内容可以通过show方法以表格形式输出,方便用户查看存储的天气信息。
2. 重要代码部分
点击查看代码
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
使用 BeautifulSoup 解析天气网页,通过 CSS 选择器提取日期、天气和温度信息,并格式化输出。
3. 运行结果
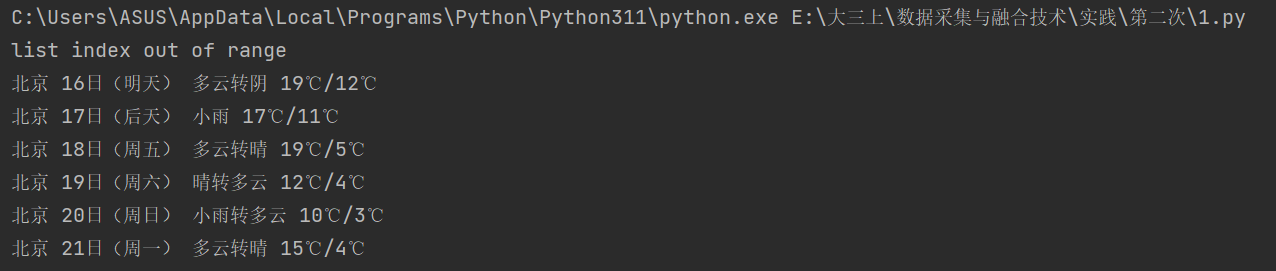
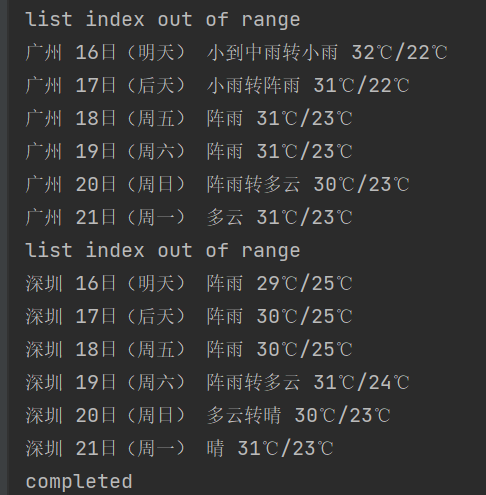
二、心得
-
数据存储与爬取结合:
该代码将网络爬虫和数据库操作相结合,在抓取完城市天气后,立即将数据存入数据库,并使用 SQLite 的主键约束避免重复数据插入。既保证了爬虫的效率,也保证了数据的一致性。 -
异常处理:
在爬取网页和插入数据库时,网络故障或数据格式不符等问题可能导致程序崩溃。代码通过捕获异常并输出错误信息,有效避免了程序中断,增强了代码的健壮性和容错性。
作业②
要求
用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
候选网站
技巧
在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加载使用的 URL,并分析 API 返回的值,并根据所要求的参数可适当更改 API 的请求参数。根据 URL 可观察请求的参数 f1、f2 可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
输出信息
Gitee 文件夹链接
一、实验
1. 思路
-
创建数据库:
使用 SQLite 数据库,通过cursor.execute定义了一张名为my_table的表,包含股票代码、名称、最新价格、涨跌幅、涨跌额、成交量、成交额等股票相关信息字段。每条数据都有一个自增的主键id作为唯一标识。 -
爬取股票数据:
通过requests库发送 HTTP GET 请求,访问eastmoney.com的 API 来获取股票列表数据。URL 的page参数可以由用户输入,程序支持同时爬取多个页面的股票数据。 -
解析 JSON 数据:
返回的数据包含一个 JSON 对象,但被包裹在 jQuery 函数回调中,代码通过find方法提取括号中的 JSON 数据,随后使用json.loads将其转换为 Python 字典。 -
提取并插入股票信息:
在解析到股票信息后,选择所需字段plist并将其数据插入到 SQLite 数据库中。每条记录包含多个字段如股票代码(f12)、股票名称(f14)、最新价格(f2)等。 -
展示数据库中的内容:
爬取完数据后,从数据库中查询所有记录,并以表格形式显示。每条记录包括多个股票信息字段,以清晰的格式输出。
2. 重要代码部分
点击查看代码
start = response.text.find('(')
end = response.text.rfind(')')
data = response.text[start + 1:end]
data = json.loads(data)
解释:
返回的数据被包裹在 jQuery 函数中,使用 find 和 rfind 提取出括号内的纯 JSON 数据,再将其转为字典进行解析。
点击查看代码
row = tuple(stock[field] for field in plist)
cursor.execute('''INSERT INTO my_table (code, name, latest_price, change_percent, change_amount,
volume, turnover, amplitude, high, low, opening_price, yesterday_close,
volume_ratio, turnover_rate, pe_ratio, pb_ratio)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)''', row)
解释:
通过 INSERT INTO 语句将爬取到的股票数据插入到数据库中,每次插入一条股票记录。
3. 运行结果
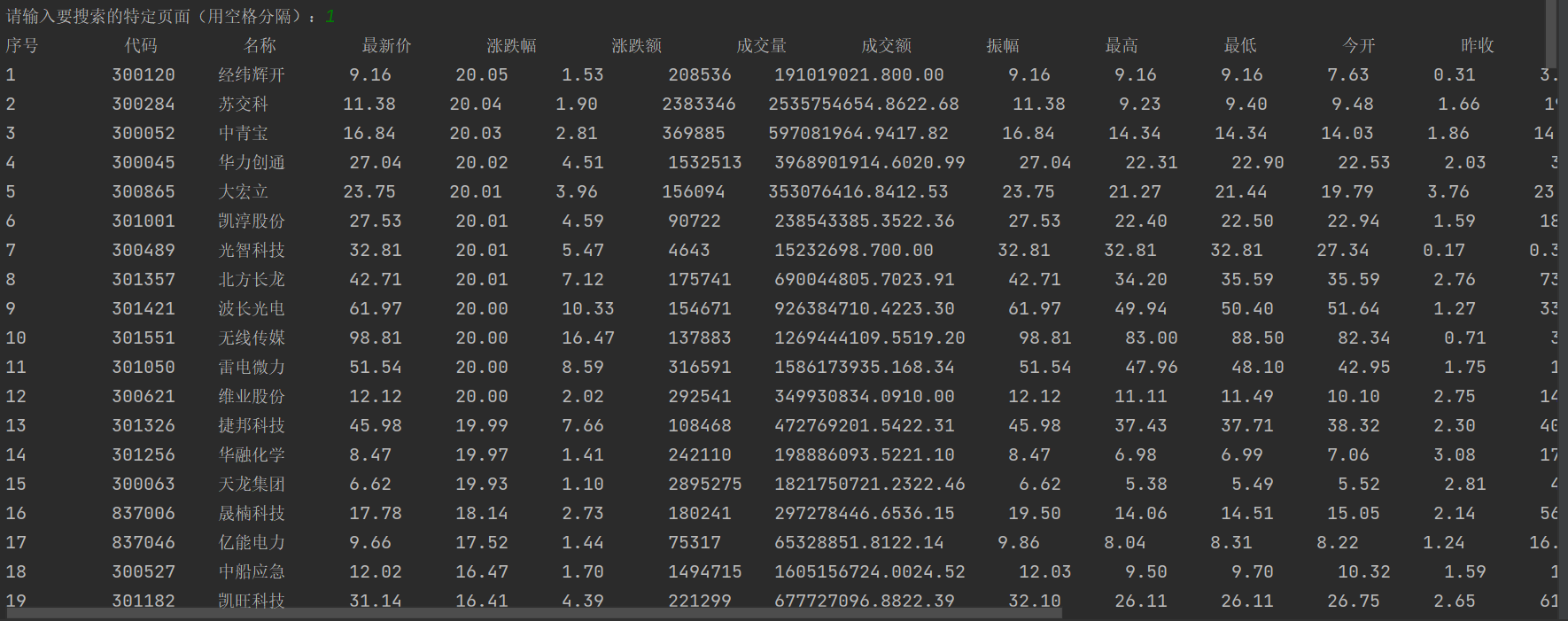
二、心得
-
灵活的页面输入和多页爬取:
通过用户输入的页面序号,程序可以灵活爬取指定页面的股票数据,并通过 API 获取股票列表。这允许用户根据需求爬取特定页面,具有较强的灵活性。 -
数据库与网络爬虫结合:
程序将网络爬虫和 SQLite 数据库紧密结合,在爬取到数据后立即存储到本地数据库,确保数据的持久化。同时,后续查询可以直接从数据库中进行,避免重复爬取,提升了效率。
作业③
要求
爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 GIF 加入至博客中。
输出信息
Gitee 文件夹链接
排名 学校 省市 类型 总分
1 清华大学 北京 综合 969.2
一、实验
1. 思路
-
发送请求获取数据:
通过requests.get()函数从目标网站抓取包含学校排名信息的.js文件内容。该文件存储了 2021 年的中国大学主榜排名数据。 -
使用正则表达式提取关键信息:
代码利用re.findall()函数对.js文件内容进行正则表达式匹配,提取学校的中文名称、总分、学校类型和学校所在省份等字段。 -
解析学校代码和数据含义:
提取了function函数中的参数列表(code_name),以及与这些参数对应的具体值(value_name)。这两个列表用于匹配省份和学校类型的具体含义。 -
将数据存储在 Pandas DataFrame 中:
创建一个包含列名为“排名”、“学校”、“省份”、“类型”、“总分”的DataFrame,并将每个学校的数据逐行填充到表格中。 -
保存为 Excel 文件:
最后,通过to_excel()方法将DataFrame保存为 Excel 文件test3_school.xlsx,方便进一步使用。
2.抓包过程
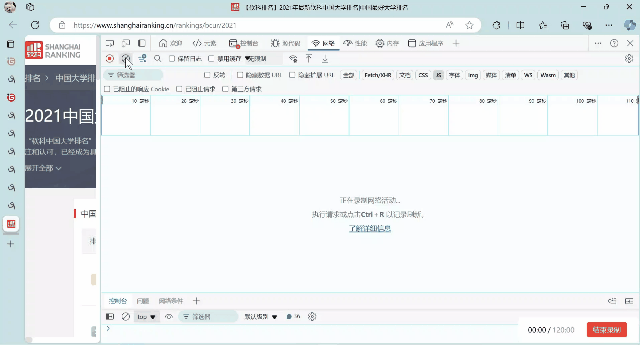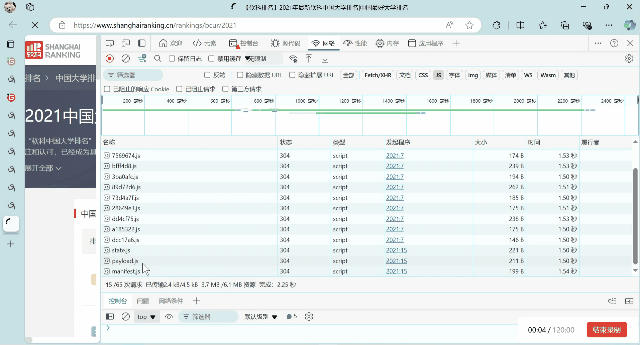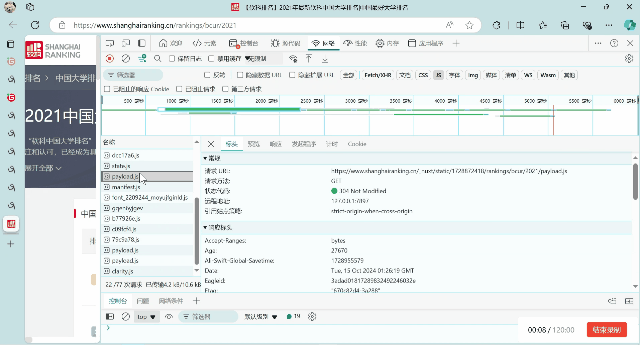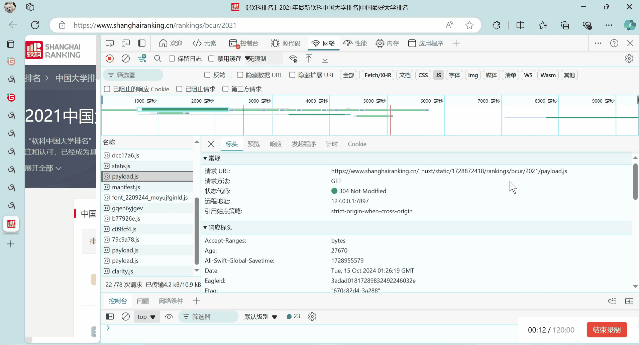
3. 重要代码部分
点击查看代码
name = re.findall(',univNameCn:"(.*?)",',resquest.text)
score = re.findall(',score:(.*?),',resquest.text)
category = re.findall(',univCategory:(.*?),',resquest.text)
province = re.findall(',province:(.*?),',resquest.text)
解释:
使用正则表达式提取学校名称、学校总分、学校类型和所在省份信息,并将这些信息存储在列表中。
点击查看代码
code_name = re.findall('function(.*?){',resquest.text)
start_code = code_name[0].find('a')
end_code = code_name[0].find('pE')
code_name = code_name[0][start_code:end_code].split(',')
value_name = re.findall('mutations:(.*?);',resquest.text)
start_value = value_name[0].find('(')
end_value = value_name[0].find(')')
value_name = value_name[0][start_value+1:end_value].split(",")
解释:
用于解析 .js 文件中学校代码及其相应的含义,通过 function 函数中的参数和 mutations 对应的值列表,将学校代码映射为实际的省份或类型。
点击查看代码
df = pd.DataFrame(columns=["排名","学校","省份","类型","总分"])
for i in range(len(name)):
province_name = value_name[code_name.index(province[i])][1:-1]
category_name = value_name[code_name.index(category[i])][1:-1]
df.loc[i] = [i+1, name[i], province_name, category_name, score[i]]
解释:
创建了一个包含学校排名、名称、省份、类型、总分的 DataFrame,并将每个学校的相关信息逐行填充到表格中。
4. 运行结果

二、心得
-
正则表达式高效提取数据:
通过re.findall()函数高效地从.js文件中提取出所需的学校信息,减少了手动解析的时间,提高了数据抓取的速度。 -
数据可视化和展示:
将提取的数据存储在DataFrame中,使得后续的数据分析和可视化更加便捷。保存为 Excel 文件的形式也使得数据的共享与展示更为直观。
总结:
在本次数据采集作业中,我完成了三个项目。首先,通过爬取中国气象网的7日天气预报,并将数据存储在SQLite数据库中,实现了对城市天气信息的管理,展示了网络爬虫与数据库结合的实践。其次,利用requests和BeautifulSoup库定向爬取股票相关信息,支持用户输入页面序号以灵活抓取数据,并将结果存储在数据库中,提高了数据处理效率。最后,爬取了中国大学2021主榜的院校信息,通过请求JavaScript文件并使用正则表达式提取关键信息,将数据存储在Pandas DataFrame中,并导出为Excel文件。通过这些作业,我深入理解了网络爬虫、数据存储和处理的实际应用,提升了对相关技术的掌握。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号