Video Target Tracking Based on Online Learning—TLD单目标跟踪算法详解
- 视频目标跟踪问题分析
视频跟踪技术的主要目的是从复杂多变的的背景环境中准确提取相关的目标特征,准确地识别出跟踪目标,并且对目标的位置和姿态等信息精确地定位,为后续目标物体行为分析提供足够的数据。但是目前的绝大部分目标跟踪算法或多或少存在不少缺点,如:1)对目标的实时跟踪时,跟踪时间过长,目标容易丢失;2)当目标发生形变时(目标伪装、摄像平台变化导致),无法进行目标跟踪;3)当视频中目标消失(遮挡等)以后重新出现时,不能重新跟踪捕获目标,或出现混批; 4)有一些给定很少特定目标特征先验知识时,也不能够迅速地跟踪目标。
- 在线学习视频目标跟踪算法TLD
对于长时间跟踪而言,一个关键的问题是:当目标重新出现在相机视野中时,系统应该能重新检测到它,并开始重新跟踪。但是,长时间跟踪过程中,被跟踪目标将不可避免的发生形状变化、光照条件变化、尺度变化、遮挡等情况。传统的跟踪算法,前端需要跟检测模块相互配合,当检测到被跟踪目标之后,就开始进入跟踪模块,而此后,检测模块就不会介入到跟踪过程中。但这种方法有一个致命的缺陷:即,当被跟踪目标存在形状变化或遮挡时,跟踪就很容易失败;因此,对于长时间跟踪,或者被跟踪目标存在形状变化情况下的跟踪,很多人采用检测的方法来代替跟踪。该方法虽然在某些情况下可以改进跟踪效果,但它需要一个离线的学习过程。即:在检测之前,需要挑选大量的被跟踪目标的样本来进行学习和训练。这也就意味着,训练样本要涵盖被跟踪目标可能发生的各种形变和各种尺度、姿态变化和光照变化的情况。换言之,利用检测的方法来达到长时间跟踪的目的,对于训练样本的选择至关重要,否则,跟踪的鲁棒性就难以保证。
TLD(Tracking-Learning-Detection)是英国萨里大学的一个捷克籍博士生Zdenek Kalal在其攻读博士学位期间提出的一种新的单目标长时间(long term tracking)跟踪算法。该算法与传统跟踪算法的显著区别在于将传统的跟踪算法和传统的检测算法相结合来解决被跟踪目标在被跟踪过程中发生的形变、部分遮挡等问题。同时,通过一种改进的在线学习机制不断更新跟踪模块的“显著特征点”和检测模块的目标模型及相关参数,从而使得跟踪效果更加稳定、鲁棒、可靠。
简单来说,TLD算法由三部分组成:跟踪模块、检测模块、学习模块;如下图所示

TLD算法机理
上图中, TLD 算法由跟踪、检测和学习三大模块构成。首先跟踪模块对视频序列中要跟踪的目标采用跟踪器跟踪,判断物体目标在下一帧中的位置, 若目标消失在视频或大量被遮挡,则跟踪失败;其次检测部分主要由分类器构成,分类器通过对视频序列中大量的特征值进行检测归类,找出其中最有可能出现跟踪物体目标的区域,然后综合跟踪部分共同输出决定下一帧中物体目标的方位,如果前面跟踪部分失败,检测成功,则检测部分就会重新初始化跟踪部分, 在下一帧的时候,跟踪模块重新跟踪成功目标。最后对于学习部分,跟踪产生的结果和检测产生的结果又会动态地影响到学习部分,反过来学习模块又会训练改善分类器影响检测的结果。总之检测模块与学习模块相互作用, 不断地动态改善相关过程,提高对跟踪目标的准确性。
- TLD算法实现框图及原理分析
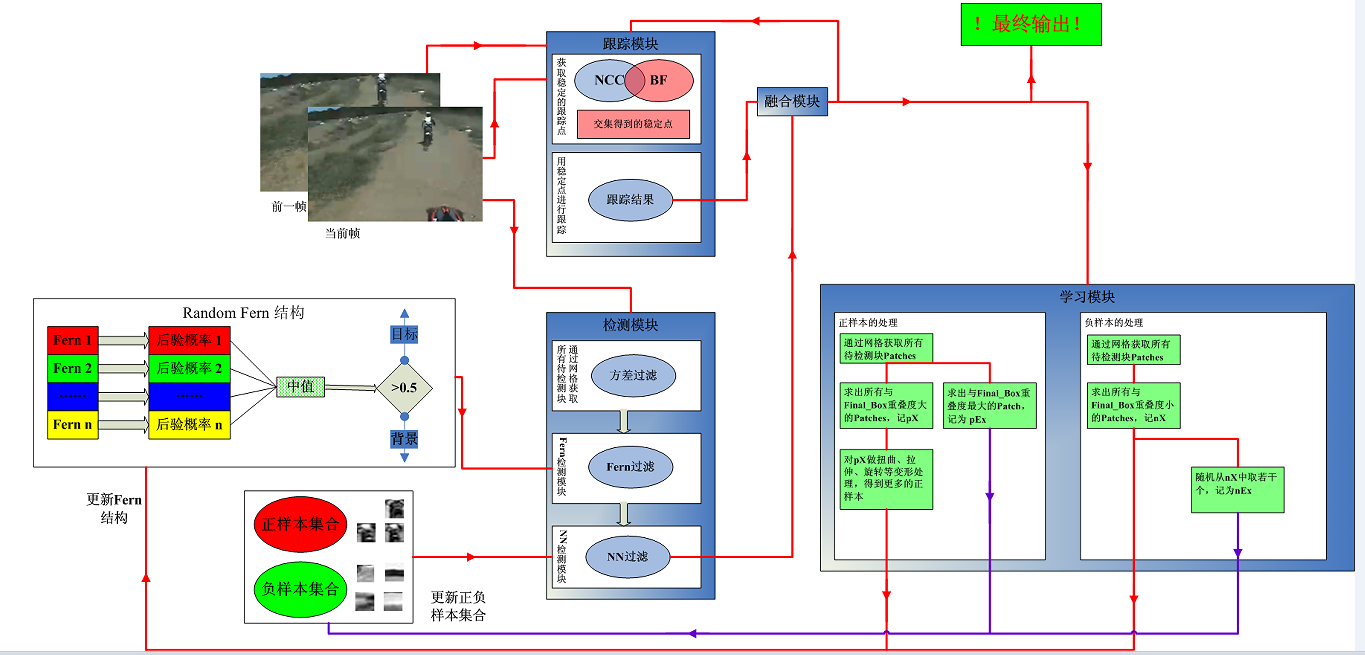
TLD的详细实现框图如下图所示。
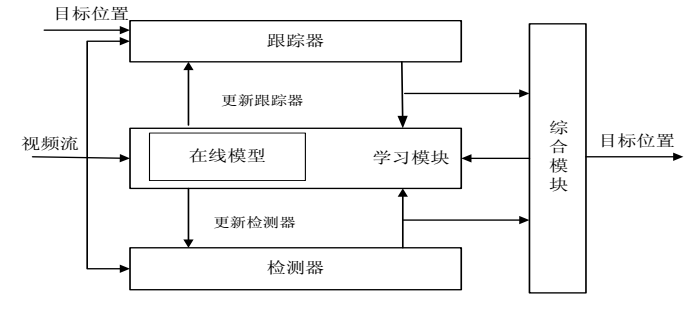
TLD实现框图
从此图中可以看出,首先在视频序列的初始位置,我们先对要跟踪的物体进行相关目标标定,然后此目标位置进入跟踪器中进行跟踪,跟踪的结果会反馈到学习模块中,其次在学习模块中由于初始视频序列帧中存在要跟踪物体特征,就可以作为正样本,再通过相关方法选取些负样本训练检测器,这样在初始的时候检测器和跟踪器都有了相应的判决标准。接着就可以让视频序列流逐帧的通过检测器和跟踪器,当检测器和跟踪器得到跟踪结果后,一方面通过综合模块输出显示在相应位置,另一方面,他们又会作用学习模块,重新让学习模块训练检测器,始终保证检测器中跟踪目标的特征点在实时进行更新。在此过程中,学习模块中存在一个在线模型其作用是匹配每次通过跟踪器或检测器的图像片是否确实含有前景目标,其也是动态更新的。
下面分解讲述TLD算法框图中跟踪、检测、学习和综合模块的实现原理。
-----------------------------------------------------跟踪器---------------------------------------------
TLD使用Median-Flow追踪算法(光流跟踪器)。假设一个“好”的追踪算法应该具有正反向连续性(forward-backward consistency),即无论是按照时间上的正序追踪还是反序追踪,产生的轨迹应该是一样的。作者根据这个性质规定了任意一个追踪器的FB误差(forward-backward error):从时间t的初始位置x(t)开始追踪产生时间t+p的位置x(t+p),再从位置x(t+p)反向追踪产生时间t的预测位置x`(t),初始位置和预测位置之间的欧氏距离就作为追踪器在t时间的FB误差。
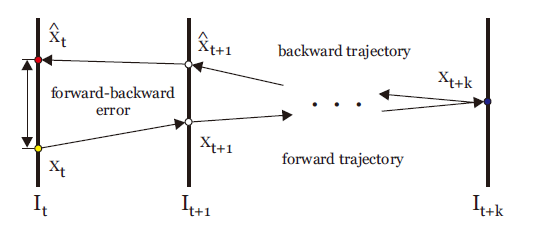
在光流法中为了处理三维空间中的目标物体的问题,它先将运动目标从三维空间映射到二维平面上,计算像素运动的瞬时速度,然后根据图像序列相邻两帧中像素点值在时域上的强度变化和相关性来确定图像中物体目标运动到下一帧情况,最终发现目标运动信息。只需要知道给定若干追踪点,追踪器会根据像素的运动情况确定这些追踪点在下一帧的位置。追踪点的选择:作者给出了一种依据FB误差绘制误差图(Error Map)筛选最佳追踪点的方法,但并不适用于实时追踪任务,就不详细介绍了。这里只介绍在TLD中确定追踪点的方法。首先在上一帧t的物体包围框里均匀地产生一些点,然后用Lucas-Kanade追踪器正向追踪这些点到t+1帧,再反向追踪到t帧,计算FB误差,筛选出FB误差最小的一半点作为最佳追踪点。最后根据这些点的坐标变化和距离的变化计算t+1帧包围框的位置和大小(平移的尺度取中值,缩放的尺度取中值。取中值的光流法,估计这也是名称Median-Flow的由来吧)。

还可以用NCC(Normalized Cross Correlation,归一化互相关)和SSD(Sum-of-Squared Differences,差值平方和)作为筛选追踪点的衡量标准。作者的代码中是把FB误差和NCC结合起来的,所以筛选出的追踪点比原来一半还要少。
NCC:
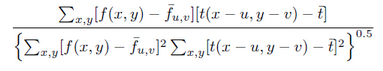
SSD:

-----------------------------------------------------学习模块---------------------------------------------
TLD使用的机器学习方法是作者提出的P-N学习(P-N Learning)。P-N学习是一种半监督的机器学习算法,它针对检测器对样本分类时产生的两种错误提供了两种“专家”进行纠正:(PN学习可参考:http://blog.csdn.net/carson2005/article/details/7647519)
P专家(P-expert):检出漏检(false negative,正样本误分为负样本)的正样本;
N专家(N-expert):改正误检(false positive,负样本误分为正样本)的正样本。
样本的产生:
用不同尺寸的扫描窗(scanning grid)对图像进行逐行扫描,每在一个位置就形成一个包围框(bounding box),包围框所确定的图像区域称为一个图像元(patch),图像元进入机器学习的样本集就成为一个样本。扫描产生的样本是未标签样本,需要用分类器来分类,确定它的标签。
如果算法已经确定物体在t+1帧的位置(实际上是确定了相应包围框的位置),从检测器产生的包围框中筛选出10个与它距离最近的包围框(两个包围框的交的面积除以并的面积大于0.7),对每个包围框做微小的仿射变换(平移10%、缩放10%、旋转10°以内),产生20个图像元,这样就产生200个正样本。再选出若干距离较远的包围框(交的面积除以并的面积小于0.2),产生负样本。这样产生的样本是已标签的样本,把这些样本放入训练集,用于更新分类器的参数。下图中的a图展示的是扫描窗的例子。
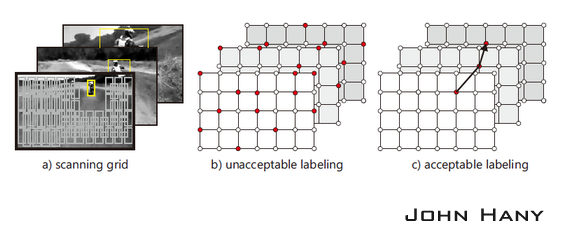
作者认为,算法的结果应该具有“结构性”:每一帧图像内物体最多只出现在一个位置;相邻帧间物体的运动是连续的,连续帧的位置可以构成一条较平滑的轨迹。比如像上图c图那样每帧只有一个正的结果,而且连续帧的结果构成了一条平滑的轨迹,而不是像b图那样有很多结果而且无法形成轨迹。还应该注意在整个追踪过程中,轨迹可能是分段的,因为物体有可能中途消失,之后再度出现。
P专家的作用是寻找数据在时间上的结构性,它利用追踪器的结果预测物体在t+1帧的位置。如果这个位置(包围框)被检测器分类为负,P专家就把这个位置改为正。也就是说P专家要保证物体在连续帧上出现的位置可以构成连续的轨迹;
N专家的作用是寻找数据在空间上的结构性,它把检测器产生的和P专家产生的所有正样本进行比较,选择出一个最可信的位置,保证物体最多只出现在一个位置上,把这个位置作为TLD算法的追踪结果。同时这个位置也用来重新初始化追踪器。

比如在这个例子中,目标车辆是下面的深色车,每一帧中黑色框是检测器检测到的正样本,黄色框是追踪器产生的正样本,红星标记的是每一帧最后的追踪结果。在第t帧,检测器没有发现深色车,但P专家根据追踪器的结果认为深色车也是正样本,N专家经过比较,认为深色车的样本更可信,所以把浅色车输出为负样本。第t+1帧的过程与之类似。第t+2帧时,P专家产生了错误的结果,但经过N专家的比较,又把这个结果排除了,算法仍然可以追踪到正确的车辆。
-----------------------------------------------------检测模块---------------------------------------------
检测模块使用一个级联分类器,对从包围框获得的样本进行分类。级联分类器包含三个级别,如下图所示:

图像元方差分类器(Patch Variance Classifier)。计算图像元像素灰度值的方差,把方差小于原始图像元方差一半的样本标记为负。论文提到在这一步可以排除掉一半以上的样本。
集成分类器(Ensemble Classifier)。实际上是一个随机蕨分类器(Random Ferns Classifier),类似于随机森林分类器(Random Forest:参考:http://www.cnblogs.com/liuyihai/p/8309019.html),区别在于随机森林的树中每层节点判断准则不同,而随机蕨的“蕨”中每层只有一种判断准则。
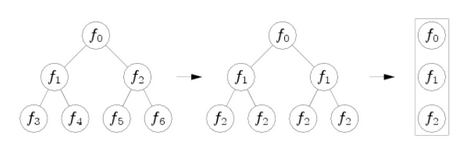
如上图所示,把左面的树每层节点改成相同的判断条件,就变成了右面的蕨。所以蕨也不再是树状结构,而是线性结构。随机蕨分类器根据样本的特征值判断其分类。从图像元中任意选取两点A和B,比较这两点的亮度值,若A的亮度大于B,则特征值为1,否则为0。每选取一对新位置,就是一个新的特征值。蕨的每个节点就是对一对像素点进行比较。
比如取5对点,红色为A,蓝色为B,样本图像经过含有5个节点的蕨,每个节点的结果按顺序排列起来,得到长度为5的二进制序列01011,转化成十进制数字11。这个11就是该样本经过这个蕨得到的结果。

同一类的很多个样本经过同一个蕨,得到了该类结果的分布直方图。高度代表类的先验概率p(F|C),F代表蕨的结果(如果蕨有s个节点,则共有1+2^s种结果)。
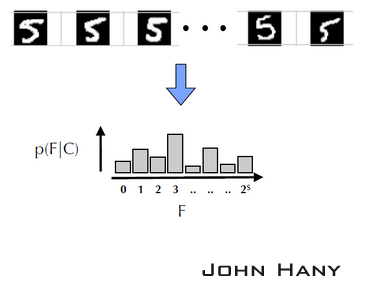
不同类的样本经过同一个蕨,得到不同的先验概率分布。
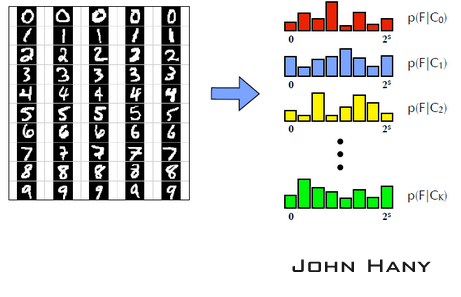
以上过程可以视为对分类器的训练。当有新的未标签样本加入时,假设它经过这个蕨的结果为00011(即3),然后从已知的分布中寻找后验概率最大的一个。由于样本集固定时,右下角公式的分母是相同的,所以只要找在F=3时高度最大的那一类,就是新样本的分类。
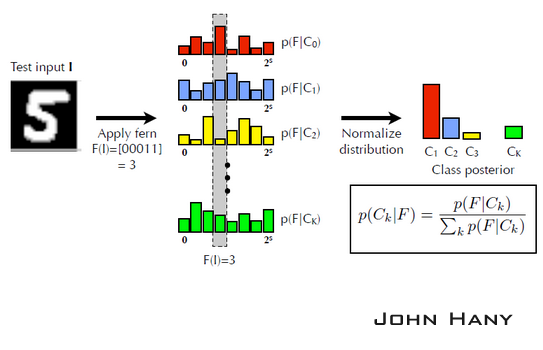
只用一个蕨进行分类会有较大的偶然性。另取5个新的特征值就可以构成新的蕨。用很多个蕨对同一样本分类,投票数最大的类就作为新样本的分类,这样在很大程度上提高了分类器的准确度。
最近邻分类器(Nearest Neighbor Classifier)。计算新样本的相对相似度,如大于0.6,则认为是正样本。相似度规定如下: 图像元pi和pj的相似度,公式里的N是规范化的相关系数,所以S的取值范围就在[0,1]之间,
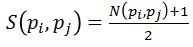
正最近邻相似度,
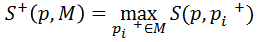
负最近邻相似度,
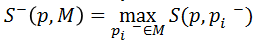
相对相似度,取值范围在[0,1]之间,值越大代表相似度越高,
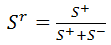
所以,检测器是追踪器的监督者,因为检测器要改正追踪器的错误;而追踪器是训练检测器时的监督者,因为要用追踪器的结果对检测器的分类结果进行监督。用另一段程序对训练过程进行监督,而不是由人来监督,这也是称P-N学习为“半监督”机器学习的原因。
-----------------------------------------------------综合模块---------------------------------------------
综合模块是跟踪、检测结果汇总输出。检测模块会影响到跟踪模块的最终结果,没有跟踪到目标也有可能最终通过检测模块得到目标框,跟踪模块和检测模块共同定位输出的跟踪目标框位置。
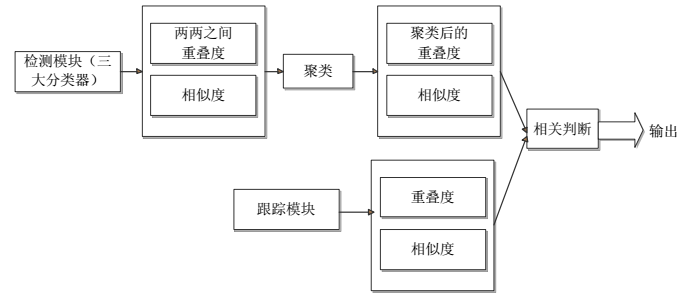
上图 是 TLD 算法综合模块的处理框架。首先, 求得所有通过的检测模块(就是成功通过三大分类器后的)的矩形框两两之间的重叠度和其相似度, 然后将重叠度和相似度进行聚类[32]得到聚类后的重叠度与相似度,将此结果保存;其次,求出跟踪模块的重叠度与相似度,将结果予以保存。最后对两个结果进行比对,综合相关条件进行判断,从而输出最后定位的目标框位置。
综合模块将跟踪与检测模块的结果予以汇总判断, 完成定位跟踪目标的边界框。按照检测模块能否检测成功,跟踪模块是能否跟踪成功的原则, 两两进行组合。会有四种情况, 即就是跟踪成功检测成功; 跟踪成功检测失败; 跟踪失败检测成功;跟踪失败检测失败。 下面分别对四种情况一一分析:
(1) 跟踪成功检测成功
检测成功指的是至少有一个滑动窗口通过检测模块,所以根据通过通过检测的滑动窗口数量,分为三种情况考虑。一是,如果通过后只有一个矩形框,不进行聚类,直接计算相关相似度,得到的信息直接进入信息综合判定处。二是,如果通过后有两个矩形框,则首先计算两个矩形框的重叠度,再计算相似度,最后将他们的结果聚类输出到信息综合判定处。三是, 如果通过后的矩形框多于两个,则分别计算窗口两两之间的重叠度,按照重叠度与阈值的关系将其分为多个等价类。为了便于理解,特举一实例。如果此时通过检测模块后有七个矩形框,通过计算两两间的重叠度并与阈值相比较,发现 1,2,3 是一类计为 A 类, 4,5 是一类计为 B 类, 6,7 是一类计为 C 类,这个过程就完成了聚类。然后统计出 A 类、 B 类、C 类的相关信息,如坐标信息,高度、宽度,保守相似度等。对于每一种类型信息求其平均值作为最终的参数值保存输出到信息综合判定处。另一方面,跟踪模块也有通过的矩形框。计算通过检测模块的矩形框与通过跟踪模块的矩形框的重叠度。如果重叠度很小但是通过检测模块矩形框的保守相似度大于通过检测模块矩形框的保守相似度,这时候认为寻找成功了一个聚类中心离跟踪模块得到的矩形框距离较远但是比跟踪模块更加可信。这时候重新用检测模块的那个矩形框的参数重新初始化跟踪器,并输出定位目标。如果重叠度很大则将通过检测模块的矩形框和通过跟踪模块的矩形的信息值按照权位值累加方式
求其平均值,其中跟踪模块占据的比重大,检测模块占据的比重小,即就是检测模块辅助纠正跟踪模块定位的矩形框。总之,如果有跟踪到目标框并检测到目标框,那么对检测到的结果聚类得到相关输出结果,判断聚类中心与跟踪器的重叠率和可信度,如果两者重叠度低且检测模块的可信度更高,那么用检测模块的结果修正跟踪模块的结果,也即用检测器修正跟踪器;如果重叠率接近,那么用检测器和跟踪器结果加权平均得到结果作为最终输出结果,其中跟踪器的权重更大。
(2) 跟踪成功检测失败
如果特征矩形框通过模块跟踪后,跟踪成功。但是检测器分类后没有矩形框,这时候认为跟踪成功,直接将跟踪成功的矩形框输出作为最终的定位目标框的参数。
(3) 跟踪失败检测成功
如果跟踪模块跟踪失败,但是通过检测模块有至少一个矩形框检测成功。 将检测模块的矩形框进行聚类,如果最终聚类的结果只有一个聚类中心,则用此聚类的结果重新初始化跟踪模块,并将聚类的结果作为定位输出结果。如果聚类中心有多个,说明虽然通过了检测器,但是有多个不同的位置,也认为检测失败,
不输出结果。
(4)跟踪失败检测失败
如果跟踪和检测模块均失败了,则认为此次检测之间无效,丢弃。综上所述,对于综合模块,其实就是用跟踪模块和检测模块的结果进行综合考虑,前提是检测器有检测到目标框的结果,对目标框进行聚类得到聚类结果,然后根据跟踪器的结果的情况来分析: 如果根据模块跟踪的结果存在存在,观察跟踪模块与检测模块聚类后的重叠率,如果重叠率低但是检测模块的可信度高,用检测模块聚类后的结果去修正跟踪模块的参数;如果重叠率接近,将跟踪模块的结果和检测模块聚类后加权平均得到当前帧跟踪结果的输出结果,但是跟踪器权重较大;如果跟踪模块没有跟踪到目标框,看检测模块中聚类结果是否只有一个中心,是则以其为当前帧跟踪结果,如果不只一个中心则将聚类结果丢弃,当前帧没有跟踪到 。
- TLD算法单目标跟踪应用实例图
- TLD算法单目标跟踪源代码汇总
1. 原作者 Zdenek Kalal
作者主页: http://info.ee.surrey.ac.uk/Personal/Z.Kalal/
源代码页: https://github.com/zk00006/OpenTLD
源代码解释:http://www.cnblogs.com/liuyihai/p/8320279.html
编程语言:Matlab + C
2. Alan Torres版
源代码页:https://github.com/alantrrs/OpenTLD
实现语言:C++
3. arthurv版
源代码页:https://github.com/arthurv/OpenTLD
实现语言:C++
注:和上面的没有发现任何区别
4. jmfs版
源代码页:https://github.com/jmfs/OpenTLD
实现语言:C++
注:和上面两个没有区别,只不过加入了VS2010工程文件,理论上可以直接在Windows下编译通过。不过opencv检测不到作者的webcam(!!!),所以他用了另一个VideoInput类来handle摄像头输入。
5. Georg Nebehay版
源代码页:http://gnebehay.github.com/OpenTLD/
注1:这个的好处是提供可执行文件下载(Ubuntu 10.04和Windows)。BUT, as you would expect,基本上到了你的机器上都跑不了。还是自己老老实实build吧。
注2:这个版本需要安装Qt。不过好像作者关掉了Qt的选项(相关代码还在),所以可以编译,但无法显示结果
注3:CSDN下载上有个“openTLD Qt 版“,就是这个版本。不过加了VS的工程文件---在我的机器上还是不能PnP, don't bother
http://download.csdn.net/download/muzi198783/4111915
6. Paul Nader版(又一个Qt 版!)
QOpenTLD: http://qopentld.sourceforge.net/
源代码页: http://sourceforge.net/projects/qopentld/
注1:需要OpenCV和Qt。 原系统要求Qt 4.3.7OpenCV 2.2。
注2:Windows和Linux下都提供了编译工程或makefile。估计也是唯一一个移植到Android平台下的TLD!
7. Ben Pryke版(又一个student project!)
源代码页:https://github.com/Ninjakannon/BPTLD
注:依然是Matlab+C/C++的混合实现。亮点是有很详细的Documentation(8页),介绍了算法的理解和实现细节。可以帮助理解原算法
- TLD算法参考文献
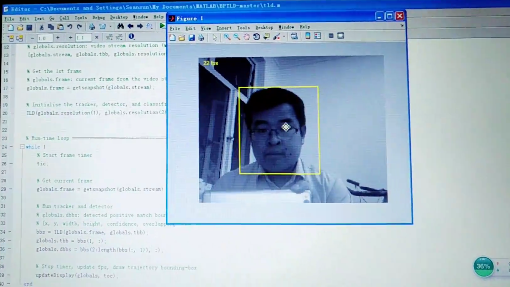
- TLD视频目标跟踪演示视频
智能监控--人脸追踪演示: http://www.miaopai.com/show/-jjAqUFr2mGP5VKdDZtarPtQy2WGFb3ypx-WXA__.htm
动物状态监视--跟踪熊猫:http://www.miaopai.com/show/Y0LaonMwB79BBH9w6xUyA2qa1FfHafpEUjzJKg__.htm

无人作战--跟踪航拍小车:http://www.miaopai.com/show/Ty1j4VhViUuVDx7R5-JWGbmexh0cr6t-gTtf7A__.htm

能力测试--特定弱小目标跟踪:http://www.miaopai.com/show/CvDoyN2UFW-VXojMERQyE6MTkOY-0Cpa2vfkfQ__.htm

- TLD算法安装及运行答疑
联系:liuyihai@126.com liuyihai@aliyun.com
- 博文预告
下一篇博文将详细讲述将TLD算法用于视频多目标跟踪情形-----欢迎阅读

 浙公网安备 33010602011771号
浙公网安备 33010602011771号