2015.07.20MapReducer源码解析(笔记)
MapReducer源码解析(笔记)
第一步,读取数据源,将每一行内容解析成一个个键值对,每个键值对供map函数定义一次,数据源由FileInputFormat:指定的,程序就能从地址读取记录,读取的记录每一行内容是如何转换成一个个键值对?Mapper函数是如何调用键值对?这是由InputFormatClass完成的,它在我们的例子中的具体实现类是TextInputFormat(Text是普通的文本,log日志,数据库中的数据就不是),总的来说:TextInputFormat把数据源中的数据解析成一行行记录,每一行记录对应一个键值对。
它是如何将数据源解析成一个个键值对?点击TextIuputFormat

解析:这个InputFormat用于plain text files,文件被切成一行行,linefeed行结束那块作为结束符。
Keys是在文件中的位置,values是文本内容。可以看出,TextInputFormat解析出来的<k,v>对的类型是<postion,line value>对应的类型是<LongWritable, Text>.由此可确定,如果我们的程序中使用的是TextInputFormat,那么<k1,v1>的类型<LongWritable, Text>被定死了。(我们会指定mapper的<k2,v2>输出的类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);会指定reduce的<k3,v3>的输出类型,却没有指定<k1,v1>的类型).

TextInputFormat继承了FileInputFormat,使用的泛型(泛型是JavaSE1.5的新特性,其本质是参数化类型,也就是说所操作的数据类型被指定为一个参数,好处是安全简单)是<LongWritable, Text>,当无法弄清其作用是,看他的父类FileInputFormat。

 FileInputFormat<k,v>继承InputFormat<k,v>他是个泛型,点进InputFormat查看,其职责是:描述了Map-Reduce job输入的规范,这个Map-Reduce 框架依赖InputFormat来完成以下任务:1、Validate(校验)作业的input-specification(输入规范)(输入源是空或否,输入的路径是否正确)2、Split-up(切分)输入的文件(复数)成逻辑的输入切片(InputSplit),每个切片(InputSplit)都会赋给an individual(单独的)Mapper任务。
FileInputFormat<k,v>继承InputFormat<k,v>他是个泛型,点进InputFormat查看,其职责是:描述了Map-Reduce job输入的规范,这个Map-Reduce 框架依赖InputFormat来完成以下任务:1、Validate(校验)作业的input-specification(输入规范)(输入源是空或否,输入的路径是否正确)2、Split-up(切分)输入的文件(复数)成逻辑的输入切片(InputSplit),每个切片(InputSplit)都会赋给an individual(单独的)Mapper任务。
job数据源的一系列输入文件与InputSplit的数量是一一对应的吗?不是的。
还提供了RecordReader的implementation(实现),to be used to(用于)从逻辑的InputSplit中 glean(抽取)输入记录,用于被Mapper处理。
InputFormat的作用:
(1)把一系列输入文件切分成一个个的InputSplit,每一个InputSplit被一个独立的mapper任务处理:(对hdfs处理的)
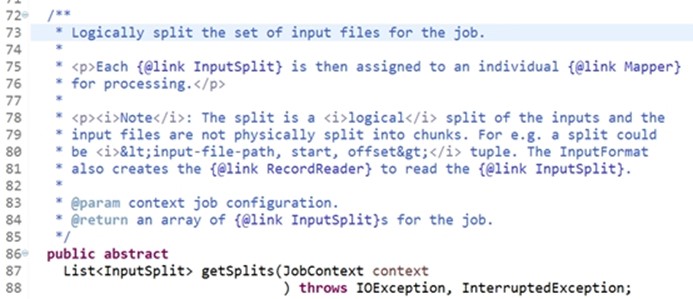
public abstract List<InputSplit> getSplits(JobContext context);
(2)提供一个RecordReader的实现类,拆分数据成一个个的<k,v>对,供mapper处理:(对Inputsplit处理)
public abstract RecordReader<K,V> createRecordReader(InputSplit split,TaskAttemptContext context);
如何设计InputFormat类的?提供两个方法:1、getSplits:对输入作业的集合进行切分,切分成<InputSplit>;2、createRecordReader:创建一个record reader给split用,


InputFormat提供的这两个函数是如何实现的?
其中一个实现类 FileInputFormat<K, V>,它也带泛型,来至于
InputFormat的createRecordReader类。FileInputFormat只实现了getSplits,
产生一系列的输入文件,将他们拆分成一个个FlieSplits,FileSplits,而函数返回值是List<InputSplit>,由此可知FileSplits和InputSplit是继承关系。看这种复杂的函数(超过一屏的函数),找返回值 return splits,它是个列表List<InputSplit> splits,只需关注split的add方法,因为split是个列表,列表中的元素对getSplit函数的调用者才有意义,其函数体内不断调用add方法把具体数值放到这里面。


它的add方法的形参都调用了函数makeSplit,他还是在FileInputFormat类里面
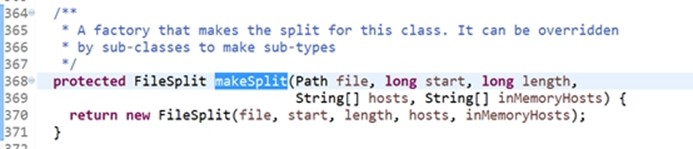

这是一个工厂,他会产生split给这个类。可以被子类覆盖用于此类型。Add的元素就是一个个InputSplit,InputSplit是由makesplit函数产生,函数是调用new FileSplit产生的,public abstract List<InputSplit> getSplits(JobContext context);getSplits的返回值里面的元素都是一个个的FileSplit对象,点击FileSplit可以看到它是一个构造函数。
FileSplit继承了InputSplit,是其子类,实现了Writable的接口(实现序列化)

点击InputSplit,它是个抽象类,其方法有getLength()、getLocations()、getLocationInfo()

InputSplit包含的数据会被单独的Mapper任务处理,Mapper任务的最直接的数据来源是InputSplit。Typically(通常地)它表示是使用字节定位的view(视图),在输入中,它是RecordReader的责任,用于处理InputSplit,还表示基于行的视图(使用字节、行度量)。



获得split的长度,还获得所在所在位置的节点的名称,节点的信息
 FileSplit表示输入文件的一部分,输入文件就是单词计数的文件,指的是文件的一部分,它的字段有5个,length指的是InputSplit长度(size尺寸),也就是InputFile中一段数据的长度,hosts存放数据节点的位置。
FileSplit表示输入文件的一部分,输入文件就是单词计数的文件,指的是文件的一部分,它的字段有5个,length指的是InputSplit长度(size尺寸),也就是InputFile中一段数据的长度,hosts存放数据节点的位置。

多个add方法是由于所在if条件的不同,产生的FileSplit有哪些条件产生的?每个if条件限定了文件的内容,
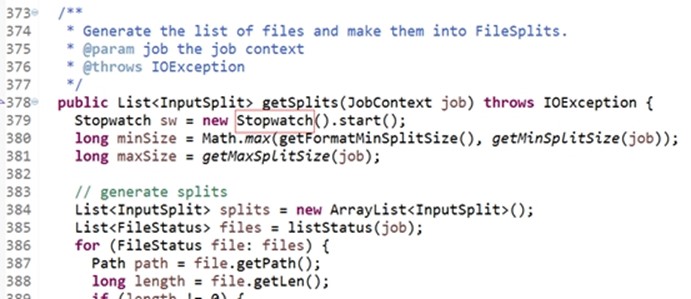
 Stopwatch()是一个秒表,划分多少个split用了多长时间作用
Stopwatch()是一个秒表,划分多少个split用了多长时间作用
变量minSize由数学中的max取最大值函数产生,取getFormatMinSplitSize(), getMinSplitSize(job)两个值的最大值,作用求 maxSize

返回值直接就是1。

它要获取配置文件参数SPLIT_MINSIZE的值,如果在配置文件中找不到取默认1,是哪个参数值

找input.fileinputformat.split最小的尺寸,如果配置值就不是一,MapReduce没有配置SPLIT_MINSIZE的值,默认为一,所以 long minSize=1

含义就是,切分split时,它的长度可变的,但是有下限1,配置 getMinSplitSize(job)文件中配置为变量值为1M即可改为1M,保证不小于1(所以与参数1比较),为什么常量1不直接使用而用getFormatMinSplitSize()函数,实际上是便于子类覆盖。


如果取不到,就取 Long.MAX_VALUE的最大值,配置文件没有配置,所以取long的最大值,
2^63-1,size大小动态修改

产生split,是一个 ArrayList<InputSplit>(),listStatus方法(在FileSystem中是获取文件内容),找出所有的job输入文件
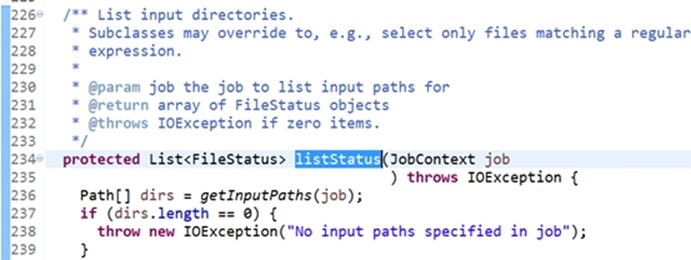
列出输入目录,下面的过程是用于迭代目录的。如果我们的输入文件不是hello,而是一个目录,还有子目录也是可以的,调用某个方法。通过listStatus把所有的输入文件都列出来,包括子目录中的文件,接下来就遍历每个文件,用for循环,一个输入文件与一个INputSplit关系是什么。

file.getPath()获取文件的路径,file.getLen()获取文件的长度,if文件长度不等于0,else文件长度等于0(touchz创建的空白文件)

创建一个空的hosts数组给0字节长度的文件,makeSplit的形参path是文件的位置,0,文件的长度, new String[0]就是empty hosts array文件所在的数组,大小为0。数字0是什么意思,点击makeSplit看看!

Start指的是文件的起始位置,空的文件起始位置是0,长度也是0,。
当length不等于0时,
isSplitable可拆分的,先看not splitable不允许切分,这个输入文件不能被切成一块块,(数据库中产生的网络日志是一行行的,将其切成一块块还能读取,不能切指的是压缩文件不能切分,切分后无法打开解析)

传递的第二个形参是0,第三个length最大是long max(理论值), blkLocations[0].getHosts()获得的是文件所在节点的信息,
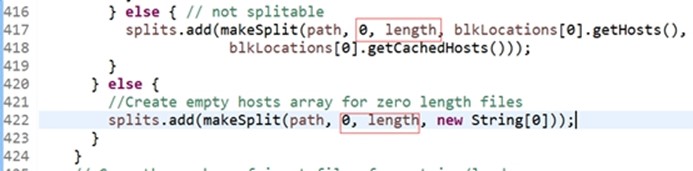
不能被切分和能被切分的传递的参数都是0,length,不能被切分length大于0,能被切分大小为0

如果被切分,就会切分成一个个split,多大的值被切分成一个split?
splitSize是通过computeSplitSize(blockSize, minSize, maxSize)函数计算出来的,这个函数传递三个形参,blockSize(默认是128M), minSize(最小值是1), maxSize(long的最大值)点进去看一下功能

求最小值(long的最大值,128M),128M小,然后取最大值(1,128M),取的是128M,默认情况下,函数的返回值是128M,split size默认是128M。
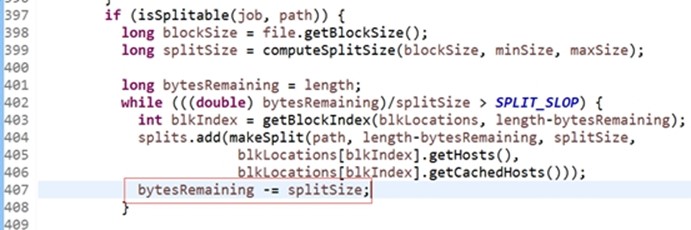
文件的长度length送给了bytesRemaining(字节剩余)这个变量。第一次进入while循环的时候, 形参length-bytesRemaining(length减去bytesRemaining,length-length)为0,splitsize是128M, bytesRemaining -= splitSize;执行后, bytesRemaining 比splitSize减少128M,第二次循环时length-bytesRemaining为128M(length-length+128M),splitsize是128M;假设length=500M,split(0,128M)、split(128M,128M)、split(256M,128M)。默认情况下,一个文件可以切分成多个InputSplit哪?答:length%splitSize==0?length/splitSize:length/splitSize+1,如length=128M,一个split,length=129M,2个split,输入文件们被切分成一个个split。文件大小为0可切分,一个split,文件大小不为0不可切分,一个split,文件大小不为0,可切分至少一个split。
输入文件的数量与InputSplit的个数,是什么关系?
答:一个输入文件至少产生一个inputsplit
在输入文件中,有一个文件大小为1k,另一个为0k,会产生2个split,一个split对应一个Mapper人,就会有2个Mapper任务。
createRecordReader方法实现什么作用?
提供了一个RecordReader的实现类,用于抽取input record供mapper处理,FileInputFormat找不到createRecordReader,可以查看它的子类TextInputFormat。
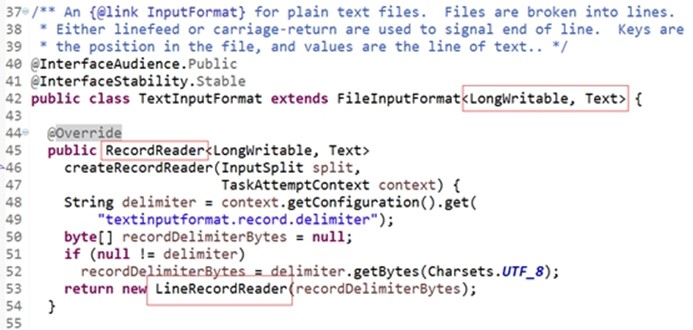
在TextInputFormat 类中它的泛型已经被定死了<LongWritable, Text>, 里面有个被覆盖的 RecordReader方法。其实现很简单,.record.delimiter记录的分隔符(-r -n),分隔符可以自己指定的,返回值是 LineRecordReader,查看。
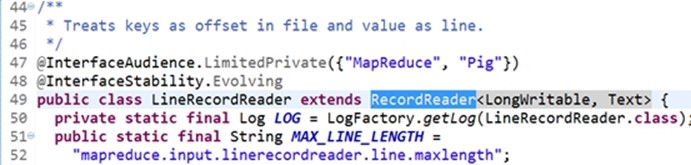
LineRecordReader类继承了RecordReader类,再点击查看。
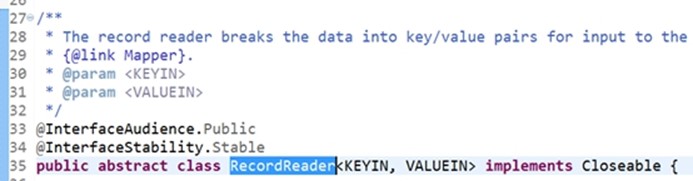
RecordReader的实现类它是记录的读取器,会将数据break into(拆分成)键值对,供mapper处理。 其里面有(对我们的逻辑有影响的)Initialize、nextKeyValue getCurrentKey 和getCurrentValue getProgress(获得当前进度的,不重要的,要学会看) close(关闭,不重要的)这些方法。RecordReader是抽象类,需要看其具体的实现, LineRecordReader。
每个文件产生至少一个InputSplit,每一个InputSplit被job的一个独立的mapper处理,每个InputSplit有128M的长度。也就是说,job每个mapper处理0至128M的内容。

重要的字段:Start表示起始位置,pos表示当前的位置,end 表示最终位置,SplitLineReader会读取一行内容(自定义行的分隔符),读取split内容需要循环读取。
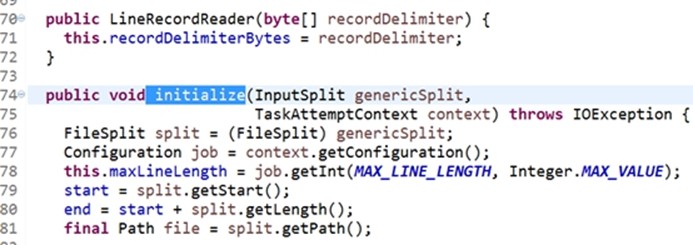
不重点: initialize方法,在这个类里面初始化后首先执行它,会产生一个split,然后会得到split的start位置( start = split.getStart();单位是字节,可能为0,不可能为负数),会得到 end = start + split.getLength();(如果start=122,end=122+128)


Start会读记录,不赋值时默认是起始位置: start = split.getStart();将start的值赋给pos(this.pos=start;)。(hello you hello me)在划分split时,只划分一个split(数据量小不够128M),这个split的start是0,pos值也是0.
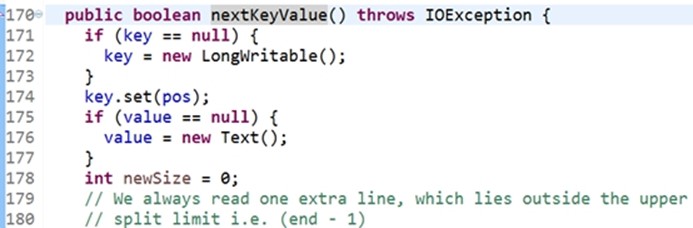
分析重点:当key等于空的时候,我们new一个LongWritable,可以赋一个值是pos,第一次进入nextKeyValue时,pos的值是0。如果value是空的就赋一下值。

newSize等于 in.readLine,切片行的读取器,readLine是读取一行,value,newSize是怎么用?点击readLine

Value就是Text str,str这个对象存储一行,是被赋值的,赋值的方法就是下面的两个方法。
if (this.recordDelimiterBytes != null)如果这个字段不等于空的, readCustomLine用户自定义的,如果为空的(用户没有输入值),readDefaultLine使用默认的。只关注str和return返回值的意思:


读取一行的结束符,是CR、LR,return值是字节被消耗的(被读取的), bytesConsumed 作用是+= readLength;它位于do while语句当中(不分析里面的内容),bytesConsumed 的数值在不断增加 readLength被读取的量,被读取的量是 bufferPosn位置 - startPosn位置
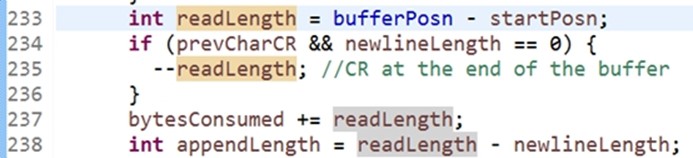
readLength指的是被读取的字节量, bytesConsumed指代的是一共读取了多少字节,


str.append指的是向str填值,当前行的数据被写入到str中,行是由CR、LR(search for newline信号标识符)决定的,

CR, LF, or CRLF都综合了Linux和windows下面的分隔符,进行数据时是一行行读取,读取的内容放到第一个形参str当中,读取了多少字节放到返回值int中,也就是说 in.readLine读取一行的内容放到value中。
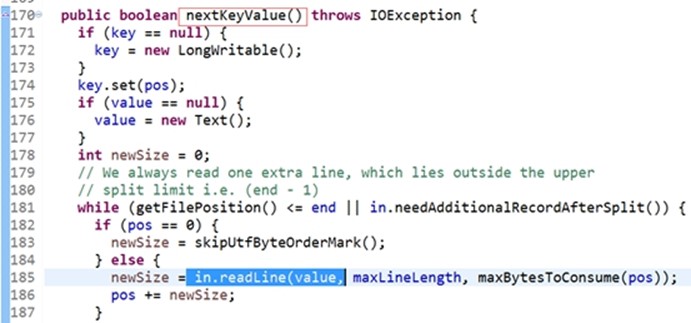

第一次进入while循环当中时,key=0,value=hello you,Pos的值变为10(9个字节+换行符1个字节),第二次调用 nextKeyValue函数时,key的值就是pos的值等于十,value=hello me,

第三次不能进入if判断,因为没有内容了,找的文件位置大于end。通过不断的调用nextKeyValue,就可以获得一个个键值对,怎么读取键值对?就需要调用

getCurrentKey getCurrentValue,也就是说每次调用while(nextKeyValue()){就需要调用
getCurrentKey();
getCurrentValue();
}立即将读取的键值取出来。取出来给谁使用?Mapper函数是如何调用键值对?
自定义的函数是MyMapper,有map方法,覆盖了其业务逻辑,实现了单词计数的功能,每次调用map每次调用的键值对就是以上分析的值,是如何到达map形参的。需要找到它的父类,
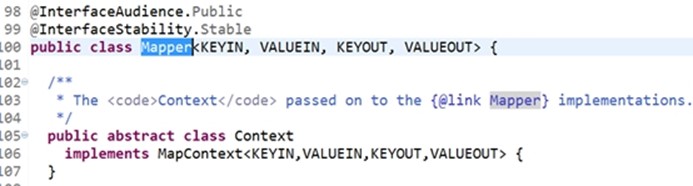

把输入的键值对映射成中间的(临时的)一系列键值对,把输入的<k1,v1>转换成<k2,v2>

context实现了 MapContext 接口,是上下文的意思,setup是任务刚开始的时候调用一次

cleanup是任务结束的时候调用一次。有点像C++里面的构造函数和析构函数,java里面filter的inni和distro方法。任务执行时执行的是 map方法

每个键值对都会调用一次,输入的key、value从哪里来还不清楚?
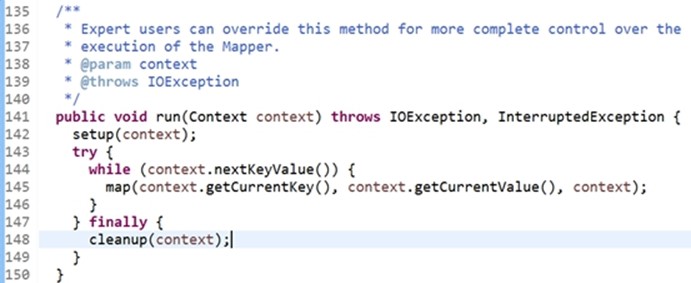
run函数有个setup方法,传的是context,上面的Context类,try里面有个while循环,循环调用map函数,finally里面有个cleanup。While的结构与之前的结构一样,只需判定context.nextKeyValue调用的是RecordReader的nextKeyValue。查看

MapContextImpl是一个实现类,继承了 TaskInputOutputContextImpl实现了 MapContext接口,
该接口和Mapper类中的Context实现的是同一个接口

在 MapContextImpl里面有个 reader,是new它的时候传进来的,它是 RecordReader类型

在下面调用 getCurrentKey实际上是调用reader.getCurrentKey,同样的,实际上是调用 reader.getCurrentValue,实际上是调用reader.nextKeyValue
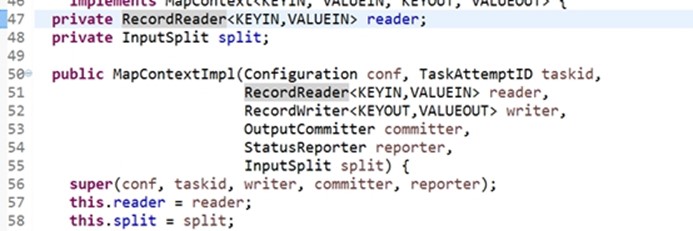
如果想知道RecordReader抽象类具体是哪一个类,可以从调用其方法的函数MapContextImpl来寻找,这个函数是通过反射调用的不是new出来的。
InputFormat将hdfs中的数据切分成InputSplit解析出一个个键值对供Mapper函数调用,
自定义Mapper函数实现业务逻辑,

文件每一行都有一个数字,寻找文件中数字最大值,MapReduce如何实现?和Mapper类中的某个函数有关<k1,v1>中的v1就是数字,Mapper函数对取的是每一行的内容,每一行调取Mapper函数,在Mapper函数之外定义一个变量,就可以比较行的内容。
分区的目的就是将相同分类的键值对<k,v>分给同一个reduce处理
为什么将相同分类的<k,v>交给同一个reduce处理?
(统计不同省上百万的的高考成绩,Mapper是划分省,每个省交给一个reduce处理,实现并行计算,分布式计算。根据业务需要,可实现分布式计算)
分类的标准是什么?怎么分类?
正常情况下,分区标识的数量和reducer任务的数量是一样的。
默认分区的数量是一个,reduce只有一个,其中省略了代码job.setNumReduceTasks(tasks);。意思是指定reduce的数量。分区的意思就是指定reduce数量

可以自己设定,如果没设定,其默认值是1。分区的标准有自定义分区函数实现的,系统提供一个默认的分区函数job.setPartitionerClass(HashPartitioner.class);

numReduceTasks的默认值是一,key.hashCode()是k的hash值整数, Integer.MAX_VALUE是非负整数,非负整数%1是0。 getPartition的返回值是0,0如同数组中的索引,对应的reduce只有一个,如果返回值是0、1、2,就会有3个reduce任务,返回的标识012,4个reduce也可以,其中一个reduce什么都不做。
(如何划分标识,省判卷例子Partion划分出34省,标识是0-33(返回值只能是int)<k2省,v2分数>,建立一个枚举类型(Enum),Enum.bj=0;Enum.tj=1就可以得到0-33的下标;或者是List<String>填的是所有省的省,比如进来的是北京,看其下标)
public class MyPartitioner<k,v> extends Partitioner<k,v>{
public int getPartition(k key,v value,int numReduceTasks)
{
return (key.hashCode()&Integer.MAX_VALUE)%numReduceTasks;
}
}
(省内的市,镇太多,k2表示地级市,k3表示省,)
重要提示:分组的标准和分区的标准是不一样的。private Map<地级市,省>,建立一个省的List,从中取出下标。分组是按照k2分,分区不是(1.3)。每个区中的数据单独进行排序和分组,排序和分组是系统做的,我们只能干涉排序标准和分组方式,默认是按照k2进行排序分组,可自定义排序的标准,分组也可以覆盖(参考第七期),自定义排序分组工作中会有。(1.4)
(1.5规约也是reduce)Mapper是预处理,数据的数量不一定减少,可能会增加,Mapper出来了一部分数据,一些符合后面将要执行的reduce业务的要求,可不可以在Mapper阶段执行reduce函数(数据量就可以变小),mapper的数据量就可以变小了。Reduce算法会作用所有的mapper输出,数据需要送到reduce,把reduce业务前移到每个mappe任务去执行

天龙八部中的1.5步,称作combiner,相当于renduce任务在map端的本地化。本地的reduce与后面的reduce区分开:这个框架名:job.setCombinerClass(Myreduce.class);(如之前传递<hello,1><hello,1>,使用combiner后,传输的是<hello,2>)
使用combiner的目的是减少网络传输的数据量,降低网络开销。
有些业务使用combiner后数据会出错,对数据量比较敏感的(求平均数)
shuffle,本意是洗牌。在MR中,指的是把map端的数据按照一定的标准(分区的标准)传输到reduce端的过程。Mapper指向shuffle的虚线就是分区的过程。2.2是框架做的,2.3是 job.setOutputFormatClass(TextOutputFormat.class)的TextOutputFormat
作业:自己查看FileOutputFormat和TextOutputFormat,回答一下问题:
(1)k3与v3直接的分隔符是什么?
(2)输出的文件名是如何命名的,可以自己修改命名规则吗?
int max=Long.MIN_VALUE
map (k1,v1){
If(v1>max)max=v1;
}
cleanup(context){
context.write(max)
}
cleanup在所有的Mapper函数执行完才执行,产生的最大值由reduce最终处理。
MapReduce输入的处理类
FileInputFormat:
FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类——TextInputFormat进行实现的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号