刘一辰的软件工程随笔
很容易发现,class为areaBox的 tr 标签中保存的是各省的数据,其中的area为省份名称,其余不包含class的 td保存的是疫情的各项人数,而class为 city 的tr中保存的是各个城市的数据,其中,area为城市名称,其余td保存的疫情各项的人数。
在这样的简单分析之后,顿时感觉这实在是太小儿科了,两个嵌套for循环就可以搞定,于是开始编写爬虫,初始测试爬虫代码如下:


import requests from bs4 import BeautifulSoup url = "https://news.qq.com/zt2020/page/feiyan.htm#/" r = requests.get(url) html = r.text soup = BeautifulSoup(html,"lxml") print(soup.prettify())
运行之后,打印数据是这样的
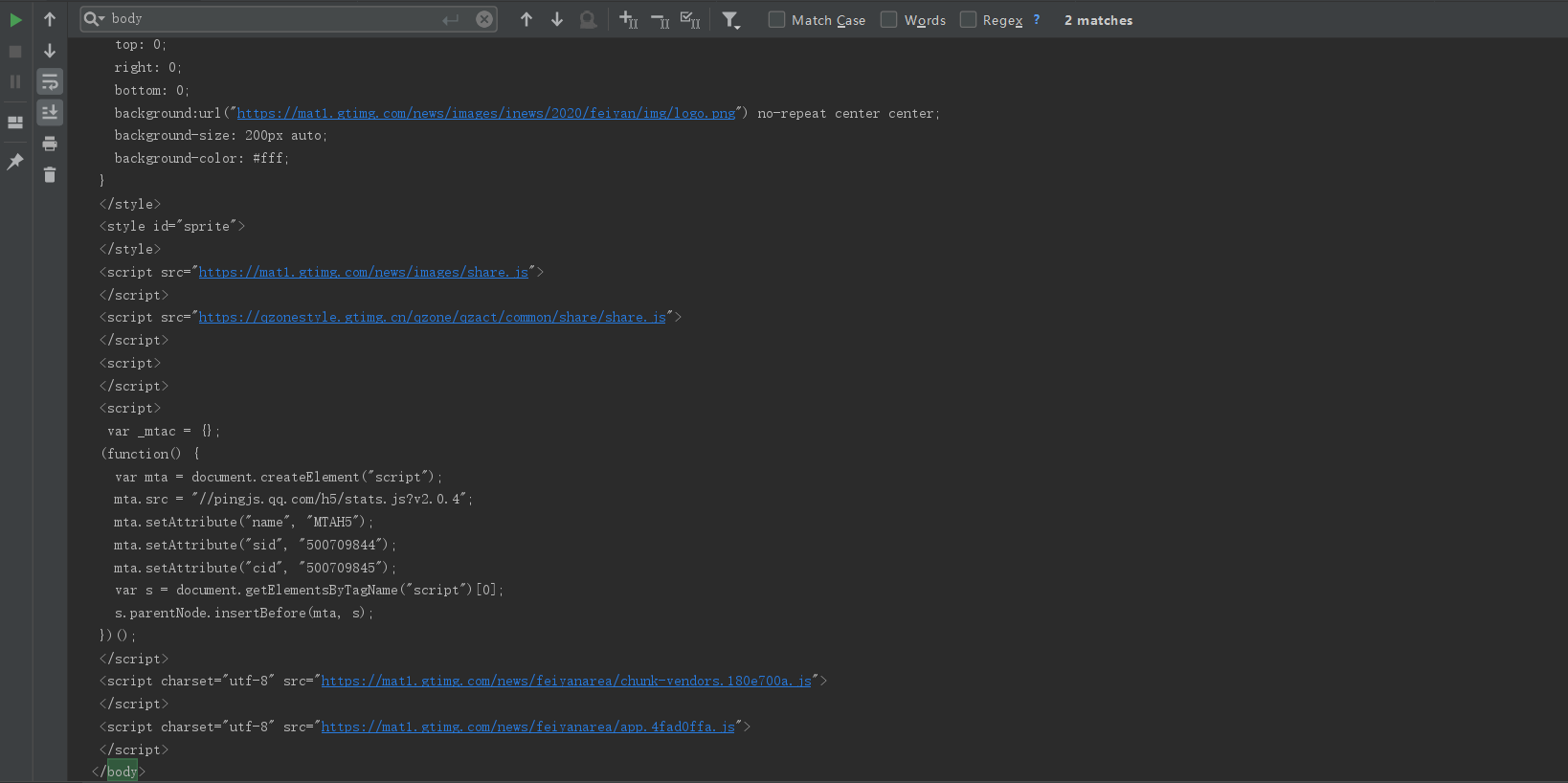
只有一坨 js 代码还有页面头部的几个div,并没有找到我们想要的标签。迟疑了一瞬间,恍然醒悟数据应该是通过js发送请求之后从后台传回来的。直接看这一段HTML代码,果然什么都看不出来。没办法,F12去浏览器控制台看看到底发生了什么数据交换的操作吧。(微软的浏览器用的有点鸡肋,这里切一下Chrome)可以看到服务器返回了这些数据:
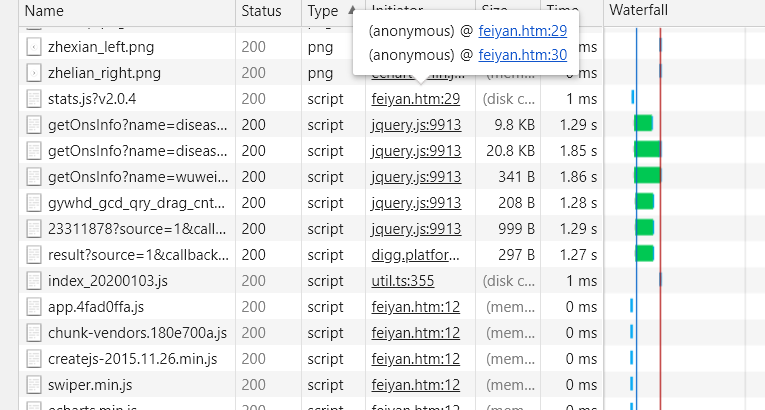
可以看到除了无关紧要的png图片等资源,还返回了这样一堆js文件,一看名字,这些get***Info可能就是我们需要的,检查一下它的地址,然后复制打开


瞬间激动了有木有!!这不就是现成的json数据么,还分析个球的HTML标签,直接爬起来!!!
(激动过头了)先分析一下json的格式和我们需要的“树”,首先可以看到开头有个name 中国的字样,由于该网站支持其他国家的数据,如下:
所以我们解析json的时候就要通过它来筛选本国的数据,那么,在中国下面,又有这样一些数据:
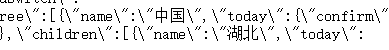


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2020-11-05 2020/11/05 刘一辰的JAVA随笔