
ZAB协议
一、ZAB协议简介
ZAB协议是Fast Paxos算法的一种工业实现。ZAB即原子广播协议,是一种专门为zookeeper设计的一种支持崩溃恢复的原子广播协议,在zk中,主要依赖ZAB实现分布式数据的一致性。
zookeeper使用一个单一的主进程处理客户端的事务写请求,当服务器状态发生变化后,集群采用ZAB协议以事务提案的方式广播到所有的副本进程上,ZAB为保证全局的序列变更,为每一个事务分配一个全局的递增编号xid。
在zookeeper集群中,对于任一节点,若客户端提交读请求,当前节点会根据自己保存的数据进行响应;若是写请求且当前节点不是leader,该节点会将写请求转发给leader,leade会以提案的方式广播该写操作,超过半数同意该操作,则提交写操作请求。然后leader再次广播所有订阅者(learner)同步数据。
二、ZAB中的概念
1、三类角色
当zk以集群方式出现时,zk中的集群有以下三种:
- Leader:zk集群中写请求的唯一处理者,他收到写请求后会先根据请求发出提议,大多数服务统一之后记性数据修改。同时,他还可以进行投票、发起决议,更新系统状态。
- Follower:接收客户的读请求,将结果返回客户端;将写请求转给leader;在选举中投票。
- Observer:无选leader投票权与写操作投票权的Follower,主要是为了协助Follower处理读请求。不能反馈ACK。
同时,者三种角色在不同情况下还有其他称呼:
- Learner:学习者,从Leader中同步数的server,一般来说,Follower与Observer相对于Leader合称Learner。
- QuorumServer:法定服务器,具有投票权的主机。在leader选举过程中参与选举与被选举的主机称为QuorumServer,不包括Observer,即Leader+Follower。
需要注意的是:
当一个集群中增加Follower会导致集群写性能变差
2、三种模式
ZAB中的zkServer有三种模式:恢复模式、同步模式、广播模式,他们相互交叉。
- 恢复模式:服务重启或Leader崩溃后进入恢复模式,恢复模式包含两个阶段:Leader选举阶段与初始化同步阶段。这两个阶段使zk恢复正常服务状态。
- 广播模式:广播模式分为两种:初始化广播与更新广播。Leader选举结束后,Leader将自己的epoch及自身拥有的但其他Server没有的事务广播给Learner,这是初始化广播。当集群正常时,当Leader事务提案被大多数Follower同意后,Leader会修改自身数据,并将修改后的数据广播给其他Learner,这是更新广播。
- 同步模式:同步模式分为两种:初始化同步及更新同步。Leader选举结束并发布初始化广播后,所有Learner会将Leader广播的事务及epoch同步到本地,这是初始化同步。当集群正常时,Leader发布更新广播后,所有Learner会将Leader广播的事务同步到本地,这是更新同步。
3、三个数据
zookeeper中有三个重要数据:zxid,epoch,xid
zxid是64位的Long类型,高32位表示epoch,低32位表示事务表示xid。即zxid包括epoch和xid两部分。
epoch代表纪元、时代,每个Leader都会有一个不同的epoch,每一次新的选举结束后都会产生新的Leader与epoch,所有的zkServer都会更新epoch。
xid是zk的事务id,每一个写操作都是一个事务,会产生唯一的xid。xid为依次递增的流水号。每一个写操作都是由Leader发起提案,由所有Follower进行表决,每个提案都会有zxid。
三、ZAB中的概念
1、同步模式与广播模式
初始化同步
完成Leader选举之后,此时的Leader是准Leader,其要通过恢复模式下的初始同步阶段,将准Leader变为真正的Leader。具体过程如下:

为保证Leader向Learner发送的提案有序,Leader为每一个人Learner创建一个队列
Leader将那些还没有被Learner服务器同步的事务封装为Proposal
Leader将这些Proposal逐条发送给Learner,并将每一个Proposal后都紧跟一个COMMIT消息,表示该事务已经被提交,Learner可直接接收并执行
Learner接收到来到Leader的Proposal,并将其更新到本地
当Follower更新成功后,会向准Leader发送ACK信息
Leader收到来自Follower的ACK后将Follower加入到真正可用的Follower列表
消息广播算法
当集群中已经有过半的Follower完成了初始化状态同步,那么整个zk又进入到正常工作模式了。
如果集群中的其他节点收到客户端的事务请求,那么Learner会将请求转发给Leader,然后再执行如下具体过程:
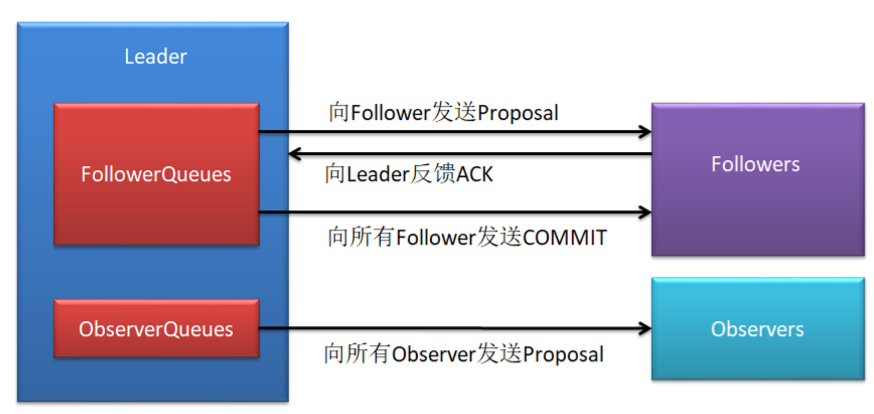
Leader接收事务请求后,为事务赋予一个全局唯一的自增id,即zxid,通过zxid的大小比较即可实现事务的有序性管理,然后将事务封装为一个Proposal
Leader根据Follower列表获取到所有的Follower,然后将Proposal通过Follower的队列将提案发送给各个Follower。
当Follower接收到提案后,会先将提案的zxid与本地的事务日志中的最大的zxid进行比较,若当前提案的zxid大于最大的zxid,则将提案记到本地事务日志中,并向Leader返回一个人ACK。
当Leader接收过半的ACK后,Leader会向所有的Follower队列发送COMMIT消息,向所有的Observer的队列发送Proposal。
当Follower收到COMMIT消息后,会将日志中的事务正式更新到本地。当Observer收到Proposal后,会直接将事务更新到本地。
2、恢复模式的两个原则
当集群启动或崩溃的集群通过恢复模式重新建立连接,对于恢复的数据遵循两个原则:
a、已被处理的消息不能丢
当Leader收到超过半数Follower的ACKs后,会向各个Follower广播COMMIT消息,各个Server收到COMMIT消息后会本地执行该写操作,但若在非全部Follower收到COMMIT消息之前Leader挂了,会导致:部分Server执行了该事务,部分Server未收到COMMIT消息,未执行该事务。当新的Leader出现,集群会通过恢复模式保证将Server上执行了的部分Server执行。
b、被丢弃的消息不能重现
当Leader接收到事务请求并生成Prosoal,但尚未向任何Follower发送就挂了,其他Follower不知道该Prosal的存在。当新Leader选举出来,整个集群正常服务后,之前挂了的Leader注册成为Follower,而其他人不知道的那个Proposal会导致集群的状态不一致,因而Propol会被清除。根据epoch的规则,新Leader的epoch值会大于当前集群任意主机记录的zxid的高32位,新Leader产生后会将所有Leader中未被COMMIT过的Proposal清除。
四、Leader选举
ZAB是为zookeeper设计的一种支持崩溃恢复的原子广播协议,当zk的Leader宕机恢复正常或集群启动过程中集群会进入恢复模式,而恢复模式中重要的阶段就是Leader选举。Leader持续的时间为30-120s,期间zk集群无法提供服务。
1、Leader选举的基本概念
myid:myid是集群中服务器的唯一标识,如三个zk服务器,其编号为:1,2,3
逻辑时钟:Logicallock,是一个整数,在选举时称为logicallock,选举结束后成为zxid中的epoch值,epoch与logicallock是同一值在不同阶段的名称。
zk的状态:
zk中的每一台主机,在不同阶段会处于不同的状态,每台主机具有四中状态。
LOOKING,选举状态(查找Leader)
FOLLOWING,跟随状态,同步Leader状态,处于该状态的服务器为Follower。
OBSERVING,观察状态,同步Leader状态,处于该状态的服务器为Observer。
LEADING,领导状态,处于该状态的服务器称为Leader。
2、Leader选举算法
集群启动过程中的Leader选举与断连后的Leader选举有所不同。
A、集群启动的Leader选举
这里的选举以三台主机为例
集群初始化阶段,第一台server1启动,会给自己投票,发布自己的投票结果,发布信息为(myid,zxid),此时他的投票为(1,0),由于其他机器未启动收不到反馈信息,server1一直处于Looking阶段,即非服务状态。当第二台机器server2启动成功,两台机器进行通信,进行Leader的选举:
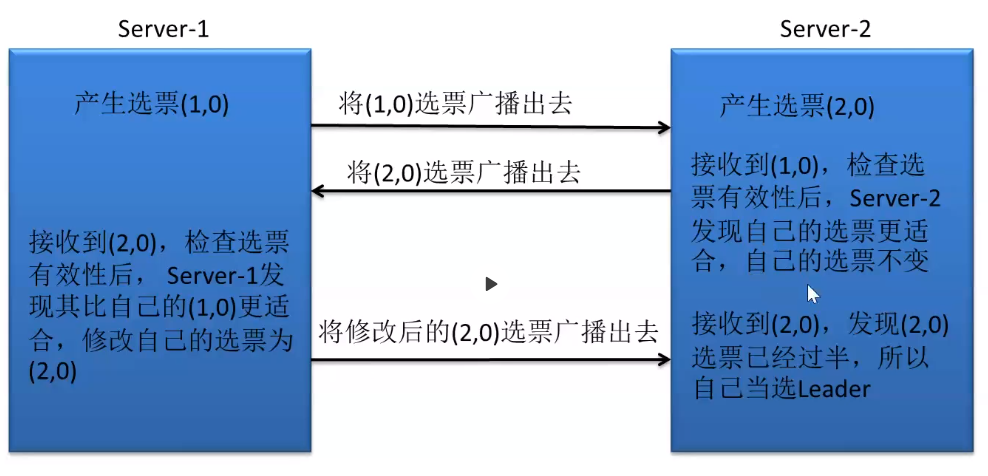
1、每个server会有一个投票,server1为(1,0),server2为(2,0),各自将自身投票发给其他机器。
2、接收投票。集群中的服务器接收投票,先判断投票的有效性,如检查是否为本轮投票、是否为来自LOOKING状态的服务器等。
3、处理投票,针对每个投票,服务器将别人投票与自身PK:
- 先检查zxid,zxid大的服务器优先作为Leader。
- zxid相同,比较myid,myid大的服务器优先作为Leader。
对于当前参与投票的server,server1为(1,0),server2为(2,0),先比较zxid,均为0,再比较myid,server2myid大,server1更新投票为(2,0),重新投票,而server2只是再向集群发出一次投票信息即可。
4、统计投票,每次投票后会统计投票信息,判断是否有过半机器接受相同的投票信息,对于当前集群,server1、server2接受(2,0)的投票,此时选出的Leader为server2。
5、改变服务器状态。若Leader确定,则服务器会修改状态,Follower服务器该状态为FOLLOWING,Leader变为LEADING。
6、添加主机。当新的主机添加进来,由于目前集群各个主机正常服务,且状态为非LOOKING,其只能作为Follower身份添加到集群中。
注:若集群为纯净主机,则总为第二台为Leader
B、断连后的Leader选举
zookeeper正常运行期间,当有非Leader服务宕机或加入新的服务器,也不会影响Leader,但当Leader挂了,整个集群将暂停对外服务,进入新的Leader选举,过程与启动过程基本一致。现假设有三个服务器server1、server2、server3,其中server2为Leader,某时刻server2宕机,集群重新进行Leader选举:
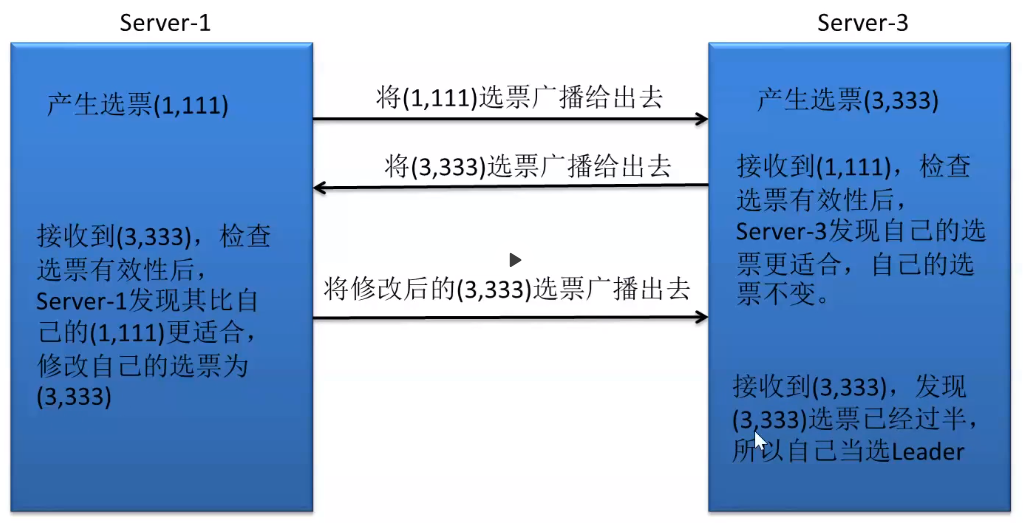
1、变更状态。首先集群中的非Observer服务器将自身的状态变更为LOOKING,进入Leader选举
2、每个server发出一个投票,首先自己选自己,运行期间,各个服务器中的zxid可能不同,假设server1的选票为(1,111),server3的选票为(3,333),他们将各自的选票发给集群中其他机器。
3、接收投票。集群中的服务器接收投票,先判断投票的有效性,与启动过程检查相同,检查是否为本轮投票、是否为来自LOOKING状态的服务器等。
4、处理投票。与启动过程相同,将别人投票与自身PK,对于当前集群,先比较zxid,server3的zxid大于server1的zxid,server1更新投票为(3,333),重新进行投票。
5、统计投票,与启动过程相同,每次投票后会统计投票信息,判断是否有过半机器接受相同的投票信息,对于当前集群,server1、server3接受(3,333)的投票,此时选出的Leader为server3。
6、改变服务器状态。Leader确定,则服务器会修改状态,Follower服务器该状态为FOLLOWING,Leader变为LEADING。
注:若Leader选举完毕,上一轮的Leader服务器恢复服务,此时,其只能作为Follower
五、CAP原则
CAP原则又称为CAP定理,值得是在一个系统中一致性、可用性、区分容错性,三者不能兼得。
-
一致性(Consistency):分布式系统的多个主机之间是否保持数据的一致性,即当系统数据更新后,主机中的数据仍能够保持一致。
-
可用性(Availability):系统服务必须一直处于可用状态,即对于每一个用户请求,系统总可以在有效的时间内对用户做出响应。
这里的响应不一定是预期的结果;有效时间也是由系统所决定的,如谷歌返回信息时间为0.3S。
-
区分容错性(Partition tolerance):分布式系统在遇到任何网络分区故障时,仍能够保证对外提供满足一致性或可用性服务。
对于一个分布式系统来说,在CAP原则中满足两项,CP或AP,这是CAP的三二原则。
分布式系统中,p是必须要保证的,但其不能同时保证一致性和可用性。为保证一致性,系统中的各个节点需要进行分布式同步,而在同步过程中,不能对外提供服务,无法保证可用性;为保证可用性,当其中一个节点数据更新,其他节点尚未完成同步过程中,系统仍对外提供服务的,此过程则牺牲了一致性。
针对ZK来说,zk遵循CP原则,即牺牲了可用性保证一致性。
当zk集群的Leader宕机后,集群会进行Leader选举,此选举过程持续30-120S,在此期间,zk集群不接受客户端的读写操作,zk处于瘫痪状态,其不满足可用性。
zk选举Leader需要时间很长,为保证数据一致性,zk做了两种数据同步:初始化同步与更新同步。
- 初始化同步:新Leader选出,各个Follower将Leader的数据同步到自身缓存中。
- 更新同步:当Leader数据被修改,其会向Follower发出广播,各个Follower主动同步Leader的更新数据
无论是初始化同步,还是更新同步,zk为保证数据的一致性,若超过半数的Follower同步超时,其会再次进行同步,此过程中zk处于不可以状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号