通用数据权限的思考与设计
1 数据权限概述
1.1 什么是数据权限?
数据权限是指对系统用户进行数据资源可见性的控制,通俗的解释就是:`符合某条件的用户只能看到该条件下对应的数据资源`。那么最简单的数据权限大概就是:用户只能看到自己的数据。而在正式的系统环境中,会有很多更为复杂的数据权限需求场景,如:
- 领导需要看到所有下属员工的客户数据,员工只能看自己的客户数据;
- 经理A能看到所有企业客户,经理B只能看到年销售额小于1000万的企业客户;
- 角色A能看到全国的产品数据,角色B只能看到上海的产品数据;
上述这些需求,使用硬编码也是可以实现的,但是在业务快速发展的过程中,类似这种数据权限需求会越来越多,如果全部采用硬编码的方式,无疑会给我们带来巨大的开发和维护压力。
1.2 要素分析
从当前登录用户的角度来说,数据权限的定义可以解释为:`当前登录的用户只能看到该用户权限范围内的数据资源`。由此可以分析出数据权限控制中几个关键要素:
1. 主体,即当前登录用户。领导、角色等概念可翻译为当前登录用户是否是领导,是否拥有某角色。
2. 数据资源。即受管控系统数据。
3. 条件规则。即当前登录用户对于某特定的数据资源适用的条件。
2 数据权限设计
理论上来说,用户在访问受控的系统数据时,获取用户对该数据资源适用的条件规则,并将该条件规则解析为SQL查询语句即可实现对数据的权限控制。但是在实现过程中,还是会有很多难点,譬如当前登录用户适用下列规则:
客户数据:[客户经理] [包含于] [下属人员]
产品数据:[销售地区] [等于] [上海]
订单数据:([产品销售地区] [等于] [上海])[并且] ([客户市场经理] [包含于] [下属人员])
思考如下问题:
1. `[客户经理] [包含于] [下属人员]`如何解析为SQL语句?多表联合查询时又该如何处理?
2. `[下属人员]`由系统根据当前登录用户计算而来,`上海`由管理员后台选择。两种方式如何兼容?
3. 对于复杂多变的组合条件,应该如何设计?
4. 如何确定当前查询应该应用哪些条件规则?
5. 一个用户拥有多个角色,不同角色对于同一个规则设置不同的值应该如何处理?
2.1 规则元
名词定义:规则元。在本文是指单个独立的数据规则定义,不同用户对规则元可设置具体的规则过滤值,该值用作数据查询时的筛选条件。上述规则中`[客户经理]`,`[销售地区]`都属于规则元。
2.2 规则元配置
1. 规则元名称的配置。一个表中哪些字段可以进行规则设置,以及规则元名称如何与表字段关联。(如上述规则中`[客户经理]`,`[销售地区]`),比较容易想到的方法是通过配置文件维护规则名称与数据库字段之间的关系。
2. 规则元Value数据源的配置。如上述规则中的`[下属人员]`,`[上海]`,不难发现规则元Value来源有三种情况:
① 后台管理人员输入。
② 系统提供数据源,后台管理人员选择。如:所在地区`[上海]`
③ 系统提供数据。如:`[下属人员]`
配置文件可以实现数据规则的配置需求,但是当规则元越来越多时,维护配置文件就会变得麻烦起来,我们是否可以效仿spring-boot取代spring-mvc的做法,使用注解来代替配置呢?每一条数据规则最终都会落到对数据库字段的控制,而现在绝大部分系统都会有一个Model层对应到数据库中的表,于是脑补出一个绝佳的规则元配置方式:
@TableName("test")
public class TestModal extends AbstractModel {
@DataRule(name = "规则元名称")
private String name;
}
`@DataRule`注解源码如下:

@Target({ElementType.FIELD}) @Retention(RetentionPolicy.RUNTIME) public @interface DataRule { /** * 规则元名称 */ String name() default ""; /** * 规则元值来源类型 */ RuleSourceStrategy strategy() default RuleSourceStrategy.TEXT; /** * 当数据来源是用户选择时{@code RuleSourceStrategy.CHOICE}数据地址 */ String url() default ""; /** * 当数据来源是系统提供时{@code RuleSourceStrategy.SYSTEM}提供器类名 */ Class<? extends IDataRuleProvider> provider() default NullDataRuleProvider.class; }
系统启动时,将规则元配置信息(名称、对应数据表、对应字段、值来源类型,值来源url,值来源提供者类名等)同步至数据库。数据表简单设计如下图: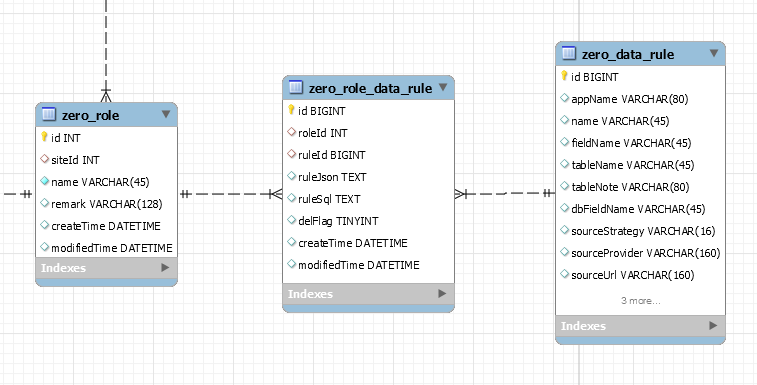
2.3 数据规则的配置
有了规则元信息,管理人员即可在系统中针对不同用户(角色)设置规则元Value,该值作为数据查询时的筛选条件。规则元Value数据源包含三种情况,其中第①、②种情况下,需要管理员填写或选择该规则的值,存储于数据库;第③种情况下,Value值根据当前登录用户计算得出,也即是`@DataRule`注解中`provider`计算得来的值。由数据库存储的规则与系统计算得到的规则合并后即是登录用户的所有数据规则。一个简单的配置界面如下: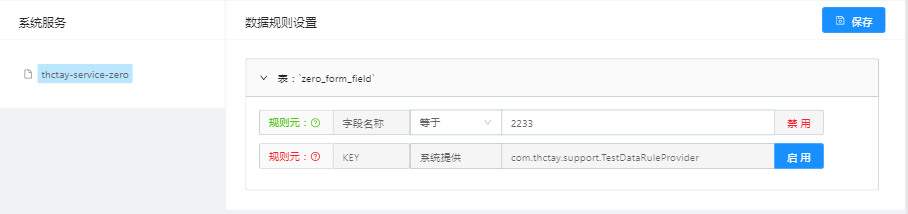
2.4 数据规则的解析
由上文可知,适用于当前登录用户的数据规则主要来源有两种:
1. 存储在数据库中的规则配置;如:所在地区`[上海]`
2. 需要系统计算的规则配置;如:`[下属人员]`
两种情况下获取的数据规则合并之后即可获取适用于当前登录用户的数据规则集合,流程图如下: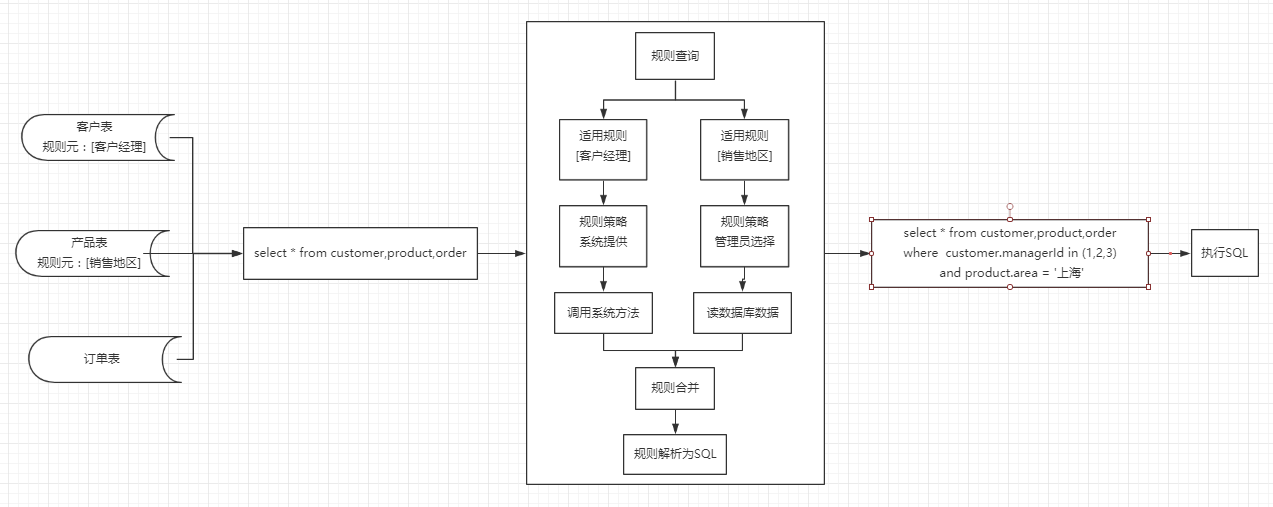
> 两种情况下获取的数据规则如何兼容?规则合并后成为一个复杂的查询条件应该如何设计?
定义通用的规则结构如下:
{ rule:[{ field: "name", operate: "equal", value: "xxx" }], operate:"and", group:[{ rule:[], operate:"greater", group:[] }] }
数据库存储规则结构的JSON串,合并时将JSON串反序列化之后使用`and`与系统计算得出规则对象连接即可,合并后的规则结构解析成简单SQL语句已经不是很难了。
> 但是对于多表联合查询时应该如何处理呢?
解析成SQL语句时可以使用`表名+字段名`的方式,可是遇到查询中使用别名的时候,这种方式也不能正常工作,这里暂时的处理方式是支持解析时传递别名。
> 一个用户拥有多个角色,不同角色对于同一个规则设置不同的值应该如何处理?
譬如,用户A拥有角色`role1`、`role2`,其中:
role1适用规则:[销售地区] [等于] [上海]
role2适用规则:[销售地区] [等于] [北京]
那么用户A合并后的数据规则应该是:
用户A适用规则:([销售地区] [等于] [上海]) or ([销售地区] [等于] [北京])
即:一个用户对于同一个规则元的多个规则设置,应使用`or`连接后再与其他规则元进行`and`连接。
2.5 确定当前查询适用的数据规则
经过上述的规则配置与解析之后,我们很容易拿到当前用户适用的数据规则集合。但是在一次查询时我们应该使用集合中哪些规则进行过滤呢?一次查询是否开启数据规则过滤,使用哪些表的规则过滤应该是开发者来决定,类似:
xxxQuery(...).withDataRule("`table1`,`table2`");
即表示当前用户本次查询使用`table1`、`table2`中配置的数据规则。数据表中的每条规则应该支持在管理后台设置是否启用,这样理论上可实现每个用户对每一条数据规则的配置。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· 展开说说关于C#中ORM框架的用法!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?