
[010] - JavaSE面试题(十):集合之Map
第一期:Java面试 - 100题,梳理各大网站优秀面试题。大家可以跟着我一起来刷刷Java理论知识
[010] - JavaSE面试题(十):集合之Map
第1问:HashMap和HashTable有什么区别?
-
HashMap允许键和值是null,而Hashtable不允许键或者值是null。
-
Hashtable是同步的,而HashMap不是。因此,HashMap更适合于单线程环境,而Hashtable适合于多线程环境。
-
HashMap提供了可供应用迭代的键的集合,因此,HashMap是快速失败的。另一方面,Hashtable提供了对键的列举(Enumeration)。
-
由于Hashtable继承自Dictionary类。而这个类已经基本上废弃了,所以一般认为Hashtable是一个遗留的类
第2问:Java中HashMap的key值要是为类对象,则该类需要满足什么条件?
需要重写equals()和hashCode()方法。
第3问:谈一下HashMap的特性?
1.HashMap存储键值对实现快速存取,允许为null。key值不可重复,若key值重复则覆盖。
2.非同步,线程不安全。
3.底层是hash表,不保证有序(比如插入的顺序);
第4问:谈一下HashMap的存储结构?
1.7版本:数组+链表
1.8版本:数组+链表+红黑树

图中,紫色部分即代表哈希表,也称为哈希数组(默认数组大小是16,每对key-value键值对其实是存在map的内部类entry里的),数组的每个元素都是一个单链表的头节点,跟着的绿色链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就会采用头插法将其放入单链表中。
第5问:HashMap在JDK1.7和JDK1.8中有哪些不同?

第6问:说一下HashMap扩容机制?
何时进行扩容?
HashMap使用的是懒加载,构造完HashMap对象后,只要不进行put 方法插入元素之前,HashMap并不会去初始化或者扩容table。
当首次调用put方法时,HashMap会发现table为空然后调用resize方法进行初始化,当添加完元素后,如果HashMap发现size(元素总数)大于threshold(阈值),则会调用resize方法进行扩容。
扩容过程:
若threshold(阈值)不为空,table的首次初始化大小为阈值,否则初始化为缺省值大小16
默认的负载因子大小为0.75,当一个map填满了75%的bucket时候(即达到了默认负载因子0.75),就会扩容,扩容后的table大小变为原来的两倍(扩容后自动计算每个键值对位置,且长度必须为16或者2的整数次幂)
若不是16或者2的幂次,位运算的结果不够均匀分布,显然不符合Hash算法均匀分布的原则。
反观长度16或者其他2的幂,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的
假设扩容前的table大小为2的N次方,元素的table索引为其hash值的后N位确定扩容后的table大小即为2的N+1次方,则其中元素的table索引为其hash值的后N+1位确定,比原来多了一位重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing
因此,table中的元素只有两种情况:
- 元素hash值第N+1位为0:不需要进行位置调整
- 元素hash值第N+1位为1:将当前位置移动到
原索引+未扩容前的数组长度的位置 - 扩容或初始化完成后,resize方法返回新的table
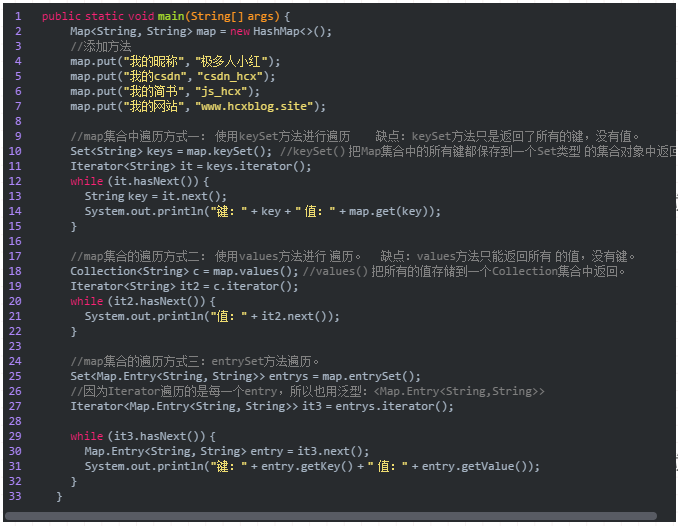
第7问:遍历map集合的三种方式?
第8问:并发集合和普通集合区别?
并发集合常见的有 ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque 等。并发集合位于 java.util.concurrent 包下,是 jdk1.5 之后才有的。
在 java 中有普通集合、同步(线程安全)的集合、并发集合。
- 普通集合通常性能最高,但是不保证多线程的安全性和并发的可靠性。
- 线程安全集合仅仅是给集合添加了 synchronized 同步锁,严重牺牲了性能,而且对并发的效率就更低了,并发集合则通过复杂的策略不仅保证了多线程的安全又提高的并发时的效率。
第9问:HashMap的put()和get()原理?
put()原理:
1.根据key获取对应hash值:int hash = hash(key.hash.hashcode())
2.根据hash值和数组长度确定对应数组引int i = indexFor(hash, table.length);
简单理解就是i = hash值%模以 数组长度(其实是按位与运算)。如果不同的key都映射到了数组的同一位置处,就将其放入单链表中。且新来的是放在头节点。
get()原理:
通过hash获得对应数组位置,遍历该数组所在链表(key.equals())
第10问:HashCode相同,冲突怎么办?
采用“头插法”,放到对应的链表的头部。因为HashMap的发明者认为,后插入的Entry被查找的可能性更大,所以放在头部。(因为get()查询的时候会遍历整个链表)
第11问:HashMap是线程安全的吗?为什么?在并发时会导致什么问题?
不是,因为没加锁。
hashmap在接近临界点时,若此时两个或者多个线程进行put操作,都会进行resize(扩容)和ReHash(为key重新计算所在位置),而ReHash在并发的情况下可能会形成链表环。在执行get的时候,会触发死循环,引起CPU的100%问题
注:jdk8已经修复hashmap这个问题了,jdk8中扩容时保持了原来链表中的顺序。但是HashMap仍是非并发安全,在并发下,还是要使用
ConcurrentHashMap。
第12问:HashMap如何判断有环形表?
创建两个指针A和B(在java里就是两个对象引用),同时指向这个链表的头节点。然后开始一个大循环,在循环体中,让指针A每次向下移动一个节点,让指针B每次向下移动两个节点,然后比较两个指针指向的节点是否相同。如果相同,则判断出链表有环,如果不同,则继续下一次循环。
通俗易懂一点:在一个环形跑道上,两个运动员在同一地点起跑,一个运动员速度快,一个运动员速度慢。当两人跑了一段时间,速度快的运动员必然会从速度慢的运动员身后再次追上并超过,原因很简单,因为跑道是环形的
第13问:介绍一下ConcurrentHashMap?
结构如下:

hashmap是由entry数组组成,而ConcurrentHashMap则是Segment数组组成。
Segment本身就相当于一个HashMap。
同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。
单一的Segment结构如下:

Segment对象在ConcurrentHashMap集合中有2的N次方个,共同保存在一个名为segments的数组当中。
可以说,ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。(这样类比理解多个hashmap组成一个cmap)
第14问:ConcurrentHashMap的put()和get()原理?
put()原理:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
get()原理:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
由此可见,和hashmap相比,ConcurrentHashMap在读写的时候都需要进行二次定位。先定位到Segment,再定位到Segment内的具体数组下标。
第15问:为什么ConcurrentHashMap和hashtable都是线程安全的,但是前者性能更高呢?
因为前者是用的分段锁,根据hash值锁住对应Segment对象,当hash值不同时,使其能实现并行插入,效率更高,而hashtable则会锁住整个map
并行插入:当cmap需要put元素的时候,并不是对整个map进行加锁,而是先通过hashcode来知道他要放在那一个分段(Segment对象)中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在同一个分段中,就实现了真正的并行的插入
注意:在统计size的时候,就是获取ConcurrentHashMap全局信息的时候,就需要获取所有的分段锁才能统计(即效率稍低)。
分段锁设计解决的问题:
目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一部分行加锁操作。
第16问:ConcurrentHashMap为何不支持null键和null值?
HashMap是支持null键和null值,而ConcurrentHashMap却不支持
查看源码如下:

原因:通过get(k)获取对应的value时,如果获取到的是null,此时无法判断它是put(k,v)的时候value为null,还是这个key从来没有做过映射(即没有找到这个key)。而HashMap是非并发的,可以通过contains(key)来做这个判断。而支持并发的Map在调用m.contains(key)和m.get(key),m可能已经不同了。
第17问:HashMap1.7和1.8的区别?
1.为了加快查询效率,java8的HashMap引入了红黑树结构,当数组长度大于默认阈值64时,且当某一链表的元素>8时,该链表就会转成红黑树结构,查询效率更高。
2.优化扩容方法,在扩容时保持了原来链表中的顺序,避免出现死循环
红黑树:一种自平衡二叉树,拥有优秀的查询和插入/删除性能,广泛应用于关联数组。对比AVL树,AVL要求每个结点的左右子树的高度之差的绝对值(平衡因子)最多为1,而红黑树通过适当的放低该条件(红黑树限制从根到叶子的最长的可能路径不多于最短的可能路径的两倍长,结果是这个树大致上是平衡的),以此来减少插入/删除时的平衡调整耗时,从而获取更好的性能,而这虽然会导致红黑树的查询会比AVL稍慢,但相比插入/删除时获取的时间,这个付出在大多数情况下显然是值得的。
第18问:ConcurrentHashMap1.7和1.8的区别?
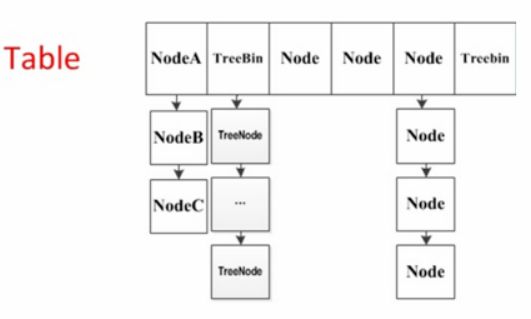
1.8的实现已经抛弃了Segment分段锁机制,利用Node数组+CAS+Synchronized来保证并发更新的安全,底层采用数组+链表+红黑树的存储结构。
CAS:
CAS,全称Compare And Swap(比较与交换),解决多线程并行情况下使用锁造成性能损耗的一种机制。java.util.concurrent包中大量使用了CAS原理。
JDK1.8 中的CAS:
Unsafe类,在sun.misc包下,不属于Java标准。Unsafe类提供一系列增加Java语言能力的操作,如内存管理、操作类/对象/变量、多线程同步等。其中与CAS相关的方法有以下几个:
//var1为CAS操作的对象,offset为var1某个属性的地址偏移值,expected为期望值,var2为要设置的值,利用JNI来完成CPU指令的操作 public final native boolean compareAndSwapObject(Object var1, long offset, Object expected, Object var2); public final native boolean compareAndSwapInt(Object var1, long offset, int expected, int var2); public final native boolean compareAndSwapLong(Object var1, long offset, long expected, long var2);
CAS缺点:
- ABA问题。当第一个线程执行CAS操作,尚未修改为新值之前,内存中的值已经被其他线程连续修改了两次,使得变量值经历 A->B->A 的过程。
- 解决方案:添加版本号作为标识,每次修改变量值时,对应增加版本号;做CAS操作前需要校验版本号。JDK1.5之后,新增AtomicStampedReference类来处理这种情况。
- 循环时间长开销大。如果有很多个线程并发,CAS自旋可能会长时间不成功,会增大CPU的执行开销。
- 只能对一个变量进原子操作。JDK1.5之后,新增AtomicReference类来处理这种情况,可以将多个变量放到一个对象中。
注意:在统计size的时候,就是获取ConcurrentHashMap全局信息的时候,就需要获取所有的分段锁才能统计(即效率稍低)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号