论文笔记《Distill on the Go: Online knowledge distillation in self-supervised learning》
Distill on the Go: Online knowledge distillation in self-supervised learning
- 2021.5.13
- Learning from Limited or Imperfect Data (L2ID) Workshop @ CVPR 2021
- https://arxiv.org/abs/2104.09866
Introduction
- 有证据表明,大模型比小模型在自监督上更加受益,为了解决在小模型上自监督预训练的问题,我们提出了Distill-on-the-Go用在线蒸馏的方法来改善小模型的表征,我们在两个模型中使用互学习的策略让两个模型相互学习,然后将两个模型对于相同样本增强过之后的相似度保证其一致性。
- 在线蒸馏提供了一种一阶段训练的方法,平等对待参加的所有模型,每个模型均输入同一张图片的两个随机增强过的视图,让这两个之间的相似性保持一致
Method
- 方法很简单,一张图就可以搞定了,如下图所示,同一张图片经过四种不同的随机变换后,输入到参与在线蒸馏的两个网络中,通过MLP映射出的embedding向量,计算两者之间的相似性,利用相似性做一个对称的KL loss分别用于单个模型的训练,每个网络再通过常规对比学习的方法也进行训练,让两者越来越近的同时让其离负样本越来越远
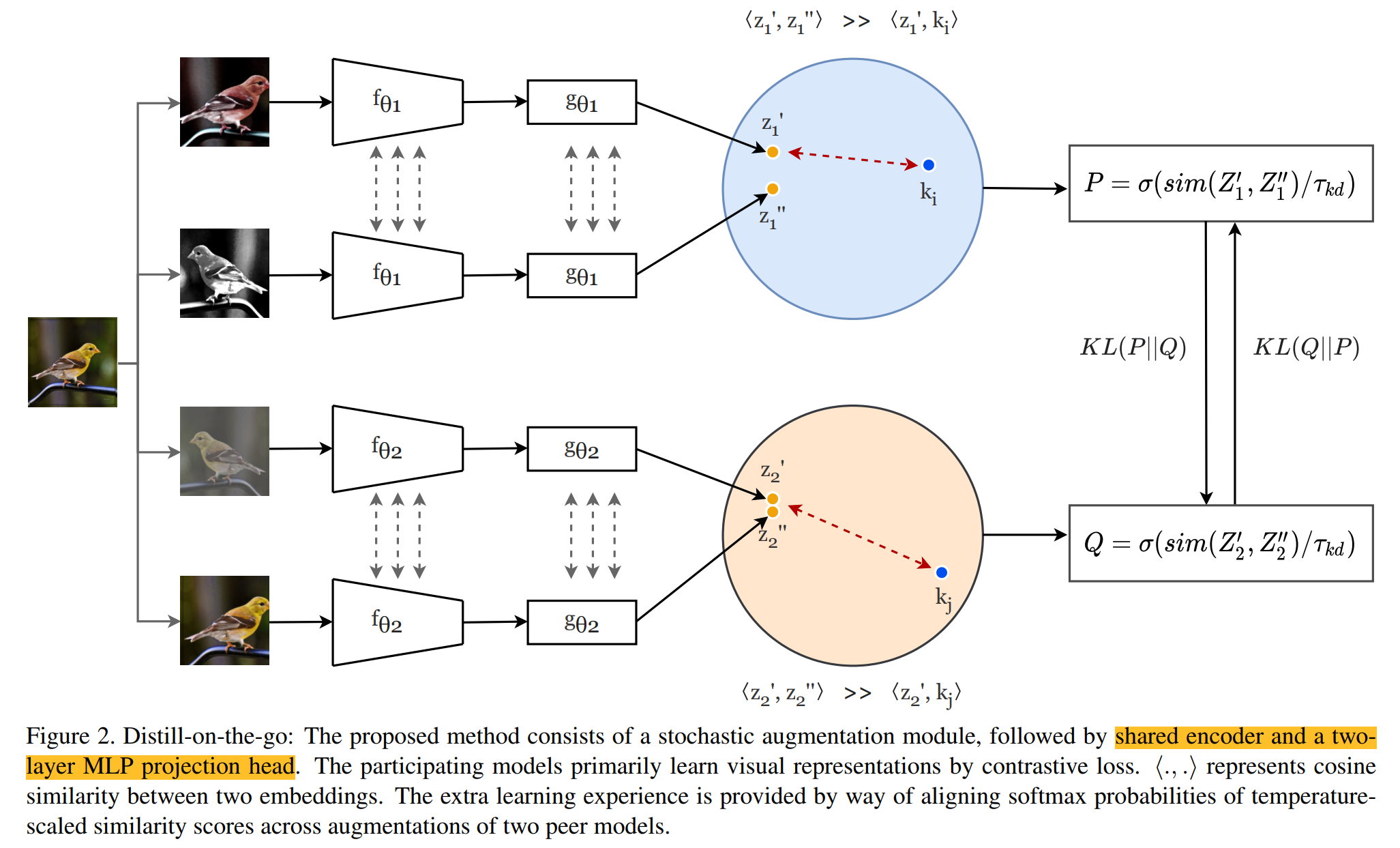
-
每一个encoder对比学习的loss就是最普通的对比学习loss,公式如下:
![]()
-
在通过两个相似度之间的KL loss,算KL loss的时候需要注意,两个参数的位置不同公式是不同的,KL散度其实就是相对熵,等于交叉熵减去信息熵,公式如下:
![]()
-
所以在在线蒸馏的过程中,每一个模型都有两个loss来进行训练,如下:
![]()
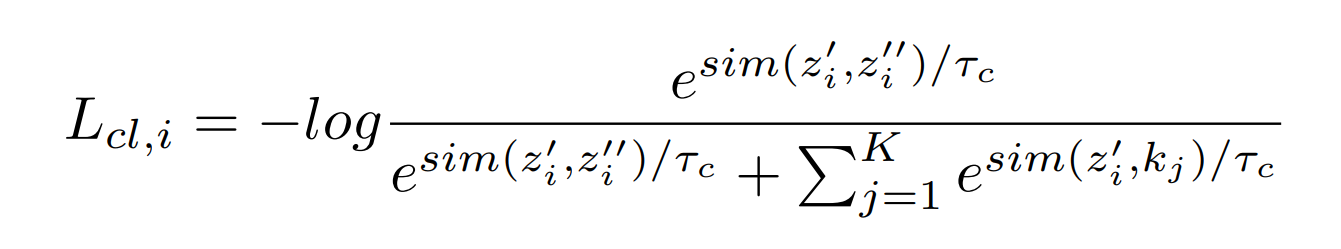
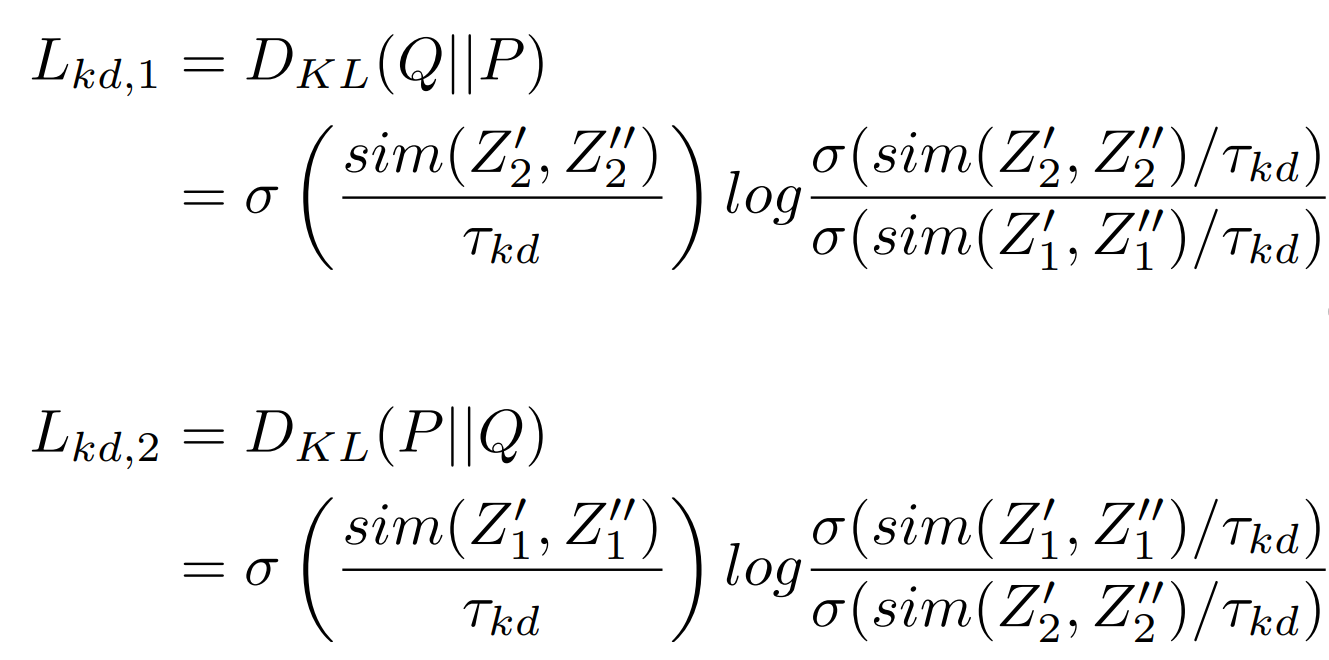
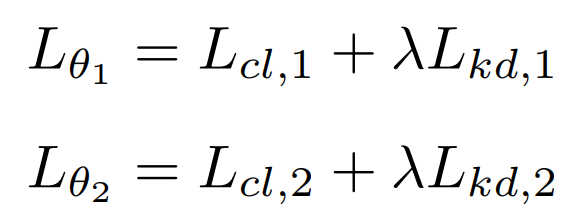
Experiment
-
文章做了多种实验来证明其有效性,我这边都做了列举了但只详细介绍了部分,其主要的自监督预训练是在Tiny-ImageNet上做的,关于这个数据集预处理可以参考我之前的博客,也给了很多在这种数据集上训练的技巧,在网络中,首先将第一个\(7\times7\)的卷积替换成\(3\times3\)的也移除了池化层,用\(Adam\)优化器设定固定学习率\(3e^{-4}\)和权重衰减\(1e^{-6}\),上图公式中的\(\lambda\)取100。线性层优化策略似乎与预训练一致,训练100个epoch
-
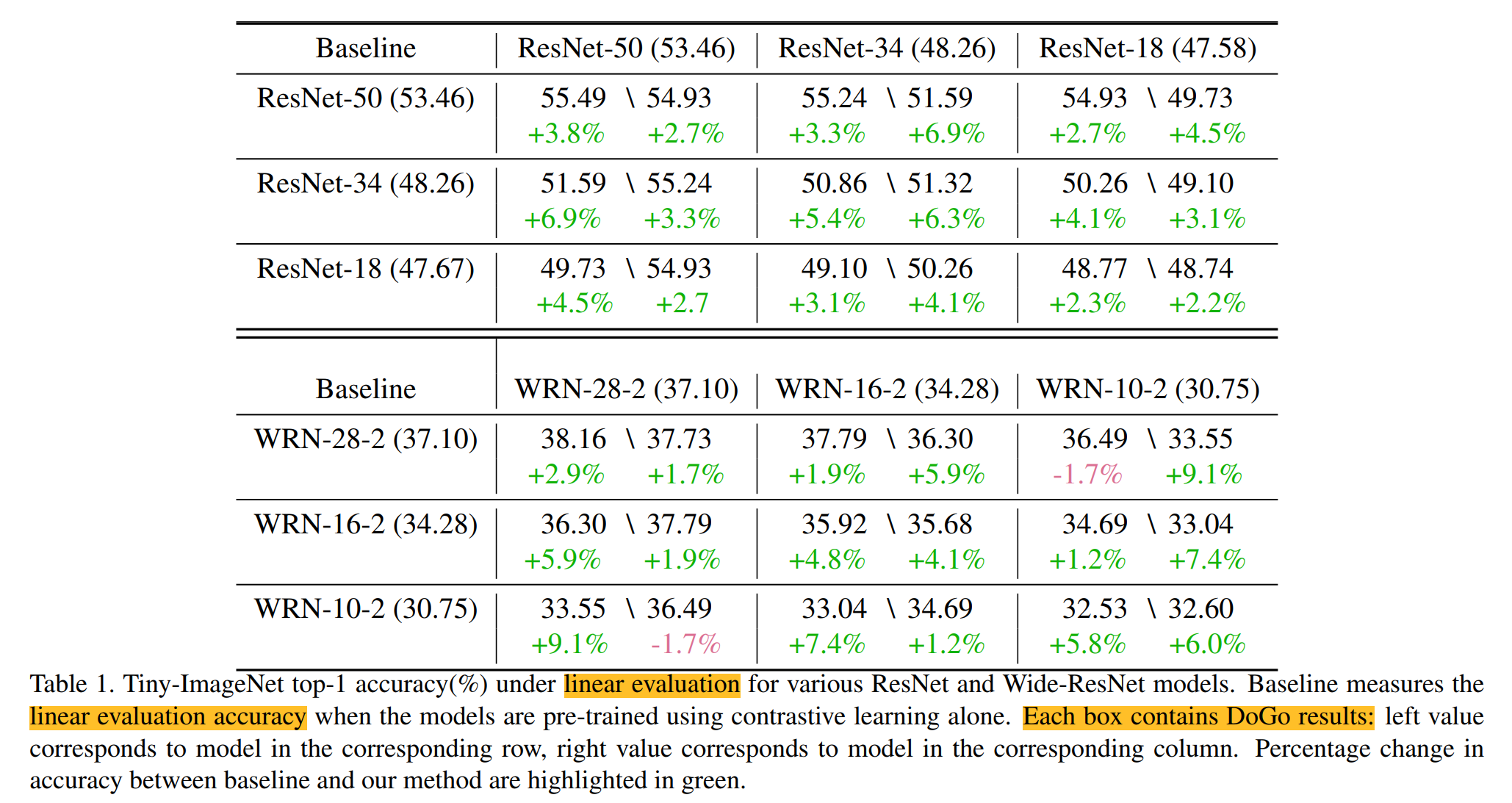
在分布内数据上的结果如下表,表格内左侧数据表示所在行表示的模型,表格内右侧数据表示所在列表示的模型,在蒸馏的作用下都比baseline有增加,baseline是通过SimCLR训练得到的结果
![]()
-
在不同label量下的结果,也就是半监督
-
在数据分布外数据集的泛化性结果,这里是其与训练后的用在别的小数据集上的结果
-
在有噪声的label下的结果,自监督对有噪声的label更具有鲁棒性
-
将蒸馏结构替换成SimSiam结构的影响
-
讨论超参的重要性
-
可视化函数空间的相似度。文章试图有额外的证据证明为什么work,在可视化了多种在本数据集上用contrastive训练的不同初始化模型后的单个训练轨迹上的projection。其展示了模型训练过程中的作用空间,可以看出单个模型仅探索有限的功能空间,而初始化不同的模型则探索了不同的作用空间,所以我们相信多个模型之间的联合训练可以让模型生成更具有泛化性的特征表征
![]()

Conclusion
- 做了很多个实验来证明该在线蒸馏方法的有效性,可以对两个模型都带来一定的增益,其实方法很简单,实现起来也很简单,但是所有的实验都是在与baseline的基础上比较的,并没有和先前的一些方法来比较,可能因为这是在自监督工作上第一个做在线蒸馏的,其实换句话说这也是自蒸馏,但是这个实验都是在Tiny-ImageNet的基础上完成的,并没有在更大的数据集上尝试,在Tiny-ImageNet上面做自监督的预训练还是比较少见的,基本没见过。但因为这篇作品是在workshop中,我还不太清楚workshop的机制等,但是本文确实是我第一次看到在自监督上做单阶段在线蒸馏的,感谢作品带来的启发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号