论文笔记《Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks》
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
- 2021.5.12
- Under review
- https://arxiv.org/abs/2105.02358
Introduction
- self-attention通过计算所有位置上成对特征关系的加权和,来捕获在单个图片内long-range各部分的依赖关系,来更新每个位置的特征。但是它有一个很高的复杂度并且忽略了不同样本之间的关系
- 本文提出了一种新的attention机制基于两个额外的很小的共享memory,只需要用简单的两个级联线性层和BN层就行 可以方便的代替attention,只有线性的复杂度并可以考虑样本之间关系
- 对于之前的self-attention,一般的做法是通过计算query向量和key向量逐渐之间的关系来生成attention map,再加权乘在value上
- 本方法不同之处在于,通过计算query向量和一个可学习的key内存来得到attention map,生成一个细化的特征图,然后通过该attention map乘上另一个memory所存储的value,来生成特征图
- 两个memory通过线性层的方式实现,独立于单个样本,并且在整个数据集中共享参数,具有强大的正则作用并且提高了注意力的泛化机制。其之所以轻量化的核心在于memory中的元素数量比输入特征中少很多,只具有线性复杂度。这个额外的memory设计来学习整个数据集上最有区分度的特征,捕获最有信息的部分
Method
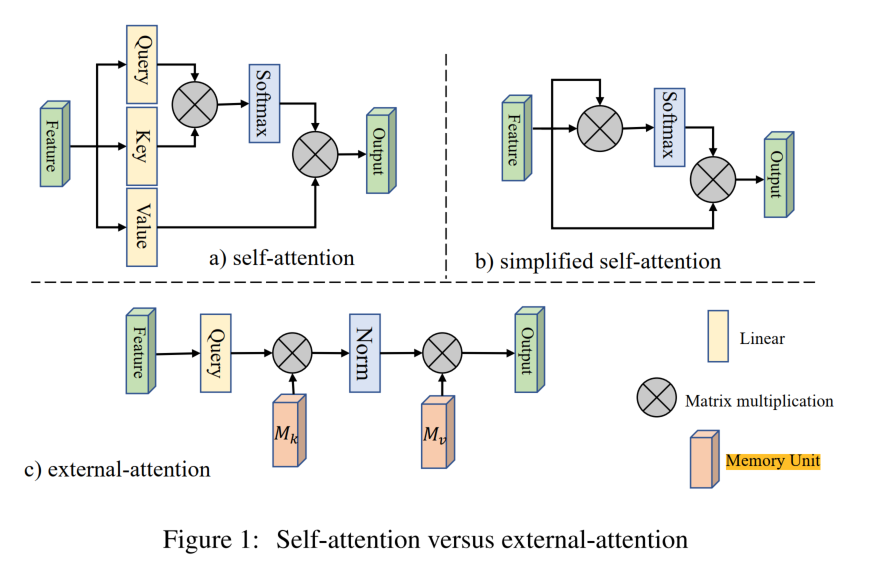
- 可以看到attention的结构对比图如下
-
我们是在self-attention的基础上来实现external-attention的,对于一个输入特征图\(F\in\mathbb{R}^{N \times d}\),\(N\)是像素数量,\(d\)是特征维数,self-attention首先通过线性变化将其变成
-
query matrix \(Q \in \mathbb{R}^{N \times d^{'}}\)
-
key matrix \(K \in \mathbb{R}^{N \times d^{'}}\)
-
value matrix \(V\in\mathbb{R}^{N \times d}\)
-
self-attention可以描述成
\[\begin{array}{rl} A&= (\alpha)_{i,j}=softmax(QK^T) \\ F_{out}&= AV \end{array} \]
-
-
对于简化版的self-attention,就直接利用特征图来计算attention,可以描述成
\[\begin{array}{rl}A&= (\alpha)_{i,j}=softmax(FF^T) \\F_{out}&= AF\end{array} \] -
对attention进行可视化之后可以发现大多数像素点只和一部分像素点有关,没有必要计算\(N \times N\)的attention map,所以我们提出了额外attention模块,通过计算像素与额外的存储单元\(M\in\mathbb{R}^{S \times d}\)得到attention,用和self-attention相似的方法进行归一化,M是一个独立于输入可学习的参数,作为整个数据集的存储单元,并且我们用不同的两个M分别作为key和value,所以整个external attention可以描述成
\[\begin{array}{rl}A&= (\alpha)_{i,j}=Norm(FM_k^T) \\F_{out}&= AM_v\end{array} \] -
d和S都属于超参,一个较小的S在实验中表现就很不错,所以external attention比self-attention更有效,应用在了多种任务上,论文中给出的伪代码如下图

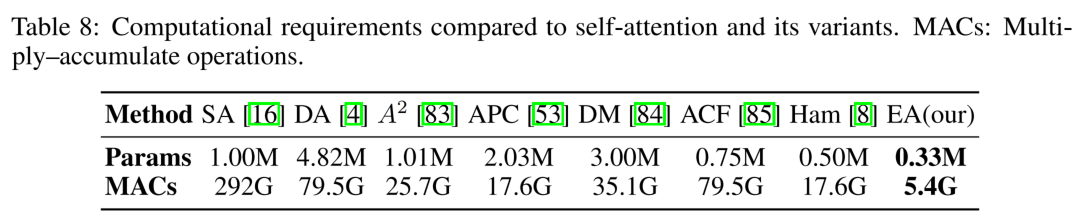
- 计算量对比上,和之前的一些attention工作进行了对比,但是并没有和ViT对比,这很奇怪
Conclusion
文章中做了多个实验来证明其有效性,包括分类、分割、目标检测、图像生成,点云等等,从结果来看确实是有效的,但是没有任何的ablation study,和最新的transformer之间的对比还不够,猜测最近几天众多与线性层相关的文章都会出现在今年的NeurIPS上,不知道专业的reviewer怎么看。我是感觉用一个线性层来存储整个数据集中的所有信息来得到这个attention是不是有点太草率了,但它结果确实也nb,在可视化上来看也是work的,毕竟是大佬的组出来的文章,但也还是希望能够看到和最近众多视觉上transformer相关工作的结果进行更全面的对比。感谢该paper带给我的启发

 浙公网安备 33010602011771号
浙公网安备 33010602011771号