初识ElasticSearch
概述
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
下面展示了在关系型数据库中和ElasticSearch中对应的存储字段:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
这里的索引和传统的关系型数据库中索引有些不同,在ElasticSearch中,一个索引就像是传统关系型数据库中的数据库。
在ElasticSearch和Lucene中,使用的是一种叫倒排索引的数据结构加速检索。
安装使用
由于机器有限,所以我采用的是使用虚拟机安装ElasticSearch。
实验环境如下:
- VMware虚拟机
- centos6.5系统
- JDK1.8
- ElasticSearch 5.2.2
下载与安装
可以在ElasticSearch官网下载最新版的ElasticSearch。
下载地址:https://www.elastic.co/downloads/elasticsearch
如果使用Windows则下载zip包,使用linux则下载tar.gz包。
安装之前需要安装JDK1.7以上版本。
在Windows下方法比较简单,解压zip包后,通过DOS命令行切换到bin目录,运行elasticsearch即可,可以通过查看localhost:9200端口,看是否启动成功。
在Linux中安装与使用
在linux中新建一个目录,名字为elasticsearch,使用Xftp或者WinSCP等工具将刚才下载的安装包传输到该目录下。
tar -zxvf elasticsearch-5.2.2.tar.gz解压文件。
进入到解压后的文件,输入.bin/elasticsearch即可打开elasticsearch。
可能出现的问题:
- 启动失败可能是因为使用了root用户,启动不允许使用root用户
- 启动失败其他原因,可能linux系统中有些参数需要修改修改,比如最大虚拟内存、用户最大可创建线程数,按照提示进行修改即可,具体设置地点可在网上查找。
- linux防火墙的9200端口需要打开,否则在主机上无法访问虚拟机里的ElasticSearch,可以通过ifconfig命令查询Linux主机的ip地址。
- 如果还是无法访问,可以进入ElasticSearch目录中的config目录中,vim elasticsearch.yml
,编辑设置文件,将host改为0.0.0.0,保存并重启ElasticSearch,就应该没问题了。
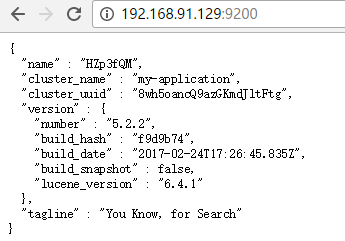
访问 ip + 9200,结果如下,ElasticSearch开启成功。
安装elasticsearch-head
elasticsearch-head是一个很好的管理工具,可以可视化看到集群的状况。
下载地址:https://github.com/mobz/elasticsearch-head
在elasticsearch5.0后,废弃了使用plugin安装的方式,可以使用git先clone代码,使用npm安装。
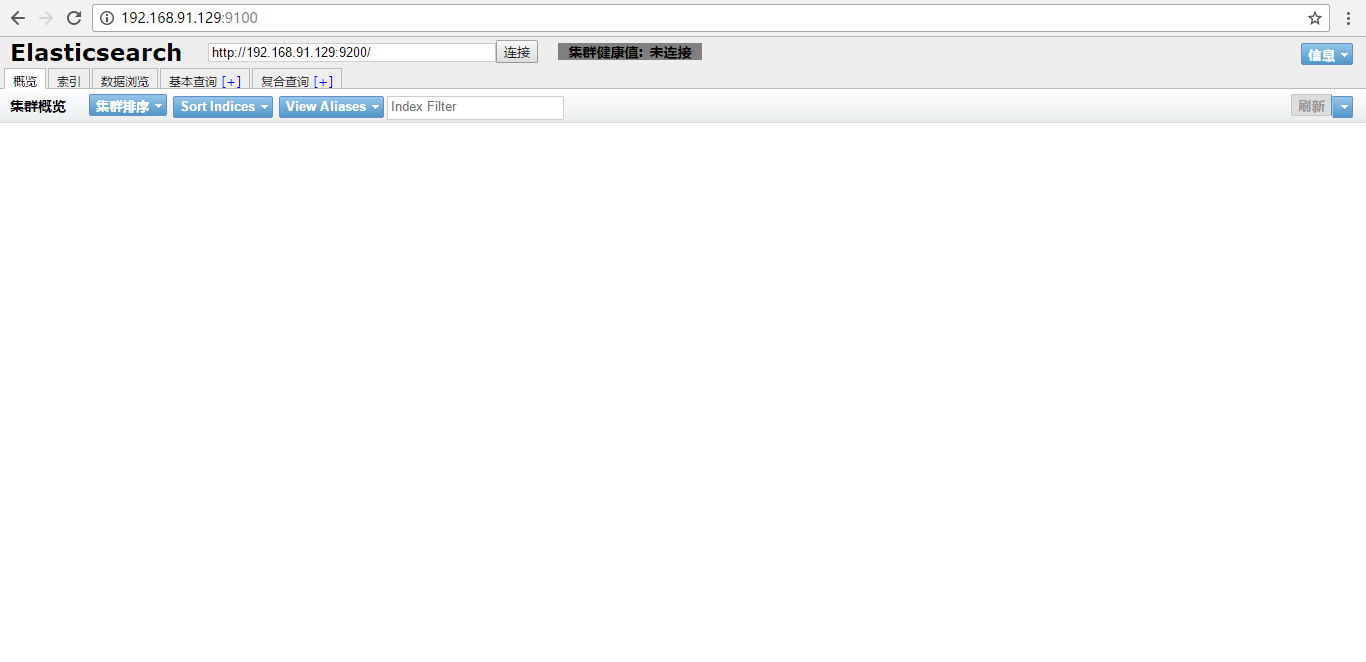
访问 ip + 9100,记得开放端口。
在chrome或者火狐浏览器中可能会出现跨域问题而无法连接,可以使用IE连接。
基本使用
在官网可以查看使用多种语言的API,在这里使用最简单的基于HTTP协议的API,使用JSON格式数据。
插入数据
在linux中,输入:
curl -XPUT 'http://192.168.91.129:9200/website/blog/1' -d '{"title":"liuyang", "text":"太阳在头顶之上", "date":"2017-4-16"}'
这样就可以插入一条数据,在插入多条数据后,在浏览器输入:
http://192.168.91.129:9200/_search?pretty

在结果中可以看到有多条记录。pretty的作用是为了让JSON优化排版,也可以直接使用curl -XGET获取数据。

搜索
查询字符串
在浏览器输入:
http://192.168.91.129:9200/_search?q=太阳
在q后面加上自己想要查找的字符串,就可以进行匹配了。
_score字段为匹配程度,越高的结果就会越在前面。

格式化结果后:
{
"took": 292,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.56008905,
"hits": [
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_score": 0.56008905,
"_source": {
"title": "title2",
"text": "小路弯弯,太阳正在头顶上",
"date": "2017-4-16"
}
},
{
"_index": "website",
"_type": "blog",
"_id": "3",
"_score": 0.5446649,
"_source": {
"title": "title3",
"text": "最美的太阳",
"date": "2017-4-16"
}
},
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_score": 0.48515025,
"_source": {
"title": "liuyang",
"text": "太阳在头顶之上",
"date": "2017-4-16"
}
}
]
}
}
全文搜索
在linux中输入:
curl -XGET 'http://192.168.91.129:9200/_search' -d '{"query":{"match":{"text":"太阳"}}}'
后面的JSON为搜索的具体field,这样就可以做到在关系型数据库中很难做到的全文检索。
从输出结果中可以看到,每一个document都有对应的_score字段,这就是对此document的相关性评分。
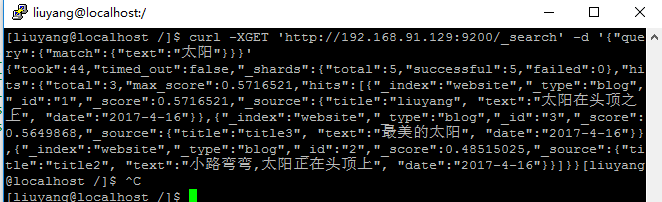
格式化输出:
{
"took": 44,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.5716521,
"hits": [
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_score": 0.5716521,
"_source": {
"title": "liuyang",
"text": "太阳在头顶之上",
"date": "2017-4-16"
}
},
{
"_index": "website",
"_type": "blog",
"_id": "3",
"_score": 0.5649868,
"_source": {
"title": "title3",
"text": "最美的太阳",
"date": "2017-4-16"
}
},
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_score": 0.48515025,
"_source": {
"title": "title2",
"text": "小路弯弯,太阳正在头顶上",
"date": "2017-4-16"
}
}
]
}
}
通过对比两种搜索方式的结果可知,使用全文搜索的匹配更加满足我们的预期。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号