C# 中 String.Length 对数字 文字 字母 的解决思路
大家天天用String 对象的Length属性,有没有发现他只是在机械的统计一下String对象上面的字符个数,而没有区分文字或数字说占字符的长度哪?
微软官方针对改属性给的解释是“当前字符串中字符的数量 ”
其实在C#.Net 这样的支持Unicode字符集的环境下,字符串处理时,英文、数字、汉字以及标点符号都是当着一个字符来看待的,但是英文、中文显示时所占宽度不一致 ,比如中文一个汉字占用2个字节长度,而英文占用1个字节长度。
比如有这样一个场景,当我们想根据一个字符串长度,截取部分文字显示到界面上 ,这时字符串中数字和文字都存在的话,这个长度显然是有错误的,最终界面上显示的也将会相当不整齐。
下面我就给出C#.Net中中英文混排的字符串,如何获取真实长度
我先给出目前网络上大家普遍的做法,主要有两种方式:
方式一:
string tipInfo = "123测ss试*.。空 格";
int length = System.Text.UnicodeEncoding.Default.GetByteCount(tipInfo);
方式二:
int length = Encoding.GetEncoding("GB2312").GetBytes(tipInfo.ToCharArray()).Length;
以上两种方案解决的方式是一样的,统一将数字,字母,文字,按两个字节来处理,也就是Unicode的做法。但这样做,截取的时候长度还是不统一,显示到界面上还是不对齐。当然想的快的朋友会说了,在结果的基础上除以2不就是总个数了吗,这样截取的结果应该是相同的了吧。这样想是没错,可你自己运行下就会发现,截取出来的长度还是不统一,有的长,有的短。
以下是我解决该问题的方式,我把数字,字母,文字分别统计,数字和字母两个为一个,这样显示到界面上,截取出来的长度是相同的。
{
string tempStr = tString;
int Count = 0;
int temp = 0;
for (int i = 0; i < tempStr.Length; i++)
{
string Char = tempStr.Substring(i, 1);
int byteCount = Encoding.Default.GetByteCount(Char);
if (byteCount == 1)
{
temp++;
if (temp == 2)
{
Count++;
temp = 0;
}
}
else if (byteCount > 1)
{
Count++;
}
}
return Count;
}
如果大家还有什么好的想法,欢迎留言指正。
以上三种方案执行后的结果: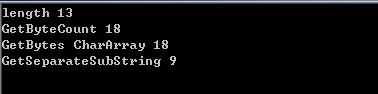

 浙公网安备 33010602011771号
浙公网安备 33010602011771号