

数据库临时表的使用
一、什么是临时表
临时表就是用来暂时保存临时数据(亦或叫中间数据) 的一个数据库对象, 它和普通表有些类似, 然而又有很大区别。 它只能存储在临时表空间, 而非用户的表空间。 临时表是会话或事务级别的, 只对当前会话或事务可见。 每个会话只能查看和修改自己的数据。
临时表的分类:
事务级 (On Commit Delete Rows)
数据在 Transaction 期间有效一旦COMMIT后,rollback,断开连接,数据就被自动 TRUNCATE
创建方式:

SQL> create global temporary table t_tmp_tab (id number,name varchar2(20)) on commit delete rows; Table created. SQL> desc t_tmp_tab Name Null Type ----------------------------------------------------- -------- ------------------------------------ ID NUMBER NAME VARCHAR2(20) SQL> insert into t_tmp_tab select empno,ename from emp where deptno=10; 3 rows created. SQL> select * from t_tmp_tab; ID NAME ---------- -------------------- 7782 CLARK 7839 KING 7934 MILLER SQL> commit; Commit complete. #事务提交后,再次查询,数据已经被清空 SQL> select * from t_tmp_tab; no rows selected SQL>
session级 (On Commit Preserve Rows)
数据在 Session 期间有效一旦关闭了Session 或 Log Off 后,数据就被自动 TRUNCATE
创建方式:
SQL> create global temporary table s_tab_tmp (id number,name varchar2(20)) on commit preserve rows; Table created. SQL> insert into s_tab_tmp select empno,ename from emp where deptno=10; 3 rows created. SQL> commit; Commit complete. SQL> select * from s_tab_tmp; ID NAME ---------- -------------------- 7782 CLARK 7839 KING 7934 MILLER SQL> exit #重新登录 #断开会话,重新连接后,数据被清空 SQL> select * from s_tab_tmp; no rows selected SQL>
二、临时表的应用场景
复杂查询优化:当需要进行复杂的数据查询和分析时,可以使用临时表来存储中间结果,以便后续查询使用。通过将中间结果存储在临时表中,可以减少查询的复杂性和提高性能。
数据筛选和过滤:临时表可以用于存储满足特定条件的数据子集。通过将数据筛选和过滤的结果存储在临时表中,可以简化后续的查询和操作,并提高查询的效率。
数据转换和清洗:在进行数据转换和清洗的过程中,临时表可以作为中间存储结构。可以将原始数据导入临时表中,对数据进行转换、清洗和规范化,然后将处理后的数据插入到目标表中。
大批量数据处理:当需要处理大量数据时,临时表可以作为临时存储结构来处理数据。可以将大量数据分批次导入到临时表中,然后对临时表中的数据进行批量处理,最后将结果导入到目标表或其他系统中。
过程性操作:临时表可用于存储在过程性操作中使用的临时数据。例如,在存储过程或函数中,可以使用临时表来存储中间结果,以便在过程执行过程中使用和处理。
会话级别的数据共享:临时表在同一个数据库连接会话中的多个查询之间共享数据。这种共享能力可以用于在一个会话中的多个查询中共享临时结果,从而提高查询的可读性和可维护性。
表关联和数据比较:临时表可以用于表关联操作和数据比较。可以将需要关联或比较的数据存储在临时表中,然后通过临时表进行连接操作或数据比较。
三、临时表的优缺点
优点:
临时性:临时表只在当前会话中存在,会话结束后自动销毁,不占用永久存储空间。这减少了数据库中的数据冗余,保持数据库的整洁性。
提高性能:通过使用临时表存储中间结果,可以优化复杂查询的性能。临时表提供了更好的可读性和可优化性,同时还可以通过索引等技术进一步提高查询性能。
共享数据:临时表在同一个会话中的多个查询之间共享数据,这使得复杂查询更易于编写和维护。它还可以在存储和检索数据方面提供更高的灵活性。
缺点:
数据丢失:临时表只在当前会话中存在,会话结束后数据会被自动清除。如果需要长期存储数据,临时表不适合使用。
资源占用:临时表占用数据库的内存和其他资源。当临时表的数据量较大或会话并发量较高时,可能会对数据库的性能和资源利用产生一定的影响。
命名冲突:临时表的命名通常以特定前缀或后缀来标识,以与普通表区分开。但如果命名不当,可能会导致与其他表发生命名冲突,造成意外的结果。
总结:在使用临时表时,需要根据具体的需求和场景权衡其优缺点,确保正确使用临时表的优势,并避免潜在的缺点。
四、clickhouse临时表的存储
ClickHouse临时表是存储在内存中的表,用于存储临时数据,仅在会话期间存在并可用。临时表的数据在内存中进行存储和处理,不会持久化到磁盘上
五、clickhouse临时表应用
1. 创建语法
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) [ENGINE = engine]
2. 使用示例
示例1:
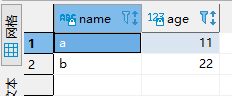
CREATE TEMPORARY TABLE IF NOT EXISTS t1 ( name String not null, age UInt8 not null ) ENGINE = Memory order by name; insert into t1 (name, age) values ('a', 11),('b', 22); select * from t1
注:临时表只能使用Memory引擎
执行结果:
示例2,复杂逻辑场景,可以这样用:
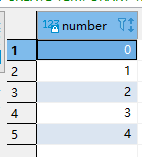
CREATE TEMPORARY TABLE IF NOT EXISTS temp_t as with t1 as( select * from numbers(5) ) select * from t1; select * from temp_t;
执行结果:
示例3,多个临时表:
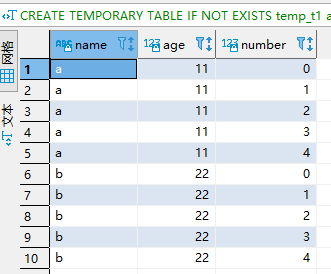
CREATE TEMPORARY TABLE IF NOT EXISTS temp_t1 as with t1 as( select * from numbers(5) ) select * from t1; CREATE TEMPORARY TABLE IF NOT EXISTS temp_t2 ( name String not null, age UInt8 not null ) ENGINE = Memory order by name; insert into temp_t2 (name, age) values ('a', 11),('b', 22); select * from temp_t2,temp_t1
执行结果:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2021-09-26 gp堆表AO表、行存和列存