

python面试题总结
1.python多线程:
1.1 不是真正的多线程
python中存在一个全局解释器锁(GIL),在任意时刻只能由一个线程在解释器中运行。因此Python中的多线程是表面上的多线程(同一时刻只有一个线程),不是真正的多线程。
1.2 python多线程使用场景:
适用于io密集型程序。可以让IO堵塞的时间切换到其他线程做其他的任务,很适合爬虫或者文件的操作。
2.python内存管理
2.1.垃圾回收
2.1.1 被回收的对象
当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(objectdeallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动,将没用的对象(引用计数为0的对象)清除。阈值查询方法:
import gc print(gc.get_threshold()) # (700, 10, 10) 700表示启动垃圾回收的阈值,后面两个10分别表示每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收。
2.1.2 回收策略-分代回收
- Python将所有的对象分为0,1,2三代;新建的对象为0代对象,经历过一次垃圾回收幸存下来的对象升级为1代对象。经过两次及以上次数的回收幸存下的为2代对象。
- 垃圾回收启动时,一定会扫描所有的0代对象。如果0代经过一定次数垃圾回收,那么就启动对0代和1代的扫描清理。当1代也经历了一定次数的垃圾回收后,那么会启动对0,1,2,即对所有对象进行扫描。具体经过多少次启动下一代对象垃圾回收可通过以下方法查询
import gc print(gc.get_threshold()) # (700, 10, 10) 700表示启动垃圾回收的阈值,后面两个10分别表示每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收。
2.1.3 回收策略-标记清除:
通过“标记-清除”解决容器对象可能产生的循环引用的问题
注:垃圾回收时,Python不能进行其它的任务,频繁的垃圾回收将大大降低Python的工作效率;
2.2 内存分配:内存池
2.2.1 内存池
python分为大内存和小内存。大小以256字节为界限,大内存使用Malloc进行分配,小内存则使用内存池进行分配。
2.2.2 小整数池
Python实现int的时候有个小整数池。为了避免因创建相同的值而重复申请内存空间所带来的效率问题, Python解释器会在启动时创建出小整数池,范围是[-5,256],该范围内的小整数对象是全局解释器范围内被重复使用,永远不会被垃圾回收机制回收。
注:字符串也有类似的机制,较为复杂可参考下面博客
https://www.cnblogs.com/TMesh/p/11731010.html
3.单例模式
https://www.cnblogs.com/liuxuelin/p/14483561.html
4.Python2和Python3区别
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print 'hi'
2、Python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、Python2中使用ascii编码,python中使用utf-8编码
4、Python2中unicode表示字符串序列,str表示字节序列
Python3中str表示字符串序列,byte表示字节序列
5、Python2中为正常显示中文,引入coding声明,python3中不需要
6、Python2中是raw_input()函数,python3中是input()函数
7、Python2 中除法默认向下取整,因此 1/2 = 0,为整型。而 Python3 中的除法为正常除法,会保留小数位,因此 1/2 = 0.5,为浮点型。
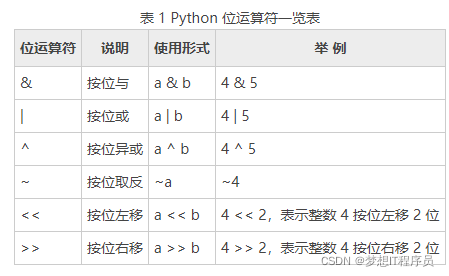
5.python位运算符
6.协程
协程,英文Coroutines,是一种比线程更加轻量级的存在。
协程不是进程,也不是线程,它就是一个可以在某个地方挂起的特殊函数,并且可以重新在挂起处继续运行。所以说,协程与进程、线程相比,不是一个维度的概念。
一个进程可以包含多个线程,一个线程也可以包含多个协程,也就是说,一个线程内可以有多个那样的特殊函数在运行。但是有一点,必须明确,一个线程内的多个协程的运行是串行的。如果有多核CPU的话,多个进程或一个进程内的多个线程是可以并行运行的,但是一个线程内的多个协程却绝对串行的,无论有多少个CPU(核)。这个比较好理解,毕竟协程虽然是一个特殊的函数,但仍然是一个函数。一个线程内可以运行多个函数,但是这些函数都是串行运行的。当一个协程运行时,其他协程必须挂起。
7.@property
@property将方法转为属性,该属性为只读属性,只可访问但是不可以修改,使用对象.方法名来访问该属性,但是方法不能再加小括号
8.cookie和session
http协议是无状态的。即http协议对事务的处理没有记忆能力。为了弥补这种不足,产生了两项记录http状态的技术,一个叫做Cookie,一个叫做Session。session与cookie属于一种会话控制技术.常用在身份识别,登录验证,数据传输等
cookie
cookie是远程浏览器存储数据以此追踪用户和识别用户的的机制,从实现来说,cookie是存储在客户端上的一个数据片段。
1.客户端向服务端发起一个http请求.
2.服务端设置一个创建cookie的指令,响应给客户端.
3.客户端收到服务端响应的指令,根据指令在客户端创建一个cookie.
4.挡下一次请求时,客户端携带这个cookie向服务端发送请求.
session
1.客户端向服务端发起请求,建立通信
2.服务端根据设置的session创建指令,在服务端创建一个编号为sessionid的文件,里面的值就是session具体的值(组成部分 变量名 | 类型 :长度:值).
3.服务端将创建好的sessionid编号响应给客户端,客户则将该编号存在cookie中(一般我们在浏览器存储的调试栏中会发现cookie中有一个PHPSESSID的键,这就是sessionid,当然这个名称,我可以通过设置服务端是可以改变的).
.当下一次请求时,客户端将这个sessionid携带在请求中,发送给服务端,服务端根据这个sessionid来做一些业务判断.
9. 字符串前导r的作用
Python 中字符串的前导 r 代表原始字符串标识符,该字符串中的特殊符号不会被转义,适用于正则表达式中繁杂的特殊符号表示。
最典型的例子,如要输出字符串 \n,由于反斜杠的转义,因此一般的输出语句为:
这里的 \\ 将被转义为 \ 。而采用原始字符串输出时,则不会对字符串进行转义:
10. dict方法总结:
1.fromkeys方法
- 为dict的一个静态方法,用于根据序列创建一个新字典,key为序列的值,value为None
d = dict.fromkeys(['a', 'b']) print(d) e = d.fromkeys(['c', 'd']) print(d, e)
执行结果:
{'a': None, 'b': None}
{'a': None, 'b': None} {'c': None, 'd': None}
11.list方法总结
1.remove()
list.remove(obj)表示移除列表中某个值的第一个匹配项
2.+、+=
- 对于+=操作,如果是可变对象,则操作前后序列的id值不变,如果是不可变对象,则操作前后序列的id值改变
lis = [1,3,2] a = id(lis) lis += [4,5] b = id(lis) print(a==b) # True
3.sorted(list)
- 使用sorted()进行排序会生成新的序列,生成的新序列和原序列id值必然不同
lis = [1, 3, 2] a = id(lis) lis = sorted(lis) b = id(lis) print(a == b) # False
4.列表乘法

a = [[1,2]]
b = a * 2 # b -> [[1, 2], [1, 2]]
# 修改b[0][0], b[0][1]同样被修改了, 这是因为b[0]与b[1]有相同的地址
b[0][0] = 3
print(b) # [[3, 2], [3, 2]]
# 打印b[0]和b[1]的 id
print(id(b[0])) # 1904838110536
print(id(b[1])) # 1904838110536
5切片
t1 = (1,2,3) t2 = t1[:] print(t1 is t2) # True
lis1 = [1,2,3]
lis2 = lis1[:]
print(id(lis1)==id(lis2)) # False
Python出于对性能的考虑,但凡是不可变对象,在同一个代码块中的对象,只有是值相同的对象,就不会重复创建,而是直接引用已经存在的对象
6.index()
在Python3中,list.index(obj)表示从列表中找出某个值第一个匹配项的索引位置
12.str方法总结
1.upper()、lower()、capitalize()、title()
str.upper() # 把所有字符中的小写字母转换成大写字母
str.lower() # 把所有字符中的大写字母转换成小写字母
str.capitalize() # 把第一个字母转化为大写字母,其余小写
str.title() # 把每个单词的第一个字母转化为大写,其余小写
a = "abCdEF123tsgtB" print(a.upper(), a.lower(), a.capitalize(), a.title())
执行结果:
ABCDEF123TSGTB abcdef123tsgtb Abcdef123tsgtb Abcdef123Tsgtb
2.find()
strs.find(str, beg=0, end=len(strs))表示在strs中返回第一次出现str的位置下标,没有则返回-1,beg表示在strs中的开始索引,默认为0,end结束索引,默认为strs的长度
3.strip()
将字符串首尾出现的括号里的所有字符都删除
if __name__ == '__main__': strs = 'abbacabb' print(strs.strip('ab')) # 输出:c
4.count(),index(), in
5.center(width[,fillchar])
13.可哈希对象
可哈希对象:数字类型(int,float,bool)、字符串str、元组tuple、自定义类的对象
不可哈希对象:列表,集合和字典
14.Python 中的Magic Method(魔术方法)或特殊变量
1.__new__()
- __new__是在实例创建之前被调用的,因为它的任务就是创建实例然后返回该实例,是个静态方法。
2.__getitem__()
- 根据索引访问对象元素,会调用__getitem__(), 如obj[1]
- 对对象的迭代(for i in obj ...)需要调用__iter__,如果没有定义该方法,python会调用__getitem__(),让迭代和in运算符可用
3.__len__()
- len(obj)是调用这个方法
- 如果需要将一个对象变为一个序列,必须实现两个方法:__len__和__getitem__
4.__slots__
- . __slots__是python类中的特殊变量,用于限制实例对象的属性,如__slots__='x','y',那么实例对象的属性就只能从这些里面找
- 继承关系中,如果子类没有定义__slots__属性,则不会继承父类的__slots__属性,如果子类定义了__slots__属性,则子类对象允许的实例属性包括子类的__slots__加上父类的__slots_。
class A(): __slots__ = 'x', 'y' def __init__(self): self.x = 1 self.y = 3 self.ss = 4 # 实例化时候会报错:AttributeError: 'A' object has no attribute 'ss' def ab(self): print(1)
魔术方法汇总:
__new__、__init__、__del__ 创建和销毁对象相关
__add__、__sub__、__mul__、__div__、__floordiv__、__mod__ 算术运算符相关
__eq__、__ne__、__lt__、__gt__、__le__、__ge__ 关系运算符相关
__pos__、__neg__、__invert__ 一元运算符相关
__lshift__、__rshift__、__and__、__or__、__xor__ 位运算相关
__enter__、__exit__ 上下文管理器协议
__iter__、__next__、__reversed__ 迭代器协议
__int__、__long__、__float__、__oct__、__hex__ 类型/进制转换相关
__str__、__repr__、__hash__、__dir__ 对象表述相关
__len__、__getitem__、__setitem__、__contains__、__missing__ 序列相关
__copy__、__deepcopy__ 对象拷贝相关
__call__、__setattr__、__getattr__、__delattr__ 其他魔术方法
14.闭包的延迟策略
执行下列程序,输出结果为()
def fn():
t = []
i = 0
while i < 2:
t.append(lambda x: print(i*x,end=","))
i += 1
return t
for f in fn():
f(2)
A. 4,4, B 2,2, C 0,1, D 0,2,
函数fn存在闭包现象,自由变量是i,由于python闭包采用延迟绑定,也就是当调用匿名函数时,循环早已结束,此时i的值为2,所以输出结果都为2*2=4,正确答案为A。
15.元组乘法
a = (1, 2, 3)
a*3 -> (1,2,3,1,2,3,1,2,3)
16.算数运算:
1.divmod()
如 divmod(100, 14) -> (7, 2)
divmod将除法运算和取余运算结合在一起,结果返回一个tuple(元组)(商和余数)
17.__name__
__name__这个系统变量显示了当前模块执行过程中的名称,如果当前程序运行在这个模块中,__name__ 的名称就是__main__如果不是,则为这个模块的名称。
18:try...except...else
try: result = 1 / 0 print(1,end=" ") except ZeroDivisionError: print(2,end=" ") except Exception: print(3,end=" ") else:
print(4)
执行结果:
2
在try...except...else结构中,当执行try程序块的语句时,若出现异常的语句,则不会继续执行try还未执行的代码,而是直接跳到except程序块,由于0不能作为分母,其抛出的异常对象属于异常类ZeroDivisionError,结果输出2,当异常被处理完时,会直接跳出except程序块,当try程序块没有出现异常时,不会执行except而执行else语句,出现异常时则执行except而不执行else,所以最终输出结果是2。
19.类变量和实例变量
类属性可以为实例属性提供默认值,实例属性不会影响到类属性的值,也不会影响到其他实例属性。
class Base(object): count = 1 def __init__(self): pass b1 = Base() b2 = Base() b1.count = b1.count + 1 # b1本来没有count,这里会新增一个实例b1的count变量,默认值取类的count的值 print(b1.count,end=" ") print(Base.count,end=" ") # 实例的变量不影响类的变量 print(b2.count) # b1实例的变量修改不会影响b2的实例的变量
输出:
2 1 1
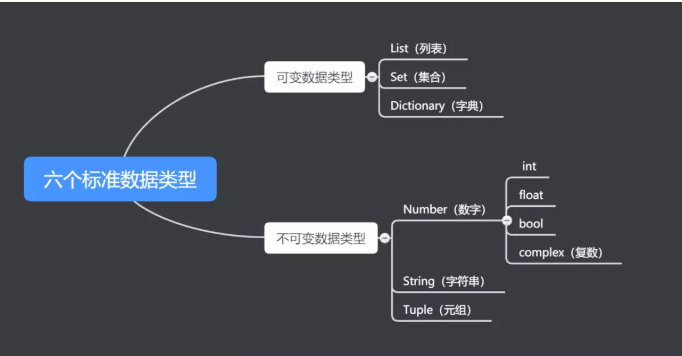
20. 可变类型不可变类型
21.导入模块的搜索顺序:
- 程序的根目录(即当前运行python文件所在的目录)
- PYTHONPATH环境变量设置的目录
- 第三方扩展的site-package目录
- 任何能够找到的.pth文件的内容
上面路径都会加入到sys.path中,具体导入顺序可通过查看sys.path得到:
D:\work\code\test_pro\p_test # 程序的根目录 D:\apps # PYTHONPATH所在路径,这个环境变量我自己设置的 D:\apps\JetBrains\PyCharm 2019.1.4\helpers\pycharm_display D:\work\python\Python38\python38.zip # 这几个为python标准库目录 D:\work\python\Python38\DLLs D:\work\python\Python38\lib D:\work\python\Python38 D:\work\virtualenv\tenantinstance D:\work\virtualenv\tenantinstance\lib\site-packages # 第三方包目录 D:\apps\JetBrains\PyCharm 2019.1.4\helpers\pycharm_matplotlib_backend
22.python内建对象、内建模块、标准库,第三方库,自定义模块
https://blog.csdn.net/zhouyinlong1990/article/details/122704690
23.没有参数的lamdba表达式定义
a = lambda: print(2) b = lambda i: print(i) a() # 2 b("ab") # ab
24.全局变量、局部变量
a = 1 num = 2 def t(): c = a + 1 num = num + 1 # 会报错:UnboundLocalError: local variable 'num' referenced before assignment t()
虽然在函数外部声明num 为全局变量,但若函数体内对num变量重新赋值,其结果会使得函数内部屏蔽外面的全局变量num,此时语句num += 1就会抛出异常,即num变量没有先赋值就直接引用了。
25.私有属性
私有属性,在类外部使用时,可以通过实例名._类名__xxx来访问。
class Cat: def __init__(self,color="白色"): self.__color = color cat = Cat("绿色") print(cat._Cat__color)
26.nonlocal、global 关键字的用法:
nonlocal 用来声明外层的局部变量。
global 用来声明全局变量。
a = 100 def outer(): b = 10 def inner(): nonlocal b # 声明外部函数的局部变量 print(r"inner b:", b) b = 20 global a # 声明全局变量 a = 1000 inner() print(r"outer b:", b) outer() print("a :" ,a)
输出:
inner b: 10 outer b: 20 a : 1000
27python中主要存在四种命名方式:
28.python中的迭代器和生成器
迭代器:可遍历且可以记住遍历所在位置的对象就是迭代器。
- 把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__()
生成器:使用了 yield 的函数被称为生成器(generator)。
- 跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作
- 生成器就是一个特殊的迭代器
29. Python中为什么没有函数重载?
首先Python是解释型语言,函数重载现象通常出现在编译型语言中。其次Python是动态类型语言,函数的参数没有类型约束,也就无法根据参数类型来区分重载。再者Python中函数的参数可以有默认值,可以使用可变参数和关键字参数,因此即便没有函数重载,也要可以让一个函数根据调用者传入的参数产生不同的行为。
30. __init__和__new__方法有什么区别?
Python中调用构造器创建对象属于两阶段构造过程,首先执行__new__方法获得保存对象所需的内存空间,再通过__init__执行对内存空间数据的填充(对象属性的初始化)。__new__方法的返回值是创建好的Python对象(的引用),而__init__方法的第一个参数就是这个对象(的引用),所以在__init__中可以完成对对象的初始化操作。__new__是类方法,它的第一个参数是类,__init__是对象方法,它的第一个参数是对象。
31. python变量的作用域
python的作用域一共有四层:局部作用域 L (Local)-->>闭包函数外的函数中 E ( Enclosing )嵌套作用域 -->> 全局作用域 G ( Global ) -->> 内建作用域 B (Built-in)。记成LEGB
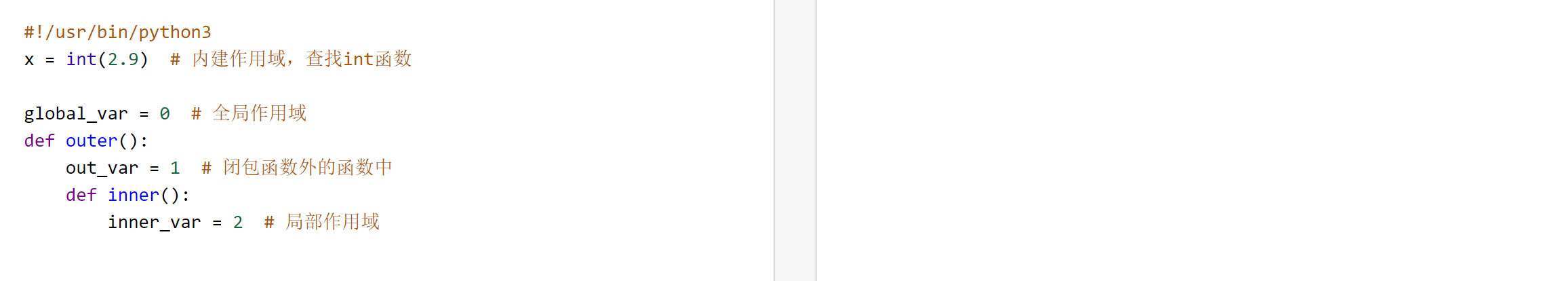
32. 闭包
闭包可以理解为能够读取其他函数内部变量的函数。正在情况下,函数的局部变量在函数调用结束之后就结束了生命周期,但是闭包使得局部变量的生命周期得到了延展。使用闭包的时候需要注意,闭包会使得函数中创建的对象不会被垃圾回收,可能会导致很大的内存开销,所以闭包一定不能滥用。
33.Mq消息丢失解决方案
https://blog.csdn.net/weixin_43409765/article/details/121283851


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?