

postgresql执行计划
一、执行计划
1.执行计划是什么:
一条sql以最快最低消耗获取出所需数据的一个执行过程。
SQL 是一种“描述型”语言。与“过程型”语言不同,用户在使用 SQL 时,只描述了“要做什么”,而不是“怎么做”。因此,数据库在接收到 SQL 查询时,必须为其生成一个“执行计划”。执行计划可以告诉我们SQL如何使用索引,连接查询的执行顺序,查询的数据行数等
执行计划本质上是由物理操作符构成的一棵执行树。物理操作符一般对应一个关系操作,如表扫描、联接、聚合、排序等。执行计划通过将不同的物理操作符按照一定的先后顺序组织在一棵执行树中,最终完成该 SQL 查询。
2.执行计划的作用:
在sql优化过程中,查看sql是如何执行的,究竟要涉及多少行、使用哪些索引、运行时间等
二、查看执行计划sql语法
1.语法

EXPLAIN [ ( option [, ...] ) ] statement EXPLAIN [ ANALYZE ] [ VERBOSE ] statement 这里 option可以是: ANALYZE [ boolean ] VERBOSE [ boolean ] COSTS [ boolean ] BUFFERS [ boolean ] TIMING [ boolean ] FORMAT { TEXT | XML | JSON | YAML }
-
analyze:执行语句并显示真正的运行时间和其它统计信息,会真正执行SQL语句;
-
verbose:显示额外的信息,尤其是计划树中每个节点的字段列表,schema识别表和函数名称。总是打印统计数据中显示的每个触发器的名字;
-
costs:包括每个计划节点的启动成本预估和总成本的消耗,也包括行数和行宽度的预估;
-
buffers:使用信息,特别包括共享块命中、读、脏和写的次数,本地块命中、读、脏和写,临时块读和写的次数;
-
timing:在输出中包含实际启动时间和每个节点花费的时间,重复读系统块在某些系统上会显著的减缓查询的速度,只在ANALYZE也启用的时候使用;
-
format:声明输出格式,可以为TEXT、XML、JSON 或 YAML,默认 text;
2.示例
2.1. EXPLAIN
EXPLAIN SELECT * FROM t2
执行结果:
Seq Scan on t2 (cost=0.00..11.10 rows=110 width=670)
2.2 EXPLAIN ANALYZE:
EXPLAIN ANALYZE SELECT * FROM t2
执行结果:
Seq Scan on t2 (cost=0.00..11.10 rows=110 width=670) (actual time=0.009..0.011 rows=14 loops=1) Planning Time: 0.091 ms Execution Time: 0.055 ms
2.3. EXPLAIN ANALYZE VERBOSE
EXPLAIN ANALYZE VERBOSE SELECT * FROM t2
执行结果:
Seq Scan on public.t2 (cost=0.00..11.10 rows=110 width=670) (actual time=0.029..0.030 rows=14 loops=1)
Output: id, name, age, address
Planning Time: 0.038 ms
Execution Time: 0.040 ms
3执行计划各部分的含义:
一个较为复杂的例子:
CREATE TABLE "public"."t2" ( "id" int4 NOT NULL DEFAULT nextval('t2_id_seq'::regclass), "name" varchar(64) COLLATE "pg_catalog"."default", "age" int4, "address" varchar(255) COLLATE "pg_catalog"."default", CONSTRAINT "t2_pkey" PRIMARY KEY ("id") ); create table t3(id int,info text); create table t4(id int,info text); CREATE INDEX t3_id_index ON t3 (id); insert into t3 select generate_series(1,100000),'bill'||generate_series(1,100000); insert into t4 select generate_series(1,100000),'bill'||generate_series(1,100000); CREATE INDEX t4_id_index ON t4 (id); explain ANALYZE select t4.id, sum(t4.id) from t4 inner join (select t3.id, t3.info from t3 WHERE t3.id > 687) tt on (tt.id=t4.id) where tt.info like '%bill%' AND t4.id in (SELECT id FROM t2) GROUP BY t4.id ORDER BY t4.id
执行计划:
GroupAggregate (cost=0.81..43.78 rows=264 width=12) (actual time=0.316..0.317 rows=0 loops=1) Group Key: t4.id -> Merge Join (cost=0.81..39.82 rows=264 width=4) (actual time=0.315..0.316 rows=0 loops=1) Merge Cond: (t3.id = t2.id) -> Merge Join (cost=0.62..8265.90 rows=99270 width=8) (actual time=0.278..0.278 rows=1 loops=1) Merge Cond: (t4.id = t3.id) -> Index Only Scan using t4_id_index on t4 (cost=0.29..3148.29 rows=100000 width=4) (actual time=0.013..0.170 rows=688 loops=1) Heap Fetches: 688 -> Index Scan using t3_id_index on t3 (cost=0.29..3626.89 rows=99270 width=4) (actual time=0.077..0.077 rows=1 loops=1) Index Cond: (id > 687) Filter: (info ~~ '%bill%'::text) -> Index Only Scan using t2_pkey on t2 (cost=0.15..12.14 rows=266 width=4) (actual time=0.009..0.025 rows=266 loops=1) Heap Fetches: 0 Planning Time: 107.100 ms Execution Time: 0.502 ms
3.1.运算类型:
| 执行计划运算类型 | 操作说明 | 是否有启动时间 |
|---|---|---|
| Seq Scan | 扫描表 | 无启动时间 |
| Index Scan | 索引扫描 | 无启动时间 |
| Bitmap Index Scan | 索引扫描 | 有启动时间 |
| Bitmap Heap Scan | 索引扫描 | 有启动时间 |
| Subquery Scan | 子查询 | 无启动时间 |
| Tid Scan | ctid = …条件 | 无启动时间 |
| Function Scan | 函数扫描 | 无启动时间 |
| Nested Loop | 循环结合 | 无启动时间 |
| Merge Join | 合并结合 | 有启动时间 |
| Hash Join | 哈希结合 | 有启动时间 |
| Sort | 排序,ORDER BY操作 | 有启动时间 |
| Hash | 哈希运算 | 有启动时间 |
| Result | 函数扫描,和具体的表无关 | 无启动时间 |
| Unique | DISTINCT,UNION操作 | 有启动时间 |
| Limit | LIMIT,OFFSET操作 | 有启动时间 |
| Aggregate | count, sum,avg, stddev集约函数 | 有启动时间 |
| Group | GROUP BY分组操作 | 有启动时间 |
| Append | UNION操作 | 无启动时间 |
| Materialize | 子查询 | 有启动时间 |
| SetOp | INTERCECT,EXCEPT |
有启动时 |
3.2计划结果说明
1. cost
含义:这个计划节点的预计的启动开销和总开销
详细描述:启动开销是指一个计划节点在返回结果之前花费的开销,如果是在一个排序节点里,那就是指执行排序花费的开销。 总开销是指一个计划节点从开始到运行完成,即所有可用行被检索完后,总共花费的开销。实际上,一个节点的父节点可能会在子节点返回一部分结果后,停止继续读取剩余的行,如Limit节点。
2. rows
含义:这个计划节点的预计输出行数
详细描述:在带有ANALYZE选项时,SQL语句会实际运行,这时一个计划节点的代价输出会包含两部分,前面部分是预计的代价,后面部分是实际的代价。前面部分中rows是指预计输出行数,后面部分是指实际输出行数。如果中间节点返回的数据量过大,最终返回的数据量很小,或许可以考虑将中间节点以下的查询修改成物化视图的形式。
3. width
含义:这个计划节点返回行的预计平均宽度(以字节计算)
详细描述:如果一个扫描节点返回行的平均宽度明显小于子节点返回行的平均宽度,说明从子节点读取的大部分数据是无用的,或许应该考虑一下调整SQL语句或表的相关设计,比如让执行计划尽量选择Index Only Scan,或者对表进行垂直拆分。
4. actual time
含义:这个计划节点的实际启动时间和总运行时间
详细描述:启动时间是指一个计划节点在返回第一行记录之前花费的时间。 总运行时间是指一个计划节点从开始到运行完成,即所有可用行被检索完后,总共花费的时间。
5. loops
含义:这个计划节点的实际重启次数
详细描述:如果一个计划节点在运行过程中,它的相关参数值(如绑定变量)发生了变化,就需要重新运行这个计划节点。
6. Filter
含义:这个扫描节点的过滤条件
详细描述:对于一个表的扫描节点,如果相关的条件表达式不能对应到表上的某个索引,可能需要分析一下具体的原因和影响,比如该表相关的字段在表达式中需要进行隐式类型转换,那么即使在该字段上存在索引,也不可能被使用到。如:((b.intcol)::numeric > 99.0)
7. Index Cond
含义:这个索引扫描节点的索引匹配条件
详细描述:说明用到了表上的某个索引。
8. Rows Removed by Filter
含义:这个扫描节点通过过滤条件过滤掉的行数
详细描述:如果一个扫描节点的实际输出行数明显小于通过过滤条件过滤掉的行数,说明这个计划节点在运行过程中的大量计算是无用的,或者说是没有实际产出的,那么这个SQL语句或者表的相关设计可能不是特别好。
三、执行计划中扫描方式
1顺序扫描Seq Scan
顺序扫描实际上就是全表扫描,没有任何可用索引或者不适合走索引的情况下的一种查询行为
2.索引扫描Index Scan(包含回表过程)
EXPLAIN ANALYZE SELECT * FROM t2 WHERE id =3
执行结果 :
Index Scan using t2_pkey on t2 (cost=0.14..8.16 rows=1 width=670) (actual time=0.015..0.016 rows=1 loops=1) Index Cond: (id = 3) Planning Time: 0.066 ms Execution Time: 0.032 ms
说明:
回表:就是扫描索引获取到需要查询的行地址信息后,根据行地址信息,定位到对应行并获取这些行数据的过程
3. 索引扫描Index Only Scan (不包含回表过程)
EXPLAIN ANALYZE SELECT id FROM t2 WHERE id =3
执行结果:
Index Only Scan using t2_pkey on t2 (cost=0.14..8.16 rows=1 width=4) (actual time=0.039..0.041 rows=1 loops=1) Index Cond: (id = 3) Heap Fetches: 1 Planning Time: 0.059 ms Execution Time: 0.054 ms
说明:
不需要回表的原因:相对于上面的sql语句,这里只查询了id, 而id正好就是查询时要扫描的索引的字段,索引中已经包含了id值,索引不需要再回表获取行数据。
4.位图索引扫描Bitmap Index Scan
四、表与表之间的连接处理方式
包括三种:loop join,merge join,hash join这三种join方式
当查询涉及两个以上的表时,最终结果必须由一个连接步骤树构成,每个连接步骤有两个输入。规划器会检查不同可能的连接序列来找到代价最小的那一个。
1.loop join
对左表中找到的每一行都要扫描右表一次。这种策略最容易实现但是可能非常耗时(不过,如果右表可以通过索引扫描,这将是一个不错的策略。因为可以用左表当前行的值来作为右表上索引扫描的键)。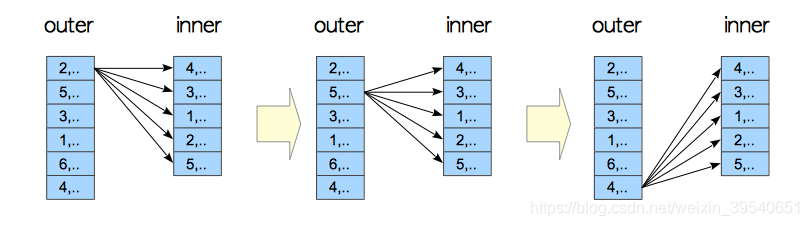
示例:
create table t3(id int,info text); create table t4(id int,info text); CREATE INDEX t3_id_index ON t3 (id); insert into t3 select generate_series(1,100000),'bill'||generate_series(1,100000); insert into t4 select generate_series(1,100000),'bill'||generate_series(1,100000); explain select * from t4 join t3 on (t3.id=t4.id) where t4.info='bill';
执行结果:
Nested Loop (cost=0.29..1799.32 rows=1 width=26) -> Seq Scan on t4 (cost=0.00..1791.00 rows=1 width=13) Filter: (info = 'bill'::text) -> Index Scan using t3_id_index on t3 (cost=0.29..8.31 rows=1 width=13) Index Cond: (id = t4.id)
说明:
- t3.id有索引,因此这里首先全表扫描t4, 获取到t4的每一个id后再t3表中通过索引扫描获取到匹配项
- 适合处理两个较小的结果集的场景
2.merge join:
在连接开始之前,每一个表都按照连接的列排好序。然后两个表会被并行扫描,匹配的行被整合成连接行。由于这种连接中每个表只被扫描一次。它所要求的排序可以通过一个显式的排序步骤得到,或使用一个连接键上的索引按适当顺序扫描关系得到。
示例:
create table t3(id int,info text); create table t4(id int,info text); CREATE INDEX t3_id_index ON t3 (id); insert into t3 select generate_series(1,100000),'bill'||generate_series(1,100000); insert into t4 select generate_series(1,100000),'bill'||generate_series(1,100000); explain select * from t4 inner join t3 on (t3.id=t4.id)
执行结果:
Merge Join (cost=8627.84..367318.87 rows=23603259 width=72) Merge Cond: (t3.id = t4.id) -> Index Scan using t3_id_index on t3 (cost=0.29..4298.90 rows=68707 width=36) -> Materialize (cost=8627.55..8971.08 rows=68707 width=36) -> Sort (cost=8627.55..8799.32 rows=68707 width=36) Sort Key: t4.id -> Seq Scan on t4 (cost=0.00..1228.07 rows=68707 width=36) JIT: Functions: 7 Options: Inlining false, Optimization false, Expressions true, Deforming true
说明:
- 上面执行计划中t3.id有索引,所以直接使用索引进行扫描,t4.id没有索引,因此进行全表扫描进行排序
- 适合处理两个有序结果集的场景,或者jion双方本身存在一致的索引键
3.hash join:
右表(outer)会先被扫描并且被载入到一个哈希表,使用连接列作为哈希键。接下来左表被扫描,扫描中找到的每一行的连接属性值被用作哈希键在哈希表中查找匹配的行。
示例:
create table t3(id int,info text); create table t4(id int,info text); CREATE INDEX t3_id_index ON t3 (id); insert into t3 select generate_series(1,100000),'bill'||generate_series(1,100000); insert into t4 select generate_series(1,100000),'bill'||generate_series(1,100000); CREATE INDEX t4_id_index ON t4 (id); explain select * from t4 inner join t3 on (t3.id=t4.id) where t3.id <400
执行结果:
Hash Join (cost=26.83..1947.01 rows=418 width=26) Hash Cond: (t4.id = t3.id) -> Seq Scan on t4 (cost=0.00..1541.00 rows=100000 width=13) -> Hash (cost=21.61..21.61 rows=418 width=13) -> Index Scan using t3_id_index on t3 (cost=0.29..21.61 rows=418 width=13) Index Cond: (id < 400)
说明:
- 使用索引扫描t3表并计算HASH值,然后全表扫描t4,将t4的id作为hash的key值找到与t3的匹配行


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构