

GIN索引
一、GIN
- Generalized Inverted Index, 通用倒排索引。索引结构为一个存储对(key, posting list)集合。
- 存储对(key, posting list)中的key是一个键值,posting list是一组出现过key的位置。如("hello", "14:17, 23:1,..."),hello为键,14:17, 23:1,...表示hello出现的位置,每个位置由“元组ID: 位置”表示。14:17表示第14号元组被索引属性中第17个位置。
- 通过这种索引可以快速查找到包含指定关键字的元组。特别适合于支持全文检索。开发这种索引的主要目的就是为了支持PG的高度可扩展的全文搜索
二、GIN的扩展性
- 允许在开发自定义数据类型时,通过设计适当的访问方法来实现GIN索引的应用。这些访问方法只需要考虑数据类型本身的语义,无需关心索引的并发操作、日志,搜索树结构等(由索引自身处理)。
- 一个数据类型的GIN索引需要实现五个方法即可:
- compare方法:比较两个键值a和b的大小,返回正值表示 a>b, 0 表示 a=b, 负值表示 a<b
- extractValue方法:根据参数inputvalue生成一个键值数组,并返回其指针,键值数组大小存放在另一个参数nkeys中
- extractQuery方法:根据一个查询(由参数query给定),生成一个用于查询的键值数组并返回其指针
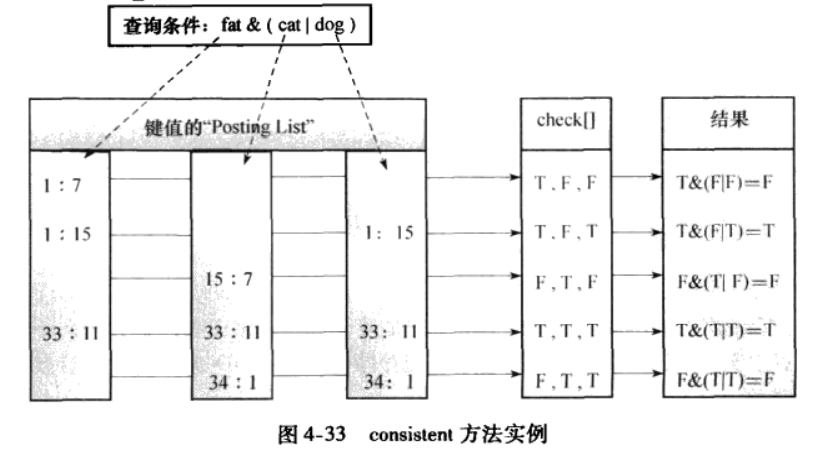
- consistent方法:检查索引值是否满足查询
5. comparePartial方法:将部分匹配的查询与索引值进行比较
三、PG中添加新的数据类型,并让GIN索引能支持该数据类型
1.添加数据类型
- 实现新数据类型的输入输出函数,并注册到数据库内部
- 基于上面的输入输出函数,创建数据类型
- 为新数据类型实现并注册各种操作符所需的函数,并为新数据类型创建操作符
2.实现上面提到的所需要的5种支持函数,并将函数注册到数据库内部
3.为新的数据类型创建一个操作符类,指定GIN索引所需要的5个支持函数
四、GIN索引的组织结构
GIN索引包括四个部分:
- Entry:索引中的一个词位,可理解为索引中一个键值
- Entry Tree:在一些Entry上构建的B-Tree
- Posting Tree:在一个Entry出现的物理位置上构建的B-tree
- Posting List:一个Entry出现的物理位置的列表
GIN索引实际上就是一个构建在Entry(键值)上的B-Tree索引(Entry Tree)。Entry Tree内部节点与普通B-Tree一样。叶子节点分两种情况:
- 如果该叶子节点包含的物理位置个数大于宏TOAST_INDEX_TARGET指定的值,则在这些物理位置上构建PostingTree(物理位置多,构建B-tree结构方便快速查找)
- 否则,叶子节点直接指向Posting List

GIN索引的五种页面类型:

五、GIN索引的操作
1.GIN索引的创建
- 从基表中依次取出基表元组,基于这些基表元组构建出若干个Entry及其Posting List
- 将这些Entry插入到GIN的索引结构中
在实现中,GIN索引并不是构建出一个Entry就立即将其插入到索引结构中,而是先放在一个“蓄积池”中,蓄积池填充到一定程度后才将其中的Entry插入到索引结构。将Entry及其位置信息插入到索引结构通过ginEntryInsert函数来完成,流程如下:

查找Entry是否存在, 存在则添加位置信息,不存在则先设置Entry位置再添加位置信息
2. GIN索引的查询
通过关键词与Entry匹配来查找其所在的元组。查找过程按照B-Tree结构进行搜索,调用consistent方法判断是否找到。最后返回符合查询条件的元组的物理位置


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构