20190919-3 效能分析
作业要求参见[https://edu.cnblogs.com/campus/nenu/2019fall/homework/7628]
• 要求0 以 战争与和平 作为输入文件,重读向由文件系统读入。连续三次运行,给出每次消耗时间、CPU参数。
运行方法
ptime wf -s < war_and_peace.txt
第一次运行:
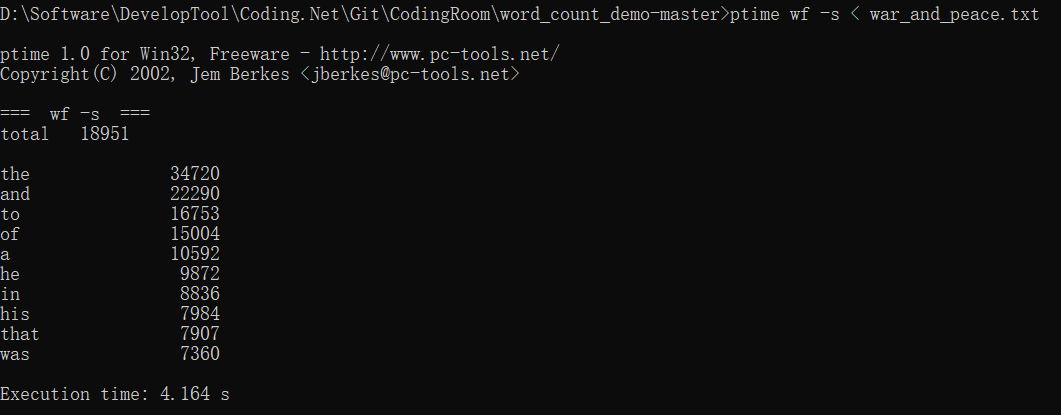
第二次运行:

第三次运行:

CPU参数:Intel(R) Core(TM) i3-8145U CPU @ 2.10GHz 2.30 GHz
第三次运行时间:4.164s
第三次运行时间:5.202s
第三次运行时间:4.167s
平均运行时间:4.511s
• 要求1 给出你猜测程序的瓶颈。
功能4在进行词频统计时,首先对文件中的字符逐个读取,然后根据特殊符号和空格,将这些字符逐个切分成单词,并在结构体数组中查找单词是否存在并按规则计数,最后对结构体数组按单词频率排序。由此分析,此程序主要在查找单词和排序单词两方面比较耗时。而在排序方面,使用的是C语言编译器函数库自带的快速排序函数qsort,因此在优化方面,我并不能保证做到更好。于是查找单词模块,成了我的重点猜测对象。
//顺序查找法 for (t = 0; t < count; t++) { if (strcmp((words + t)->words, temp) == 0) { (words + t)->frequent++; break; } } if (t == count) { (words + count)->frequent = 1; strcpy((words + count)->words, temp); count++; }
• 要求2 通过 profile 找出程序的瓶颈。
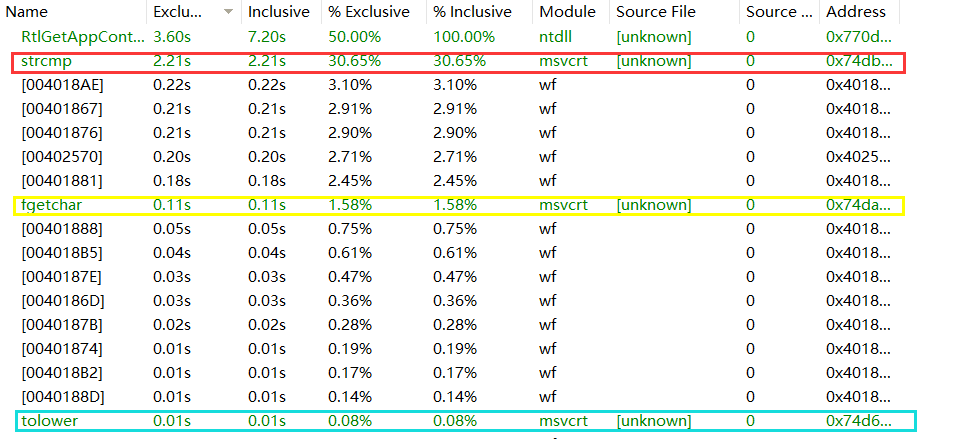
由此可见在执行过程中,最花费时间的三个函数按照从长到短,依次为strcmp、fgetchar、tolower,而其中strcmp主要集中在顺序查找时的比较上,因此可以断定,此项目瓶颈就在于查找上。
• 要求3 根据瓶颈,"尽力而为"地优化程序性能。
由于本人查找顺序表用的算法是顺序查找,因此先想到用折半查找法,但考虑到文本读取的时候,记录单词的结构体数组基本无序,因此按照理论来讲,折半查找也不会明显改善查找效率。即便是这样,在没有更好的方案的前提下,个人还是尝试用折半查找去改善查找效率。
int low, high, mid; low = 0; high = count; if (count == 0) { (words + count)->frequent = 1; count++; } while (low <= high) { mid = (low + high) / 2; if (strcmp((words + mid)->words, temp) == 0) { (words + t)->frequent++; break; } if (strcmp((words + mid)->words, temp) > 0) high = mid - 1; if (strcmp((words + mid)->words, temp) < 0) low = mid + 1; } if (low > high) { (words + count)->frequent = 1; count++; }
• 要求4 再次 profile,给出在 要求1 中的最花费时间的3个函数此时的花费。要求包括截图。
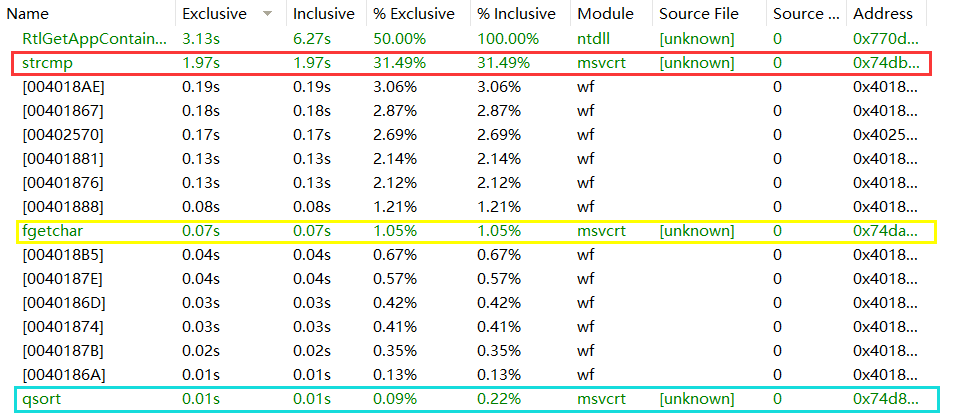
此次运行profile中可以看出,最花费时间的三个函数按照从长到短,依次为strcmp、fgetchar、qsort,而strcmp占比不但没有减小,反而略有增加,总体上来说,此次优化并不成功。
• 要求5 程序运行时间。
附上本人代码wf.exe程序git地址,供老师测试[https://e.coding.net/secret/ASETest1.git]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号