
MGR管理
一、选主算法
所有节点参与,版本号>权重>uuid
1) 版本号:版本小的优先成为primary,因为大的版本可以兼容版本小的
-- 小于8.0.16,按照版本号排序
-- 大于8.0.17 ,按照补丁版本号排序
2)节点权重,默认50,越⾼越靠前,最容易成为主
show variables like '%group_replication_member_weight%';
3)server_uuid:越⼩越在前
二、版本混⽤
三、滚动升级
四、数据同步
4.1 MGR 架构原理
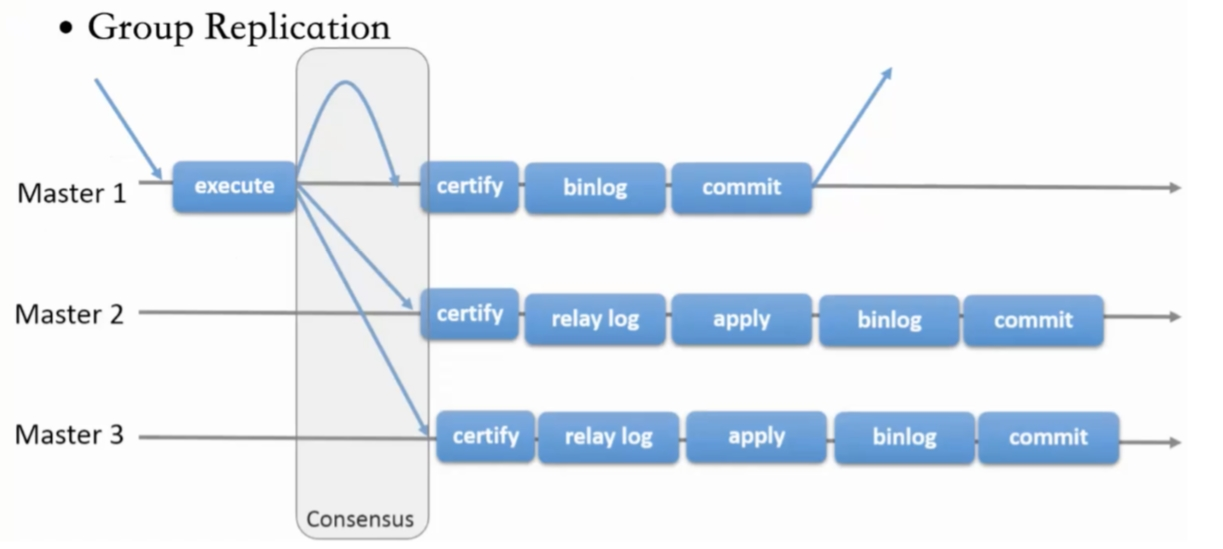
在2N+1个节点组成的单主模式组复制集群中,主库上一个事务提交时,会将事务修改记录相关的信息和 事务产生的BINLOG事件打包生成一个写集(WRITE SET),将写集发送给所有节点,并通过至少N个节 点投票通过才能事务提交成功。
1.事务操作生成的map event/query event/dml event等写入BINLOG CACHE中(内存),将Write Set写入到Rpl_transaction_write_set_ctx中(内存)
2. 在事务提交时,具体在MYSQL_BIN_LOG::prepare之后,但是在 MYSQL_BIN_LOG::ordered_commit之前,即事务相关的BINLOG Event还在BINLOG CACHE没有 写入到BINLOG FILE前,将BINLOG CACHE中和Rpl_transaction_write_set_ctx中的数据进行 处理并写入到transaction_msg中
3. 由gcs_module负责发送transaction_msg到各个节点,等待 各节点进行事务认证。
4. 由于transaction_msg中包含BINLOG信息,并在事务认证期间发送给MGR各节点,因此无需等待主节 点的BINLOG落盘后再发送给备用节点。
每个MGR群集中的节点上,都存在IO线程和SQL线程,IO线程会解析transaction_msg获取到BINLOG EVENT并保存到RELAY LOG中,再由SQL线程执行重放到辅助节点上。
- 事务写⼊binlog前写进MGR层
- 事务消息通过Paxos全局排序后,给MGR节点
- 在各个节点认证(远程与本地事务是否冲突,对⽐事务版本号新旧)
- 认证通过后本地节点写binlog完成提交
- 远程节点写relay-log后并⾏回访
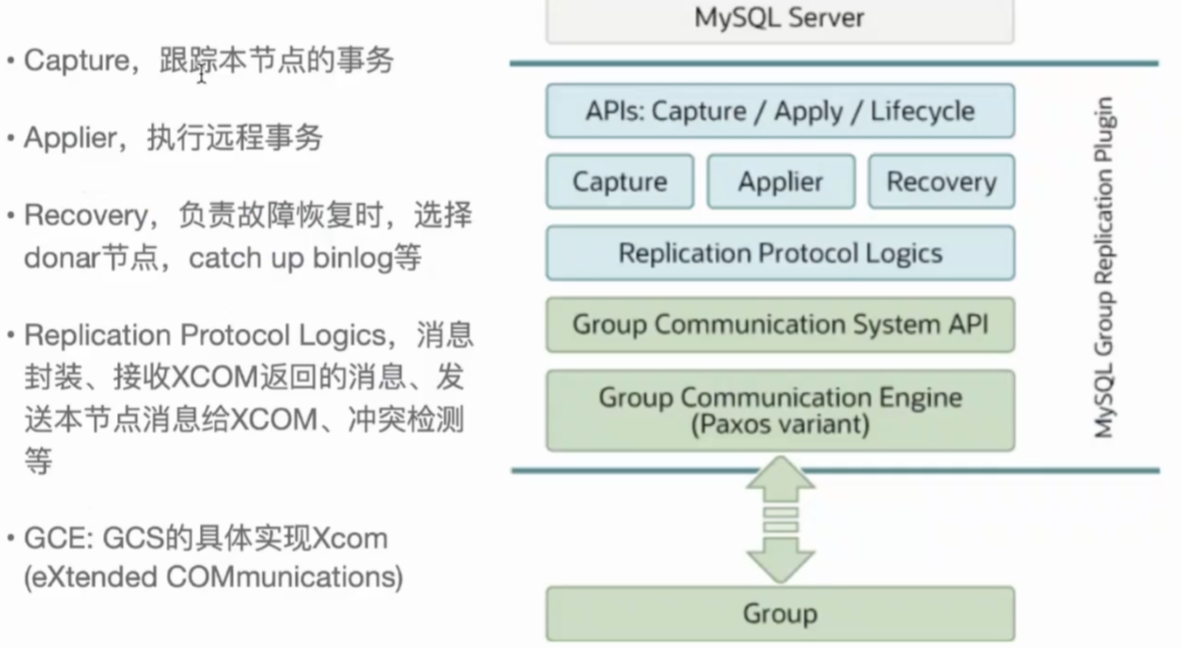
4.2 新成员加⼊
1.新成员加⼊,view change
2.⾃动选择donor节点,分布式恢复
3.从donor节点 clone数据进⾏恢复
4.追加恢复clone发起到结束期间新增事务
5.追加完成,事务达成⼀致后,为online状态
数据恢复
本地恢复
- 故障恢复初始化,包括线程初始化,group成员初始化
- 启动复制通道,先回放d本地relay log.接⼊MGR层新的Paxos消息⼊队到 Xcomcache(参数group_replication_ message_cache_size,默认⼀个G)
MySQL Cluster(MGR)
全局恢复
- 选择donor节点,获取缺失事务
- 处理缓存事务
- 所有事务apply,默认完成
-(参数group_replication_recovery_complete_at)
- TRANSACTIONS_APPLIED 代表本地所有缓存事务回放完毕才能加⼊组进⾏服务
- DISABLE:⽆需本地缓存事务回放完毕加⼊组提供服务
- 通知其他节点,本节点上线 #如果TPS很⼤,cache_size超过则失败. 整体
- 节点加⼊或者重新加⼊集群,补差异数据 - ⾃动选择donor接受事务数据
- ⾃动计算事务差距(参数group_replication_clone_threshold)
- 差异少 binlog
- 差异⼤ clone
- ⾃动尝试 retyr_count次
- 完成标记 group_replication_recovery_complete_at #阈值定义group_replication_clone_threshold
- 事务差异未超过,binlog
- 需要事务不存在,使⽤clone
- 两端都要启动clone,且具有backup权限


· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现