MGR架构测试
1.测试节点
节点一、10.2.83.133 (primary)
节点二、10.2.83.140(second)
节点三、10.2.83.141(second)
2.测试情形--单主
2.1 关闭防火墙
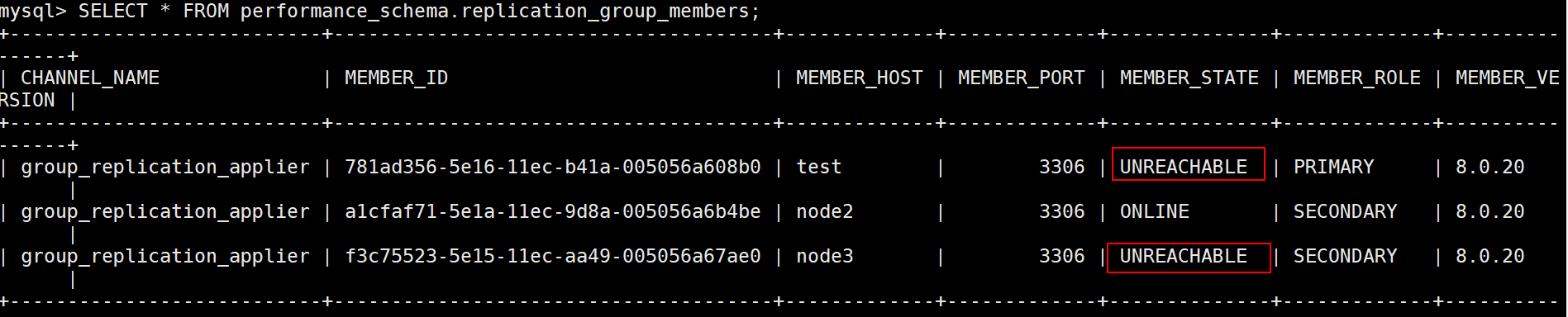
10.2.83.140节点开启防火墙
可以测试到该节点变为unreachable,当关闭防火墙,无法立刻加入集群,等了不知道多久自己恢复了,还需要再测试
日志报错

在开启防火墙的状态进行start GROUP_REPLICATION; 日志报错如下

2.2 关掉节点二、三确认只有单节点一是否可以使用(正常的关闭数据库, 或者执行了start group_replication)
节点一写存储过程,不停向节点一insert数据
如下insert存储过程
BEGIN
DECLARE num int ;
set num=1;
while num <10000000 DO
insert into t1 (name) values ('test1_t1_malong56');
set num=num+1;
end while;
END
调用存储过程
call proc_t1
节点二、三执行: systemctl stop mysqld
1>> 确认只有节点一可以正常读写。符合MGR允许最大故障数:f=(n-1)/2 三台只要一台存活就可以继续访问
2>> 节点二三重新启动, systemctl start mysqld ,执行start group_replication;
可以发现状态为:recovering
group_replication_applier | a1cfaf71-5e1a-11ec-9d8a-005056a6b4be | node2 | 3306 | RECOVERING | SECONDARY | 8.0.20
查看有多少事务等待恢复,即确认主从延迟,说明有28692个事物等待同步,待变为online就为正常了
mysql> select COUNT_TRANSACTIONS_IN_QUEUE,LAST_CONFLICT_FREE_TRANSACTION from performance_schema.replication_group_member_stats where MEMBER_ID=@@server_uuid;
+-----------------------------+--------------------------------+
| COUNT_TRANSACTIONS_IN_QUEUE | LAST_CONFLICT_FREE_TRANSACTION |
+-----------------------------+--------------------------------+
| 28692 | |
+-----------------------------+--------------------------------+
2.3 当服务器异常宕机或者数据库由于oom等异常退出,网络断线等
两个节点可以正常读写
一个节点就会变为只读
2.4 测试关掉节点一,primary节点是否可以正常切换
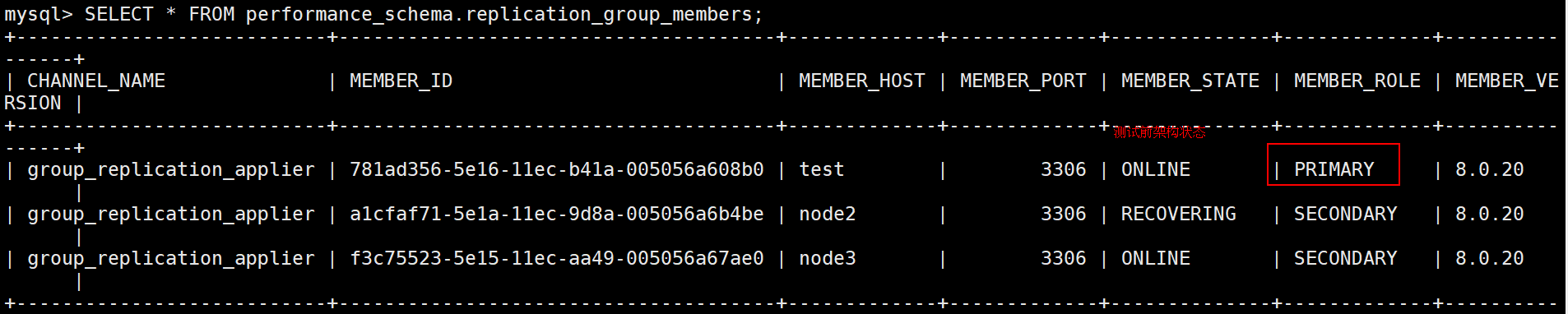
1>> 节点一执行: systemctl stop mysqld
确认:primary节点切换到了节点三

2>> 原来的节点一重新启动,
systemctl start mysqld ,执行start group_replication;
可以发现状态为:recovering,且角色为:SECONDARY
2.4 加入脱离组
2.4.1 已有数据节点加入组
1>> 如果新增节点A落后数据很少,可以直接 START GROUP_REPLICATION; 加入组
2>> 如果新增节点A落后数据很多,则需要先选择任意一个组内节点作为master开启复制
CHANGE MASTER TO MASTER_HOST='ip',MASTER_PORT=port,MASTER_USER='replication',MASTER_PASSWORD='***',MASTER_AUTO_POSITION=1;
追上后直接START GROUP_REPLICATION; 加入组
3>> 查看是否成功加入组
SELECT * FROM performance_schema.replication_group_members\G;
查看 MEMBER_STATE 值是否为 ONLINE
2.4.2 通过备份加入组
场景:全新新节点加入,通过异步复制的方式先把数据导入再加入集群
步骤1:在主节点进行全备(也可以采用xbk备份)
mysqldump -uroot -p'1qaz@WSX' -S /flex/mysql/data/mysql3306/tmp/mysql.sock --single-transaction --triggers --set-gtid-purged=OFF --routines --events --master-data=2 -A |gzip > /tmp/all.sql.gz
步骤2:从节点建立数据库,并把其他second节点的配置文件复制一份到新建的库,启动服务器
建库步骤略
步骤3:新建从节点导入数据
source /tmp/all.sql
步骤4:加入集群
set sql_log_bin=0;
reset master;
set global super_read_only=0;
set global read_only=0;
create user 'rpl_mgr'@'%' identified by '123456';
grant replication slave on *.* to 'rpl_mgr'@'%';
ALTER USER rpl_mgr@'%' IDENTIFIED WITH mysql_native_password BY '123456';
set sql_log_bin=1;
change master to master_user='rpl_mgr', master_password='123456' for channel 'group_replication_recovery';
install plugin group_replication soname 'group_replication.so';
show plugins;
set global slave_preserve_commit_order=on;
start group_replication;
SELECT * FROM performance_schema.replication_group_members\G;
2.4.3 通过组复制克隆来进行加入集群(测试下来速度较快)
场景:全新新节点加入,通过异步复制的方式先把数据导入再加入集群
步骤1:从节点建立数据库,并把其他second节点的配置文件复制一份到新建的库,启动服务器
建库步骤略
步骤2:贡献者端执行(10.2.83.133):
CREATE USER 'donor_clone_user'@'%' IDENTIFIED BY '123456';
GRANT BACKUP_ADMIN on *.* to 'donor_clone_user'@'%';
INSTALL PLUGIN clone SONAME 'mysql_clone.so';
3.接收者端执行(10.2.83.141):
CREATE USER 'recipient_clone_user'@'%' IDENTIFIED BY '123456';
GRANT CLONE_ADMIN on *.* to 'recipient_clone_user'@'%';
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
INSTALL PLUGIN clone SONAME 'mysql_clone.so';
SET GLOBAL clone_valid_donor_list = '10.2.83.133:3306';
mysql -urecipient_clone_user -p123456 -h 10.2.83.141
CLONE INSTANCE FROM 'donor_clone_user'@'10.2.83.133':3306 IDENTIFIED BY '123456';
加入组复制:
mysql> START GROUP_REPLICATION;
mysql> select * from performance_schema.replication_group_members; 查看集群状态
