
Python爬虫(二)【“新浪科技”爬虫】
一、MySQL
1、登陆MySQL
mysql -u root -p
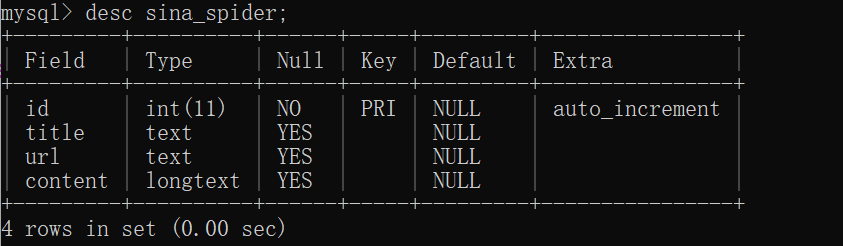
2、新建数据库、表
mysql> CREATE DATABASE sina_spider CHARACTER SET utf8;
mysql> use sina_spider
Database changed
mysql> create table if not exists sina_spider(
-> id integer primary key AUTO_INCREMENT,
-> title text,
-> url text,
-> content LONGTEXT
-> )CHARACTER SET utf8 COLLATE utf8_unicode_ci;
二、Python(PyCharm)编写爬虫
注:1、由于一些兼容问题,这里选择Python2,要在PyCharm中装Python2.7
2、可能需要安装BeautifulSoup等Module ,提示如下:
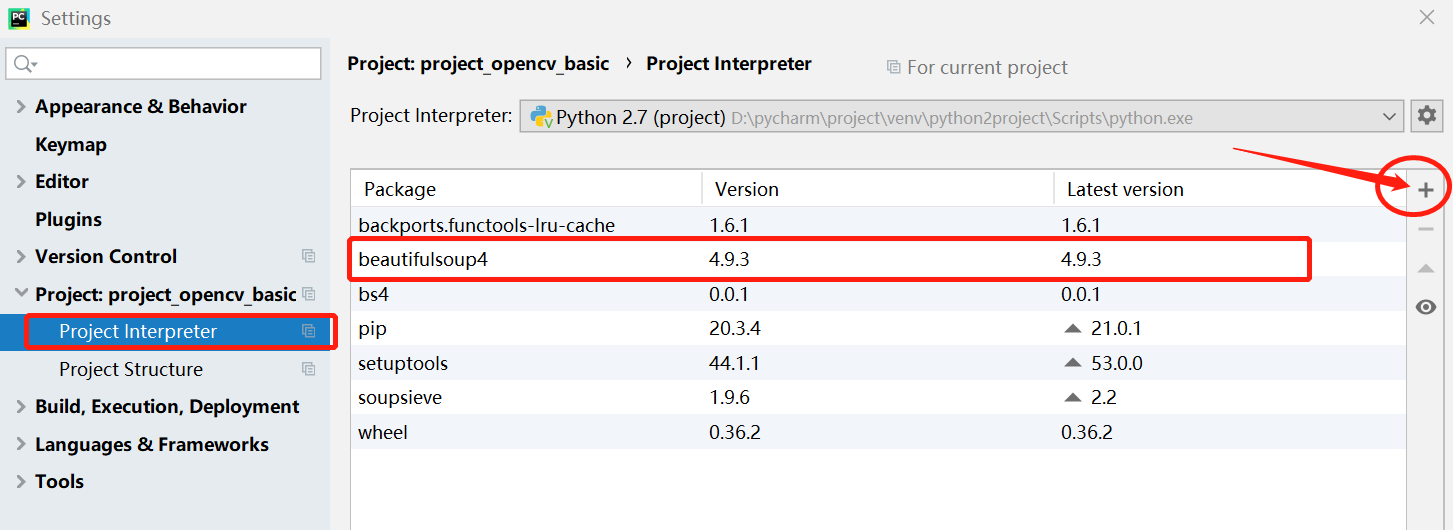
点击“+”之后搜索缺失的Module后选择下载源下载即可,然后就能看到下载好的Mudule了。
3、对于不能采用上面方式下载的情况,可以使用pip install 要下载的模块名字,
备注:如果有多个版本的python,Windows切换默认Python版本,可以通过移动不同版本Python的环境变量的所在位置(先后顺序),
较前位置的版本就会变成默认的版本。
4、如果pip还是安装不上,就下载对应的源文件放到对应Python版本的文件夹下,然后再进入cmd,
将当前目录转换到源文件的所在位置,最后再pip install 安装即可。
Python实现代码:
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup as bs import urllib2 import MySQLdb from sqlalchemy import create_engine import Queue import pandas as pd # 一、构造request请求、解析当前URL获取信息 def getLinks(targetURL): #也可能会出现网络超时、连接非法等异常 try: # 1)构造request请求 req = urllib2.Request(targetURL) # 2)标识浏览器的环境,来告诉服务器这是一个真实的运行环境 userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36" # 3)将userAgent传入构建的req请求中 req.add_header('User-Agent', userAgent) # 4)访问网页(设置超时的时间是30毫秒) resp = urllib2.urlopen(req, timeout=30).read() # 5)因为一些内容会出现乱码,所以需要进行解码, # 能正常解码的用'utf-8';不能正常解码的用'replace'进行替换 html = resp.decode('utf-8', 'replace') # 6)定义新的变量,调用自定义方法解析网页 title, ilinks = get_title_links(html) except Exception, e: print "getLinks", e return None, None, None return title, ilinks, html #二、根据返回的标签 解析到网页的地址和标题 def get_title_links(html): try: #1)使用BeautifulSoup soup = bs(html, fromEncoding='utf-8') #2)获取标题、超链接网址 title = soup.title.string.encode('utf-8') links = soup.find_all('a') #判断超链接是否在/a的标签里面 linksHandle1 = [] for l in links: if 'href' in l.attrs and 'http' in l['href']: linksHandle1.append(l['href']) except Exception, e: #输出异常的日志 print "get_title_links",e return None, None #返回当前网页的标题,以及去重后的当前网页的其它关联网页 return title,set(linksHandle1) #三、数据存储,对初始的URL进行持久化(当前网页的标题、地址、内容) def saveDB(title, url, html): try: #1)获取MySQL的链接 create_engine("mysql://root:123456@localhost/sina_spider?charset=utf8mb4") #2)封装数据,利用数据库函数-DataFrame()构造出DataFrame,从而对数据进行保存 data = pd.DataFrame([{'title': title, 'url': url, 'content': html}]) #3)传入数据库信息: 需要的插入数据的数据库、数据表、如果表已经存在就追加内容、不需要将index信息存到数据库中。 data.to_sql("sina_spider", engine, if_exists="append", index=False) except Exception, e: print "saveDB error",e #四、入队操作 def addQueue(links, urlQueue, visited): #1)判断相关联的网页是否为空 if links is None: #如果为空,就直接返回当前队列以及访问过的队列集合 return urlQueue, visitedURL #2)如果不为空,还有相关联的网页 for i in links: #如果当前URL没有被访问过 if i not in visitedURL: #将当前的URL入队(加到队尾) urlQueue.put(i) #放入已访问过的URL队列中,防止再次加入到URL队列中 visitedURL.add(i) #返回当前队列、访问过的URL集合 return urlQueue, visitedURL if __name__ == "__main__": #1、定义一个初始的URL targetURL = "https://tech.sina.com.cn/" #2、发起request请求、获取当前网页的标题、所有相关联的其他网页、HTML-内容 title, allLinks, html = getLinks(targetURL) #3、数据存储,对初始的URL进行持久化 saveDB(title, targetURL, html) #4、维护一个URL队列,队头不断地出队 q = Queue.Queue() #定义一个已访问过的URL集合 visitedURL = set() #将初始的URL放入已访问过的集合中 visitedURL.add(targetURL) #入队操作(传入所有和当前网页相关的其他网页、当前的队列、访问过的URL集合) q, visitedURL = addQueue(allLinks, q, visitedURL) #当URL队列不为空,就不断地出队取URL并进行入队操作 while q.qsize() > 0 and q is not None: targetURL = q.get() #打印出当前URL队列的大小 print "queue size:", q.qsize() #再次提出request请求、获取当前网页的标题、所有相关联的其他网页、HTML-内容 title, allLinks, html = getLinks(targetURL) #再次保存数据 saveDB(title, allLinks, html) #再次入队操作 q, visitedURL = addQueue(allLinks, q, visitedURL)
三、Scrapy框架
Scrapy中有很多已经封装好的爬虫框架(像上面的代码例子),可以直接使用或学习。
四、绕开登陆
1、Cookie
将浏览器的Cookie复制下来,像userAgent一样放入请求当中即可。
2、OCR验证码识别
OCR的效率较低,相对较麻烦。通用的爬虫经常会用到,它可以调用第三方的服务。
五、爬虫效率
可用多线程、分布式的形式加快效率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号