
Spark 2.x管理与开发-Spark Core-Spark的算子(四)RDD的特性(1)RDD的缓存机制
Posted on 2020-07-12 10:11 MissRong 阅读(107) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark的算子(四)RDD的特性(1)RDD的缓存机制
RDD的缓存机制默认将RDD的数据缓存在内存中
(1)作用:提高性能
(2)使用:persist或者cache函数标识RDD可以被缓存
cache方法本质调用了persist

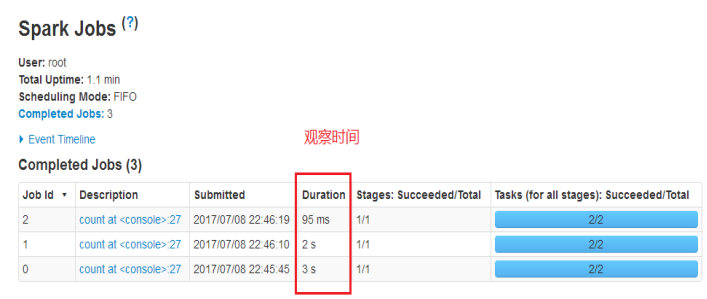
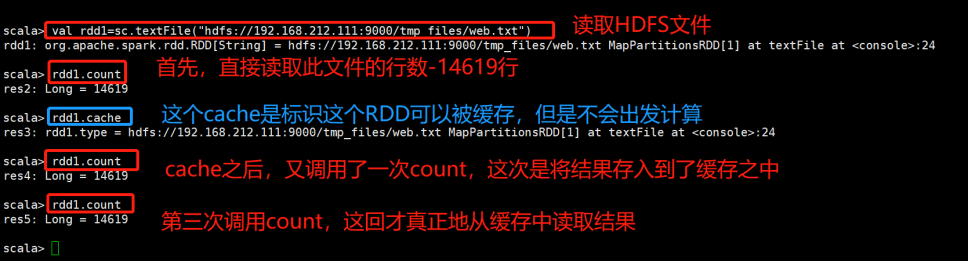
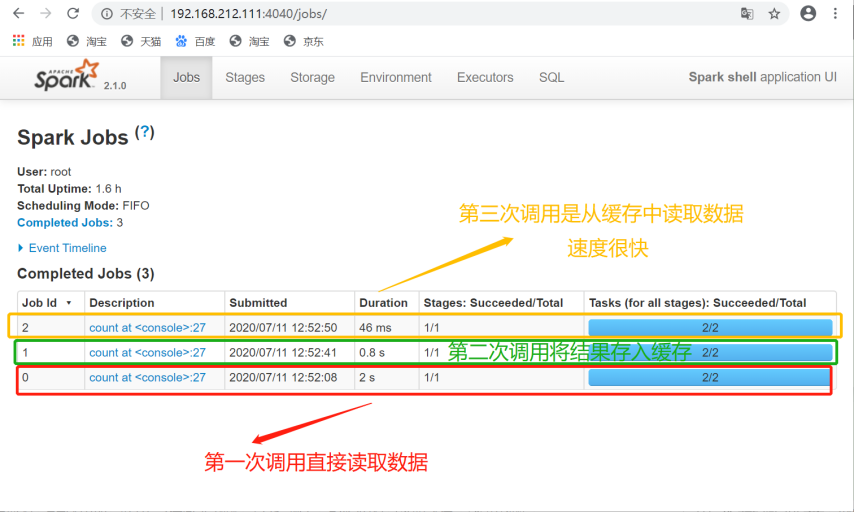
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。

通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。
https://spark.apache.org/docs/2.1.0/api/scala/#org.apache.spark.storage.StorageLevel$

DISK_ONLY:缓存在硬盘
MEMORY_ONLY:存在内存
MEMORY_ONLY_2:存在内存(新版的)
MEMORY_ONLY_SER:存在内存,以序列化的形式(减少所占内存的大小)
MEMORY_ONLY_SER_2:和上面一行的相比是新版的(推荐使用这个)
一般不会修改参数,使用默认值就好
——————————————————————————————
缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。
通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
Demo示例:

通过UI进行监控:
****************自己测试****************
启动Spark伪分布式、Zookeeper、HDFS
[root@bigdata111 ~]# cd /usr/local/spark-2.1.0-bin-hadoop2.7/sbin/
[root@bigdata111 sbin]# ./start-all.sh
[root@bigdata111 ~]# cd /usr/local/spark-2.1.0-bin-hadoop2.7/bin/
[root@bigdata111 bin]# ./spark-shell --master spark://bigdata111:7077
[root@bigdata111 sbin]# cd /
[root@bigdata111 /]# zkServer.sh start
[root@bigdata111 /]# start-dfs.sh
这里可以先不启动Yarn
输入Scala命令行:
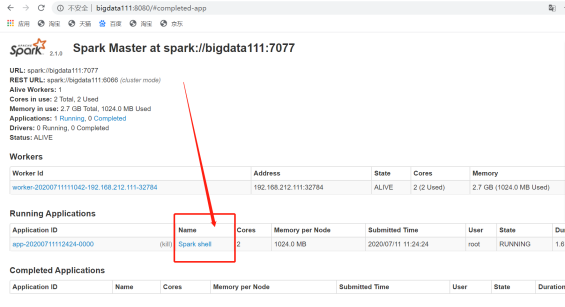
接下来查看Spark可视化界面:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号