k8s组件之etcd(1)
etcd 是基于 raft算法的分布式键值数据库,生来就为集群化而设计的。
比较好的操作:
alias etcdctl='etcdctl --endpoints=https://10.20.16.227:2379,https://10.20.16.228:2379,https://10.20.16.229:2379 --cacert=/data/cloud/ssl/ca.pem --cert=/data/cloud/ssl/etcd.pem --key=/data/cloud/ssl/etcd-key.pem'一、总体结构
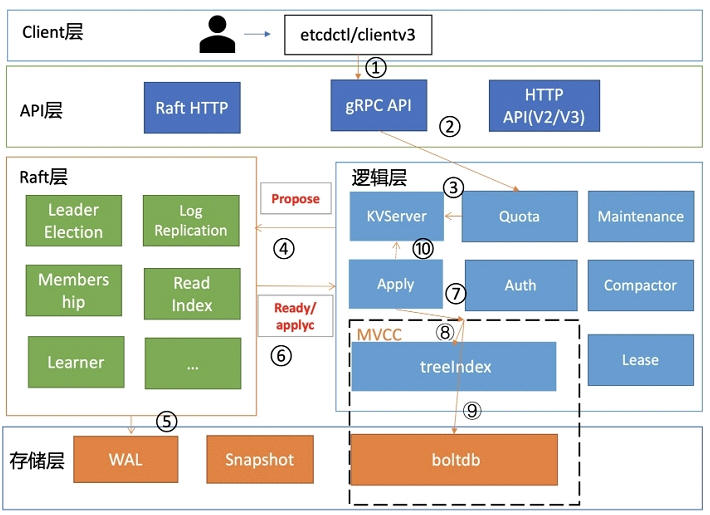
Raft层:协议保证数据的一致性和高可用;
API层:(在etcd3里面变成了grpc server),主要处理client的操作请求以及节点间的数据同步和心跳保持
逻辑层:负责etcd中事务操作的逻辑,是api server的命令的具体实现
存储层:负责具体的数据持久存储操作。它分为两部分,entry 负责实际的日志数据存储。snapshot 则是对日志数据的状态存储以防止过多的数据存在。
二、etcd接口
etcd 提供的接口,分为了 5 组:
第一组是Put与Delete。put与delete的操作都非常简单,只需要提供一个 key 和一个 value,就可以向集群中写入数据了,删除数据的时候只需要指定 key 即可;
第二组是查询操作。etcd 支持两种类型的查询:第一种是指定单个 key 的查询,第二种是指定的一个 key 的范围;
第三组是数据订阅。etcd 提供了Watch机制,我们可以利用watch实时订阅到etcd中增量的数据更新,watch支持指定单个key,也可以指定一个key的前缀,在实际应用场景中的通常会采用第二种形势;
第四组事务操作。etcd 提供了一个简单的事务支持,用户可以通过指定一组条件满足时执行某些动作,当条件不成立的时候执行另一组操作,类似于代码中的if else语句,etcd 确保整个操作的原子性;
第五组是Leases接口。Leases接口是分布式系统中常用的一种设计模式,其用法后面会具体展开。
二、etcd选主过程
raft算法需要半数以上投票才能有 leader。偶数节点虽然多了一台机器,但是容错能力是一样的,也就是说,设置偶数节点,没增加什么能力,还浪费了一台机器。同时etcd 是通过复制数据给所有节点来达到一致性,因此偶数的多一台机器增加不了性能,反而会拉低写入速度。
etcd 是高可用的,允许部分机器故障,以标准的3 节点etcd 集群,最大容忍1台机器宕机,下面以最简单的leader宕机来演示raft 的投票逻辑,以实际的运行日志来验证并理解。
场景:正常运行的三台etcd:100、101、102。当前任期为 7,leader 为 101机器。现在使101 宕机。宕机前:101为 leader,3个member。宕机后:102 成为新 leader,2 个 member
过程:
将 101 机器的 etcd 停止,此时只剩 2 台,但总数为 3
101停止etcd 的运行
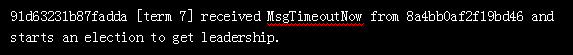
102(91d63231b87fadda) 收到消息,发现101(8a4bb0af2f19bd46)心跳超时,于是发起了新一轮选举,任期为 7+1=8
102(91d63231b87fadda)成为新一任的候选人,然后自己投给了自己,获得 1 票

102(91d63231b87fadda)发送给 挂掉的101 和 另一个100,希望他们也投给自己


100 (9feab580a25dd270)收到了 102 的拉票消息,因为任期 8 大于当前100机器所处的 7,于是知道是发起了新的一轮选举,因此回应 101,我给你投票。这里任期term是关键,也就是说,100 和 102 谁先感受到 101 宕机,发起投票,谁就是新的 leader,这个也和进程初始的启动时间有关。102 肯定收不到 101 的回应,因为 101 已经挂掉
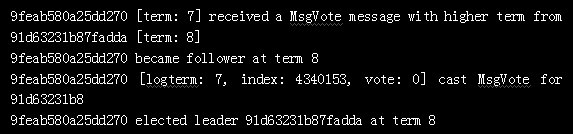
91d63231b87fadda elected leader 91d63231b87fadda at term 8102 获得了 2 票,一票是自己,一票是 100,超过半数,成为新的 leader。任期为 8
三、etcd 是强一致性
etcd是强一致性,读和写都可以保证线性一致
线性一致性读需要在所有节点走一遍确认,查询速度会有所降低,要开启线性一致性读,在不同的 client是有所区别的:v2 版本:通过 sdk访问时,quorum=true 的时候读取是线性一致的,通过etcdctl访问时,该参数默认为true。v3 版本:通过 sdk访问时,WithSerializable=true 的时候读取是线性一致的,通过etcdctl访问时consistency=“l”表示线性(默认为 l,非线性为 s)
为了保证线性一致性读,早期的 etcd(_etcd v3.0 _)对所有的读写请求都会走一遍 Raft 协议来满足强一致性。然而通常在现实使用中,读请求占了 etcd 所有请求中的绝大部分,如果每次读请求都要走一遍 raft 协议落盘,etcd 性能将非常差。
因此在 etcd v3.1 版本中优化了读请求(PR#6275),使用的方法满足一个简单的策略:每次读操作时记录此时集群的 commit index,当状态机的 apply index 大于或者等于 commit index 时即可返回数据。由于此时状态机已经把读请求所要读的 commit index 对应的日志进行了 apply 操作,符合线性一致读的要求,便可返回此时读到的结果。
四、etcd 常见问题
4.1 修复etcd数据
一个节点宕机,并不会影响整个集群的正常工作,可以修复。
(1) 移出该节点:etcdctl member remove xx(可以通过member list获取XX)
(2) 停止etcd服务
(3) 需要将配置中的 cluster_state改为:existing,因为是加入已有集群,不能用 new
修复机器问题,删除旧的数据目录,重新启动 etcd 服务
(4) 加入 memeber: etcdctl member add xxx –peer-urls=https://x.x.x.x:2380
(5) 重启服务
(6) 验证:etcdctl endpoint status
4.2 迁移数据
使用 etcdctl snapshot save 来保存现有数据,新集群更换后,使用 restore 命令恢复数据,在执行快照时会产生一个 hash 值,来标记快照内容后面恢复时用于校验,如果你是直接复制的数据文件,可以–skip-hash-check 跳过这个检查。
etcdctl save etcd-data-20171002-2.snapshot
etcdctl snapshot restore ./etcd-data-20171002-2.snapshot --data-dir=/var/lib/etcd/etcd.node1.etcd(这里的路径一定要对)
4.3通过证书访问etcd
etcdctl --endpoints https://node1:2379,https://node2:2379,https://node3:2379 endpoint status --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd-server.pem --key=/etc/kubernetes/ssl/etcd-server.key
4.4 etcd获取数据
export ETCDCTL_API=3
etcdctl get / --keys-only --prefix
etcdctl get ** --prefix
etcd在arm环境下启动需要写环境变量: export ETCD_UNSUPPORTED_ARCH=arm64;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号